
Benchmarks sind ein ebenso wichtiges Maß für den Fortschritt in der KI wie für den Rest der Softwarebranche. Aber wenn die Benchmark-Ergebnisse von Unternehmen stammen, hindert die Geheimhaltung die Gemeinschaft sehr oft daran, sie zu überprüfen.
Beispielsweise gewährte OpenAI Microsoft, mit dem es eine Geschäftsbeziehung unterhält, die exklusiven Lizenzrechte an seinem leistungsstarken GPT-3-Sprachmodell. Andere Organisationen sagen, dass der Code, den sie zur Entwicklung von Systemen verwenden, von internen Tools und Infrastrukturen abhängt, die nicht freigegeben werden können, oder dass urheberrechtlich geschützte Datensätze verwendet werden. Während Motivationen kann ethischer Natur sein – OpenAI lehnte es zunächst ab, GPT-2, den Vorgänger von GPT-3, aus Bedenken, dass es missbraucht werden könnte, herauszugeben – denn die Wirkung ist die gleiche. Ohne den erforderlichen Code ist es für externe Forscher viel schwieriger, die Behauptungen einer Organisation zu überprüfen.
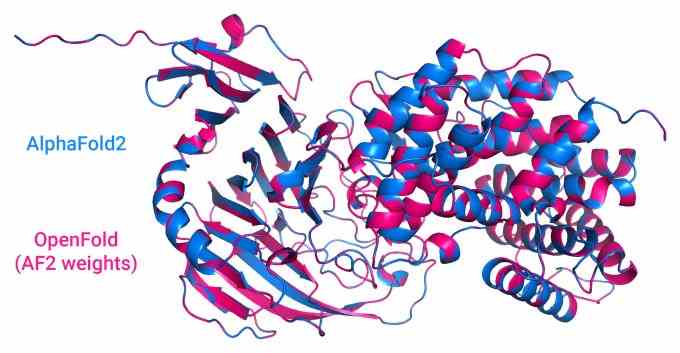
„Dies ist nicht wirklich eine ausreichende Alternative zu bewährten Open-Source-Praktiken der Branche“, hat Columbia Computer Science Ph.D. Kandidat Gustaf Ahdritz teilte Tech per E-Mail mit. Ahdritz ist einer der führenden Entwickler von OpenFold, einer Open-Source-Version von DeepMinds AlphaFold 2 zur Vorhersage der Proteinstruktur.
Einige Forscher gehen sogar so weit zu sagen, dass das Zurückhalten des Codes eines Systems „seinen wissenschaftlichen Wert untergräbt“. Im Oktober 2020 eine Widerlegung veröffentlicht im Tagebuch Natur hatte ein Problem mit einem Krebsvorhersagesystem, das von Google Health trainiert wurde, dem Zweig von Google, der sich auf gesundheitsbezogene Forschung konzentriert. Die Co-Autoren stellten fest, dass Google wichtige technische Details zurückhielt, einschließlich einer Beschreibung der Entwicklung des Systems, was seine Leistung erheblich beeinträchtigen könnte.
Bildnachweis: OpenFold
Anstelle von Veränderungen haben es sich einige Mitglieder der KI-Community, wie Ahdritz, zur Aufgabe gemacht, die Systeme selbst als Open Source zu veröffentlichen. Ausgehend von technischen Dokumenten versuchen diese Forscher akribisch, die Systeme neu zu erstellen, entweder von Grund auf neu oder aufbauend auf den Fragmenten öffentlich verfügbarer Spezifikationen.
OpenFold ist eine solche Anstrengung. Kurz nach der Ankündigung von AlphaFold 2 durch DeepMind begonnen, soll laut Ahdritz überprüft werden, ob AlphaFold 2 von Grund auf reproduziert werden kann, und Komponenten des Systems verfügbar gemacht werden, die an anderer Stelle nützlich sein könnten.
„Wir vertrauen darauf, dass DeepMind alle notwendigen Details bereitgestellt hat, aber … haben wir nicht [concrete] Beweis dafür, und daher ist diese Anstrengung der Schlüssel, um diesen Weg bereitzustellen und anderen zu ermöglichen, darauf aufzubauen“, sagte Ahdritz. „Außerdem standen ursprünglich bestimmte AlphaFold-Komponenten unter einer nichtkommerziellen Lizenz. Unsere Komponenten und Daten – DeepMind hat noch immer nicht ihre vollständigen Trainingsdaten veröffentlicht – werden vollständig Open Source sein, um die Übernahme in die Industrie zu ermöglichen.“
OpenFold ist nicht das einzige Projekt dieser Art. An anderer Stelle versuchen lose verbundene Gruppen innerhalb der KI-Community Implementierungen von OpenAIs codegenerierendem Codex und kunstschaffendem DALL-E, DeepMinds schachspielendem AlphaZero und sogar AlphaStar, einem DeepMind-System, das entwickelt wurde, um das Echtzeit-Strategiespiel StarCraft zu spielen 2. Zu den erfolgreicheren gehören EleutherAI und das KI-Startup Hugging Face’s BigScienceoffene Forschungsanstrengungen, die darauf abzielen, den Code und die Datensätze bereitzustellen, die zum Ausführen eines mit GPT-3 vergleichbaren (wenn auch nicht identischen) Modells erforderlich sind.
Philip Wang, ein produktives Mitglied der KI-Gemeinschaft, der dies unterhält eine Reihe von Open-Source-Implementierungen auf GitHub, einschließlich eines DALL-E von OpenAI, postuliert, dass das Open-Sourcing dieser Systeme die Notwendigkeit für Forscher reduziert, ihre Bemühungen zu duplizieren.
„Wir lesen die neuesten KI-Studien, wie jeder andere Forscher auf der Welt. Aber anstatt das Papier in einem Silo zu replizieren, implementieren wir es Open Source“, sagte Wang. „Wir befinden uns an einem interessanten Ort an der Schnittstelle von Informationswissenschaft und Industrie. Ich denke, Open Source ist nicht einseitig und nützt am Ende allen. Es appelliert auch an die umfassendere Vision einer wirklich demokratisierten KI, die nicht den Aktionären verpflichtet ist.“
Brian Lee und Andrew Jackson, zwei Google-Mitarbeiter, arbeiteten bei der Erstellung zusammen MiniGo, eine Replikation von AlphaZero. Obwohl sie nicht mit dem offiziellen Projekt verbunden sind, hatten Lee und Jackson – die bei Google, der ursprünglichen Muttergesellschaft von DeepMind – waren, den Vorteil, Zugang zu bestimmten proprietären Ressourcen zu haben.
Bildnachweis: MiniGo
„[Working backward from papers is] wie das Navigieren, bevor wir GPS hatten“, sagte Lee, ein Forschungsingenieur bei Google Brain, per E-Mail zu Tech. „Die Anweisungen sprechen von Orientierungspunkten, die Sie sehen sollten, wie lange Sie in eine bestimmte Richtung gehen sollten, welche Abzweigung Sie an einem kritischen Punkt nehmen sollten. Es gibt genug Details für den erfahrenen Navigator, um sich zurechtzufinden, aber wenn Sie nicht wissen, wie man einen Kompass liest, sind Sie hoffnungslos verloren. Du wirst die Schritte nicht genau zurückverfolgen, aber du wirst am selben Ort landen.“
Die Entwickler hinter diesen Initiativen, einschließlich Ahdritz und Jackson, sagen, dass sie nicht nur dazu beitragen werden, zu demonstrieren, ob die Systeme wie angekündigt funktionieren, sondern auch neue Anwendungen und eine bessere Hardwareunterstützung ermöglichen. Systeme von großen Labors und Unternehmen wie DeepMind, OpenAI, Microsoft, Amazon und Meta werden in der Regel auf teuren, proprietären Rechenzentrumsservern mit weitaus mehr Rechenleistung als die durchschnittliche Workstation trainiert, was die Hürden für Open Source noch erhöht.
„Das Training neuer Varianten von AlphaFold könnte zu neuen Anwendungen führen, die über die Vorhersage der Proteinstruktur hinausgehen, was mit der ursprünglichen Codeversion von DeepMind nicht möglich ist, da der Trainingscode fehlte – zum Beispiel die Vorhersage, wie Medikamente Proteine binden, wie sich Proteine bewegen und wie Proteine miteinander interagieren andere Biomoleküle“, sagte Ahdritz. „Es gibt Dutzende von hochwirksamen Anwendungen, die das Training neuer Varianten von AlphaFold oder die Integration von Teilen von AlphaFold in größere Modelle erfordern, aber der Mangel an Trainingscode verhindert all dies.“
„Diese Open-Source-Bemühungen tragen viel dazu bei, das „Arbeitswissen“ darüber zu verbreiten, wie sich diese Systeme in nicht-akademischen Umgebungen verhalten können“, fügte Jackson hinzu. „Der Rechenaufwand, der erforderlich ist, um die ursprünglichen Ergebnisse zu reproduzieren [for AlphaZero] ist ziemlich hoch. Ich kann mich nicht an die Zahl aus dem Kopf erinnern, aber es ging darum, eine Woche lang ungefähr tausend GPUs zu betreiben. Wir waren in einer ziemlich einzigartigen Position, um der Community helfen zu können, diese Modelle mit unserem frühen Zugriff auf das TPU-Produkt der Google Cloud Platform auszuprobieren, das noch nicht öffentlich verfügbar war.“
Die Implementierung proprietärer Systeme in Open Source ist mit Herausforderungen behaftet, insbesondere wenn nur wenige öffentliche Informationen vorhanden sind. Idealerweise steht der Code neben dem Datensatz zum Trainieren des Systems und sogenannten Weights zur Verfügung, die dafür verantwortlich sind, die in das System eingespeisten Daten in Vorhersagen umzuwandeln. Aber das ist nicht oft der Fall.
Bei der Entwicklung von OpenFold mussten Ahdritz und sein Team beispielsweise Informationen aus den offiziellen Materialien sammeln und die Unterschiede zwischen verschiedenen Quellen abgleichen, einschließlich des Quellcodes, des ergänzenden Codes und der Präsentationen, die die DeepMind-Forscher schon früh gegeben haben. Unklarheiten in Schritten wie Datenvorbereitung und Trainingscode führten zu Fehlstarts, während ein Mangel an Hardwareressourcen Kompromisse beim Design erforderlich machte.
„Wir haben nur eine Handvoll Versuche, das richtig zu machen, damit sich das nicht auf unbestimmte Zeit hinzieht. Diese Dinge haben so viele rechenintensive Phasen, dass ein winziger Fehler uns stark zurückwerfen kann, sodass wir das Modell neu trainieren und auch viele Trainingsdaten neu generieren mussten“, sagte Ahdritz. „Einige technische Details, die sehr gut funktionieren [DeepMind] funktionieren bei uns nicht so einfach, weil wir unterschiedliche Hardware haben … Darüber hinaus macht es die Unklarheit darüber, welche Details von entscheidender Bedeutung sind und welche ohne viel Nachdenken ausgewählt werden, schwierig, etwas zu optimieren oder zu optimieren, und bindet uns an irgendetwas (manchmal umständlich). Entscheidungen wurden im ursprünglichen System getroffen.“
Achten Sie also darauf, dass die Labors hinter den proprietären Systemen wie OpenAI ihre Arbeit rückentwickeln und sogar von Startups dazu verwenden konkurrierende Dienste starten? Offensichtlich nicht. Ahdritz sagt, die Tatsache, dass insbesondere DeepMind so viele Details über seine Systeme veröffentlicht, deutet darauf hin, dass es die Bemühungen implizit unterstützt, auch wenn es dies nicht öffentlich gesagt hat.
„Wir haben keinen klaren Hinweis darauf erhalten, dass DeepMind diese Bemühungen missbilligt oder billigt“, sagte Ahdritz. „Aber sicherlich hat niemand versucht, uns aufzuhalten.“