

Die neuesten Sprachmodelle wie GPT-4o und Gemini 1.5 Pro werden als „multimodal“ angepriesen und können Bilder und Audio ebenso gut verstehen wie Text – aber eine neue Studie macht deutlich, dass sie das nicht wirklich können. sehen wie Sie es vielleicht erwarten. Tatsächlich sehen sie möglicherweise überhaupt nichts.
Um es gleich vorweg klarzustellen: Niemand hat Behauptungen aufgestellt wie „Diese KI kann sehen wie Menschen!“ (Nun ja … vielleicht haben das einige.) Aber in der Werbung und den Benchmarks, die zur Bewerbung dieser Modelle verwendet werden, finden sich Ausdrücke wie „Sehfähigkeiten“, „visuelles Verständnis“ und so weiter. Sie sprechen darüber, wie das Modell Bilder und Videos sieht und analysiert, sodass es alles kann, von Hausaufgaben bis hin zum Anschauen eines Spiels für Sie.
Obwohl die Behauptungen dieser Unternehmen kunstvoll formuliert sind, ist klar, dass sie zum Ausdruck bringen wollen, dass das Modell in gewissem Sinne des Wortes sieht. Und das tut es – aber auf die gleiche Weise, wie es rechnet oder Geschichten schreibt: Es gleicht Muster in den Eingabedaten mit Mustern in seinen Trainingsdaten ab. Dies führt dazu, dass die Modelle auf die gleiche Weise versagen wie bei bestimmten anderen Aufgaben, die trivial erscheinen, wie etwa bei der Auswahl einer Zufallszahl.
Eine Studie – in gewisser Weise informell, aber systematisch – über das visuelle Verständnis aktueller KI-Modelle wurde von Forschern der Auburn University und der University of Alberta durchgeführt. Sie stellten den größten multimodalen Modellen eine Reihe sehr einfacher visueller Aufgaben, etwa die Frage, ob sich zwei Formen überlappen, wie viele Fünfecke in einem Bild vorkommen oder welcher Buchstabe in einem Wort eingekreist ist. (Eine zusammenfassende Micropage finden Sie hier.)
Das sind Dinge, die sogar ein Erstklässler richtig hinbekommen würde, die den KI-Modellen jedoch große Schwierigkeiten bereiteten.
„Unsere 7 Aufgaben sind extrem einfach und würden von Menschen mit 100-prozentiger Genauigkeit ausgeführt. Wir erwarten, dass KIs das Gleiche tun, aber derzeit tun sie es NICHT“, schrieb der Co-Autor Anh Nguyen in einer E-Mail an Tech. „Unsere Botschaft ist: ‚Sehen Sie, diese besten Modelle versagen IMMER NOCH.‘“
Nehmen wir zum Beispiel den Test mit überlappenden Formen: eine der einfachsten Aufgaben zum visuellen Denken, die man sich vorstellen kann. Bei zwei Kreisen, die sich entweder leicht überlappten, sich gerade berührten oder einen gewissen Abstand voneinander hatten, konnten die Modelle es nicht immer richtig machen. Sicher, GPT-4o lag in über 95 % der Fälle richtig, wenn die Kreise weit voneinander entfernt waren, aber bei null oder geringen Abständen lag es nur in 18 % der Fälle richtig! Gemini Pro 1.5 schneidet am besten ab, erreicht aber bei geringen Abständen immer noch nur 7/10.
(Die Abbildungen zeigen nicht die genaue Leistung der Modelle, sondern sollen die Inkonsistenz der Modelle unter verschiedenen Bedingungen verdeutlichen. Die Statistiken für jedes Modell finden Sie im Dokument.)
Oder wie wäre es, die Anzahl der ineinandergreifenden Kreise in einem Bild zu zählen? Ich wette, ein überdurchschnittliches Pferd könnte das.
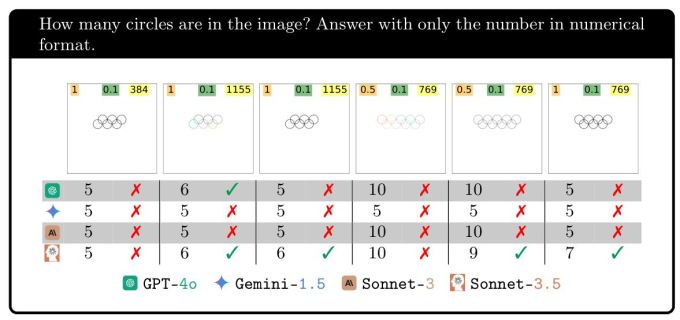
Sie liegen alle zu 100 % richtig, wenn es 5 Ringe gibt – tolle Arbeit, visuelle KI! Aber wenn dann ein Ring hinzugefügt wird, sind die Ergebnisse völlig zerstört. Gemini ist verloren und kann es kein einziges Mal richtig machen. Sonett-3.5 beantwortet 6 … ein Drittel der Zeit und GPT-4o etwas weniger als die Hälfte der Zeit. Wenn ein weiterer Ring hinzugefügt wird, wird es noch schwieriger, aber wenn ein weiterer hinzugefügt wird, fällt es manchen leichter.
Der Sinn dieses Experiments besteht einfach darin, zu zeigen, dass das, was diese Modelle tun, nicht wirklich mit dem übereinstimmt, was wir als Sehen bezeichnen. Selbst wenn sie schlecht sehen würden, würden wir schließlich nicht erwarten, dass Bilder mit 6, 7, 8 und 9 Ringen so unterschiedlich erfolgreich sind.
Bei den anderen getesteten Aufgaben zeigten sich ähnliche Muster: Es lag nicht daran, dass sie gut oder schlecht sahen oder schlussfolgern konnten, sondern es schien einen anderen Grund dafür zu geben, warum sie in einem Fall rechnen konnten, im anderen aber nicht.
Eine mögliche Antwort liegt natürlich auf der Hand: Warum sind sie so gut darin, ein Bild mit fünf Kreisen richtig hinzubekommen, scheitern aber so kläglich beim Rest oder wenn es fünf Fünfecke sind? (Um fair zu sein, Sonnet-3.5 hat das ziemlich gut hingekriegt.) Weil in ihren Trainingsdaten alle ein Bild mit fünf Kreisen prominent vertreten ist: die Olympischen Ringe.

Dieses Logo wird nicht nur in den Trainingsdaten immer wieder wiederholt, sondern wahrscheinlich auch in Alternativtexten, Nutzungsrichtlinien und Artikeln ausführlich beschrieben. Aber wo in ihren Trainingsdaten finden Sie 6 oder 7 ineinandergreifende Ringe? Wenn ihre Antworten ein Hinweis sind … nirgendwo! Sie haben keine Ahnung, was sie „sehen“, und kein wirkliches visuelles Verständnis davon, was Ringe, Überlappungen oder eines dieser Konzepte sind.
Ich fragte, was die Forscher von dieser „Blindheit“ halten, die sie den Modellen vorwerfen. Wie andere Begriffe, die wir verwenden, hat sie eine anthropomorphe Qualität, die nicht ganz zutreffend ist, auf die man aber nur schwer verzichten kann.
„Ich stimme zu, „blind“ hat selbst für Menschen viele Definitionen und es gibt noch kein Wort für diese Art von Blindheit/Unempfindlichkeit von KIs gegenüber den Bildern, die wir zeigen“, schrieb Nguyen. „Derzeit gibt es keine Technologie, um genau zu visualisieren, was ein Modell sieht. Und ihr Verhalten ist eine komplexe Funktion der Eingabetextaufforderung, des Eingabebilds und vieler Milliarden Gewichte.“
Er spekulierte, dass die Modelle nicht wirklich blind seien, sondern dass die visuellen Informationen, die sie aus einem Bild extrahieren, eher abstrakt und ungefähr seien, etwa „auf der linken Seite ist ein Kreis“. Die Modelle haben jedoch keine Möglichkeit, visuelle Urteile zu fällen, und reagieren daher wie jemand, der über ein Bild informiert ist, es aber nicht sehen kann.
Als letztes Beispiel schickte Nguyen dies, was die obige Hypothese unterstützt:

Wenn sich ein blauer und ein grüner Kreis überlappen (wie es das Modell laut Frage als Tatsache annimmt), entsteht häufig ein cyanfarbener Bereich, wie in einem Venn-Diagramm. Wenn Ihnen jemand diese Frage stellen würde, würden Sie oder jede andere intelligente Person wahrscheinlich dieselbe Antwort geben, denn sie ist absolut plausibel … wenn Sie die Augen geschlossen haben! Aber niemand mit geschlossenen Augen offen würde so antworten.
Heißt das alles, dass diese „visuellen“ KI-Modelle nutzlos sind? Weit gefehlt. Dass sie nicht in der Lage sind, elementare Schlussfolgerungen über bestimmte Bilder zu ziehen, spricht für ihre grundlegenden Fähigkeiten, aber nicht für ihre spezifischen. Jedes dieser Modelle wird wahrscheinlich bei Dingen wie menschlichen Handlungen und Ausdrücken, Fotos von Alltagsgegenständen und -situationen und dergleichen sehr genau sein. Und genau das ist es, was sie interpretieren sollen.
Wenn wir uns darauf verlassen würden, dass die Marketing-Abteilungen der KI-Unternehmen uns verraten, was diese Modelle alles können, würden wir annehmen, dass sie eine glasklare Sicht haben. Es bedarf solcher Forschung, um zu zeigen, dass die Modelle, egal wie genau sie sagen, ob eine Person sitzt, geht oder rennt, dies tun, ohne in dem Sinne „zu sehen“, wie wir es normalerweise meinen.