
Wenn ein Unternehmen einen neuen KI-Videogenerator auf den Markt bringt, dauert es nicht lange, bis jemand damit ein Video erstellt, in dem der Schauspieler Will Smith Spaghetti isst.
Es ist so etwas wie ein Meme und ein Maßstab geworden: Zu sehen, ob ein neuer Videogenerator Smith realistisch darstellen kann, wie er eine Schüssel Nudeln schlürft. Smith selbst parodiert den Trend in einem Instagram-Post im Februar.
Google Veo 2 hat es geschafft.
Jetzt essen wir endlich Spaghetti. pic.twitter.com/AZO81w8JC0
– Jerrod Lew (@jerrod_lew) 17. Dezember 2024
Will Smith und Pasta sind nur einer von mehreren bizarren „inoffiziellen“ Maßstäben, die die KI-Community im Jahr 2024 im Sturm erobern werden. Ein 16-jähriger Entwickler hat eine App entwickelt, die der KI die Kontrolle über Minecraft gibt und ihre Fähigkeit, Strukturen zu entwerfen, testet. An anderer Stelle hat ein britischer Programmierer eine Plattform geschaffen, auf der KI Spiele wie Pictionary und Connect 4 gegeneinander spielt.
Es ist nicht so, dass es nicht mehr akademische Tests zur Leistung einer KI gibt. Warum explodierten die seltsameren Exemplare?
Zum einen sagen viele der branchenüblichen KI-Benchmarks dem Durchschnittsbürger nicht viel. Unternehmen berufen sich häufig auf die Fähigkeit ihrer KI, Fragen bei Mathematikolympiade-Prüfungen zu beantworten oder plausible Lösungen für Probleme auf Doktorandenniveau zu finden. Doch die meisten Menschen – Sie wirklich eingeschlossen – nutzen Chatbots für Dinge wie Beantwortung von E-Mails und Grundlagenrecherche.
Crowdsourcing-Branchenkennzahlen sind nicht unbedingt besser oder aussagekräftiger.
Nehmen wir zum Beispiel Chatbot Arena, einen öffentlichen Benchmark, dem viele KI-Enthusiasten und Entwickler wie besessen folgen. Mit der Chatbot Arena kann jeder im Web bewerten, wie gut die KI bei bestimmten Aufgaben abschneidet, etwa beim Erstellen einer Web-App oder beim Generieren eines Bildes. Aber Bewerter sind in der Regel nicht repräsentativ – die meisten kommen aus Kreisen der KI- und Technologiebranche – und geben ihre Stimme auf der Grundlage persönlicher, schwer zu bestimmender Präferenzen ab.
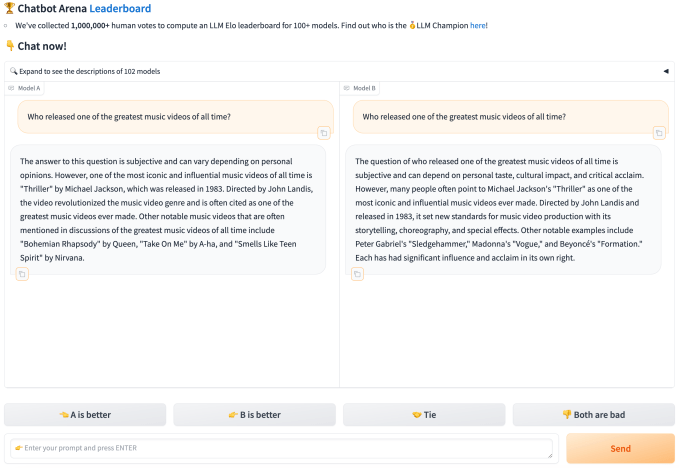
Ethan Mollick, Professor für Management an der Wharton University, wies kürzlich in einem Artikel darauf hin Post auf X ein weiteres Problem bei vielen Benchmarks der KI-Branche: Sie vergleichen die Leistung eines Systems nicht mit der einer durchschnittlichen Person.
„Die Tatsache, dass es nicht 30 verschiedene Benchmarks von verschiedenen Organisationen in der Medizin, im Recht, in der Beratungsqualität usw. gibt, ist wirklich schade, da die Leute unabhängig davon Systeme für diese Dinge verwenden“, schrieb Mollick.
Seltsame KI-Benchmarks wie Connect 4, Minecraft und Will Smith, der Spaghetti isst, sind das mit Sicherheit nicht empirisch – oder sogar alles verallgemeinerbar. Nur weil eine KI den Will-Smith-Test besteht, heißt das nicht, dass sie beispielsweise einen Burger-Brunnen erzeugt.
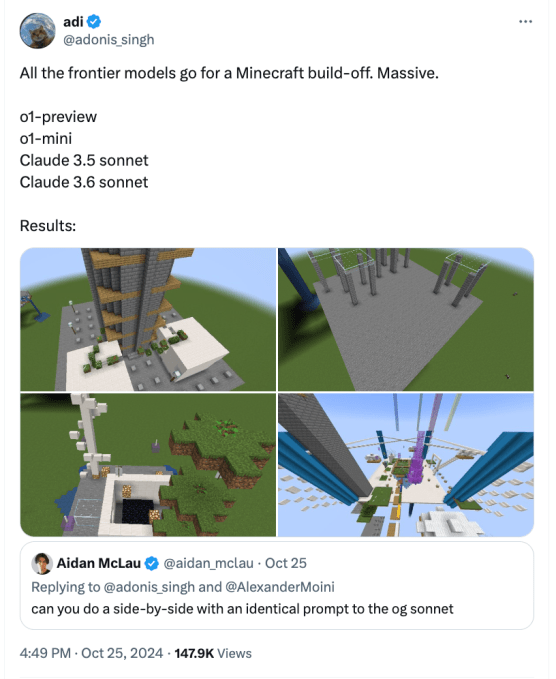
Ein Experte, mit dem ich über KI-Benchmarks gesprochen habe, schlug vor, dass sich die KI-Community auf die nachgelagerten Auswirkungen der KI konzentrieren sollte und nicht auf ihre Fähigkeiten in engen Bereichen. Das ist vernünftig. Aber ich habe das Gefühl, dass seltsame Benchmarks nicht so schnell verschwinden werden. Sie sind nicht nur unterhaltsam – wer sieht nicht gerne zu, wie KI Minecraft-Burgen baut? – aber sie sind leicht zu verstehen. Und wie mein Kollege Max Zeff kürzlich schrieb, kämpft die Branche weiterhin damit, eine so komplexe Technologie wie KI in verdauliches Marketing umzuwandeln.
Die einzige Frage, die mir durch den Kopf geht, ist: Welche seltsamen neuen Benchmarks werden im Jahr 2025 viral gehen?