
Die zunehmende Leichtigkeit, mit der jeder überzeugende Audioinhalte mit der Stimme eines anderen erstellen kann, macht viele Menschen nervös, und das zu Recht. ähneln KIs Vorschlag zum Wasserzeichen von generierter Sprache kann es nicht auf einen Schlag beheben, aber es ist ein Schritt in die richtige Richtung.
KI-generierte Sprache wird für alle Arten von legitimen Zwecken verwendet, von Bildschirmlesegeräten bis hin zum Ersetzen von Sprechern (natürlich mit ihrer Erlaubnis). Aber wie bei fast jeder Technologie kann auch die Spracherzeugung böswilligen Zwecken zugeführt werden, indem gefälschte Zitate von Politikern oder Prominenten produziert werden. Es ist höchst wünschenswert, einen Weg zu finden, Echtes von Fälschung zu unterscheiden, der nicht auf einen Publizisten oder genaues Zuhören angewiesen ist.
Wasserzeichen sind eine Technik, bei der ein Bild oder Ton mit einem identifizierbaren Muster bedruckt wird, das seinen Ursprung zeigt. Wir alle haben offensichtliche Wasserzeichen wie ein Logo auf einem Bild gesehen, aber nicht alle sind so auffällig.
In Bildern kann ein verborgenes Wasserzeichen das Muster Pixel für Pixel verbergen, sodass das Bild für das menschliche Auge unverändert aussieht, aber für einen Computer identifizierbar ist. Gleiches gilt für Audio: Ein gelegentlicher leiser Ton, der die Informationen kodiert, ist möglicherweise nichts, was ein gelegentlicher Zuhörer hören würde.
Das Problem mit diesen subtilen Wasserzeichen besteht darin, dass sie dazu neigen, selbst durch geringfügige Änderungen an den Medien ausgelöscht zu werden. Größe des Bildes ändern? Da kommt Ihr pixelgenauer Code. Codieren Sie das Audio für das Streaming? Die geheimen Töne werden direkt aus der Existenz komprimiert.
Resemble AI gehört zu einer neuen Kohorte generativer KI-Startups, die darauf abzielen, fein abgestimmte Sprachmodelle zu verwenden, um Dubs, Hörbücher und andere Medien zu produzieren, die normalerweise von normalen menschlichen Stimmen produziert werden. Aber wenn solche Modelle, die vielleicht mit stundenlangen Audioaufnahmen von Schauspielern trainiert wurden, in böswillige Hände geraten, könnten sich diese Unternehmen im Zentrum einer PR-Katastrophe und möglicherweise einer ernsthaften Haftung wiederfinden. Daher ist es sehr in ihrem Interesse, einen Weg zu finden, ihre Aufnahmen sowohl so realistisch wie möglich als auch leicht nachweisbar als von KI generiert zu machen.
PerTh ist Resembles vorgeschlagener Wasserzeichenprozess für diesen Zweck, eine umständliche Kombination aus „Wahrnehmung“ und „Schwellenwert“.
„Wir haben eine zusätzliche Sicherheitsebene entwickelt, die maschinelle Lernmodelle verwendet, um sowohl Datenpakete in die von uns generierten Sprachinhalte einzubetten als auch diese Daten zu einem späteren Zeitpunkt wiederherzustellen“, schreibt das Unternehmen in einem Blogbeitrag, in dem die Technologie erläutert wird. „Da die Daten nicht wahrnehmbar sind, obwohl sie eng mit den Sprachinformationen gekoppelt sind, sind sie sowohl schwer zu entfernen als auch eine Möglichkeit zu überprüfen, ob ein bestimmter Clip von Resemble generiert wurde. Wichtig ist, dass diese „Wasserzeichen“-Technik auch verschiedene Audiomanipulationen wie Beschleunigung, Verlangsamung, Konvertierung in komprimierte Formate wie MP3 usw. toleriert.“
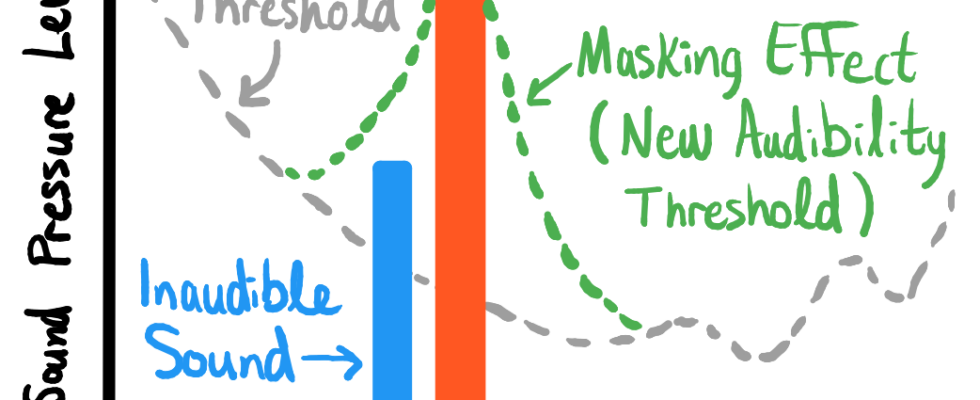
Es beruht auf einer Eigenart der menschlichen Audioverarbeitung, bei der Töne mit hoher Hörbarkeit im Wesentlichen benachbarte Töne mit geringerer Amplitude „maskieren“. Wenn also jemand lacht und es Spitzen bei den Frequenzen 5.000 Hz, 8.000 Hz und 9.200 Hz erzeugt, können Sie strukturierte Töne einschleusen, die gleichzeitig innerhalb weniger Hertz auftreten, und sie werden für Zuhörer mehr oder weniger nicht wahrnehmbar sein. Aber wenn Sie es richtig machen, sind sie auch robust gegen das Entfernen, da sie sich sehr nahe an einem wichtigen Teil des Audios befinden.
Hier kommt das Diagramm:
Diagramm, das zeigt, wie niedrigere Töne von nahegelegenen Spitzen „maskiert“ werden. Bildnachweis: ähneln KI
Es ist intuitiv, aber die Herausforderung bestand zweifellos darin, ein maschinelles Lernmodell zu erstellen, das in Frage kommende Wellenformabschnitte lokalisieren und automatisch die geeigneten, aber unhörbaren Audiotöne erzeugen kann, die die identifizierenden Informationen enthalten. Dann muss es diesen Prozess umkehren und gleichzeitig robust gegenüber gängigen Klangmanipulationen wie den oben erwähnten bleiben.
Hier sind zwei Beispiele, die sie bereitgestellt haben. Sehen Sie, ob Sie herausfinden können, welches mit einem Wasserzeichen versehen ist. Bewegen Sie den Mauszeiger hierher, um die Antwort in Ihrer Statusleiste anzuzeigen.
Ich kann keinen Unterschied feststellen, und selbst bei einer ziemlich genauen Untersuchung der Wellenformen konnte ich keine offensichtlichen Anomalien finden. Ich bin heutzutage nicht geschickt genug mit einem Spektrumanalysator, um wirklich dort hineinzukommen, aber ich vermute, dass Sie dort etwas sehen könnten. Jedenfalls würde ich sagen, wenn ihre Behauptung, dass Daten, die auf eine Erzeugung durch Resemble hindeuten, mehr oder weniger irreversibel in einen dieser Clips kodiert sind, ein Erfolg ist.
PerTh wird in Kürze bei allen Kunden von Resemble eingeführt, und um es jetzt klarzustellen, es kann nur die vom Unternehmen selbst erzeugte Sprache markieren und erkennen. Aber wenn sie es getan haben, werden andere es wahrscheinlich auch tun – und die Chancen stehen gut, dass diese Engines bald untrennbar mit den Spracherzeugungsmodellen selbst verbunden sein werden. Böswillige Akteure werden immer einen Weg finden, solche Dinge zu umgehen, aber die Einrichtung von Barrieren sollte helfen, einen Teil dieses Verhaltens einzudämmen.
Audio ist auf diese Weise jedoch etwas Besonderes, und ähnliche Tricks funktionieren nicht für Text oder Bilder. Erwarten Sie also, in diesen Bereichen eine Weile im unheimlichen Tal zu bleiben.