

Die Forschung auf dem Gebiet des maschinellen Lernens und der KI, mittlerweile eine Schlüsseltechnologie in praktisch jeder Branche und jedem Unternehmen, ist viel zu umfangreich, als dass jemand sie vollständig lesen könnte. Diese Kolumne, Perceptron (früher Deep Science), zielt darauf ab, einige der relevantesten jüngsten Entdeckungen und Artikel zu sammeln – insbesondere im Bereich der künstlichen Intelligenz, aber nicht darauf beschränkt – und zu erklären, warum sie wichtig sind.
Diese Woche hat ein Team von Ingenieuren an der Universität Glasgow im Bereich KI „künstliche Haut“ entwickelt, die lernen kann, simulierten Schmerz zu erleben und darauf zu reagieren. An anderer Stelle entwickelten Forscher von DeepMind ein maschinelles Lernsystem, das vorhersagt, wo Fußballspieler auf einem Feld laufen werden, während Gruppen von der Chinese University of Hong Kong (CUHK) und der Tsinghua University Algorithmen entwickelten, die realistische Fotos – und sogar Videos – von Menschen erzeugen können Modelle.
Laut einer Pressemitteilung des Glasgow-Teams künstliche Haut nutzten eine neue Art von Verarbeitungssystem, das auf „synaptischen Transistoren“ basiert, die die neuralen Bahnen des Gehirns nachahmen sollen. Die Transistoren aus Zinkoxid-Nanodrähten, die auf die Oberfläche eines flexiblen Kunststoffs gedruckt wurden, waren mit einem Hautsensor verbunden, der Änderungen des elektrischen Widerstands registrierte.
Bildnachweis: Universität Glasgow
Obwohl schon früher Versuche mit künstlicher Haut unternommen wurden, behauptet das Team, dass sich ihr Design dadurch unterschied, dass es einen in das System eingebauten Schaltkreis verwendete, der als „künstliche Synapse“ fungierte und den Eingang auf eine Spannungsspitze reduzierte. Dies beschleunigte die Verarbeitung und ermöglichte es dem Team, der Haut „beizubringen“, wie sie auf simulierten Schmerz reagieren soll, indem es einen Schwellenwert für die Eingangsspannung festlegte, dessen Frequenz je nach Höhe des auf die Haut ausgeübten Drucks variierte.
Das Team sieht die Anwendung der Haut in der Robotik, wo sie zum Beispiel verhindern könnte, dass ein Roboterarm mit gefährlich hohen Temperaturen in Kontakt kommt.
Tangential verwandt mit der Robotik behauptet DeepMind, ein KI-Modell entwickelt zu haben, Graph-Imputer, das anhand von Kameraaufzeichnungen nur einer Untergruppe von Spielern vorhersagen kann, wohin sich Fußballspieler bewegen werden. Noch beeindruckender ist, dass das System Vorhersagen über Spieler außerhalb der Sicht der Kamera treffen kann, wodurch es die Position der meisten – wenn nicht aller – Spieler auf dem Spielfeld ziemlich genau verfolgen kann.
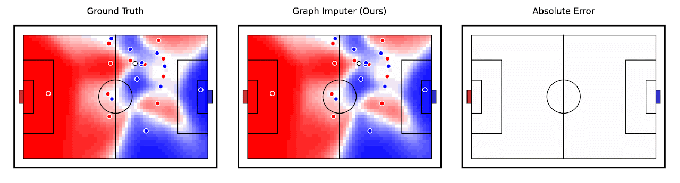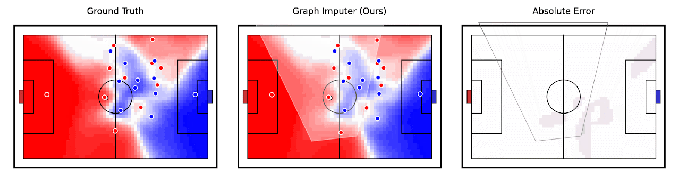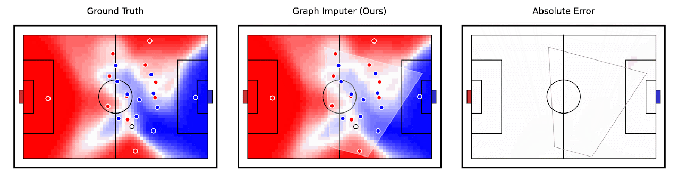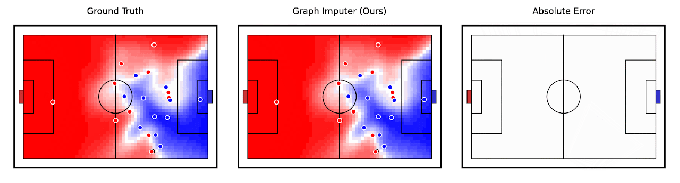
Bildnachweis: DeepMind
Graph Imputer ist nicht perfekt. Aber die DeepMind-Forscher sagen, dass es für Anwendungen wie die Modellierung der Spielfeldkontrolle oder der Wahrscheinlichkeit verwendet werden könnte, dass ein Spieler den Ball kontrollieren könnte, vorausgesetzt, er befindet sich an einem bestimmten Ort. (Mehrere führende Teams der Premier League verwenden Spielfeldsteuerungsmodelle während der Spiele sowie in der Analyse vor und nach dem Spiel.) Über Fußball- und andere Sportanalysen hinaus erwartet DeepMind, dass die Techniken hinter Graph Imputer auf Bereiche wie Fußgängermodellierung auf Straßen und Menschenmengenmodellierung in Stadien anwendbar sein werden.
Während künstliche Haut und bewegungsvorhersagende Systeme beeindruckend sind, schreiten Foto- und Video-erzeugende Systeme mit rasanter Geschwindigkeit voran. Offensichtlich gibt es hochkarätige Werke wie Dall-E 2 von OpenAI und Imagen von Google. Aber schau mal Text2Menschentwickelt vom CUHK Multimedia Lab, das eine Bildunterschrift wie „Die Dame trägt ein kurzärmliges T-Shirt mit reinem Farbmuster und einen kurzen Jeansrock“ in ein Bild einer Person übersetzen kann, die nicht wirklich existiert.
In Zusammenarbeit mit der Pekinger Akademie für künstliche Intelligenz hat die Tsinghua-Universität ein noch ehrgeizigeres Modell namens CogVideo entwickelt, das Videoclips aus Text generieren kann (z. B. „ein Mann beim Skifahren“, „ein Löwe trinkt Wasser“). Die Clips sind voller Artefakte und anderer visueller Verrücktheiten, aber wenn man bedenkt, dass es sich um völlig fiktive Szenen handelt, ist es schwer zu kritisieren zu hart.
Maschinelles Lernen wird häufig in der Arzneimittelforschung eingesetzt, wo die nahezu unendliche Vielfalt von Molekülen, die in Literatur und Theorie vorkommen, sortiert und charakterisiert werden müssen, um potenziell vorteilhafte Wirkungen zu finden. Aber das Datenvolumen ist so groß und die Kosten für Fehlalarme möglicherweise so hoch (es ist kostspielig und zeitaufwändig, Leads zu verfolgen), dass selbst eine Genauigkeit von 99 % nicht ausreicht. Dies gilt insbesondere für unbeschriftete molekulare Daten, bei weitem der Großteil dessen, was da draußen ist (im Vergleich zu Molekülen, die im Laufe der Jahre manuell untersucht wurden).
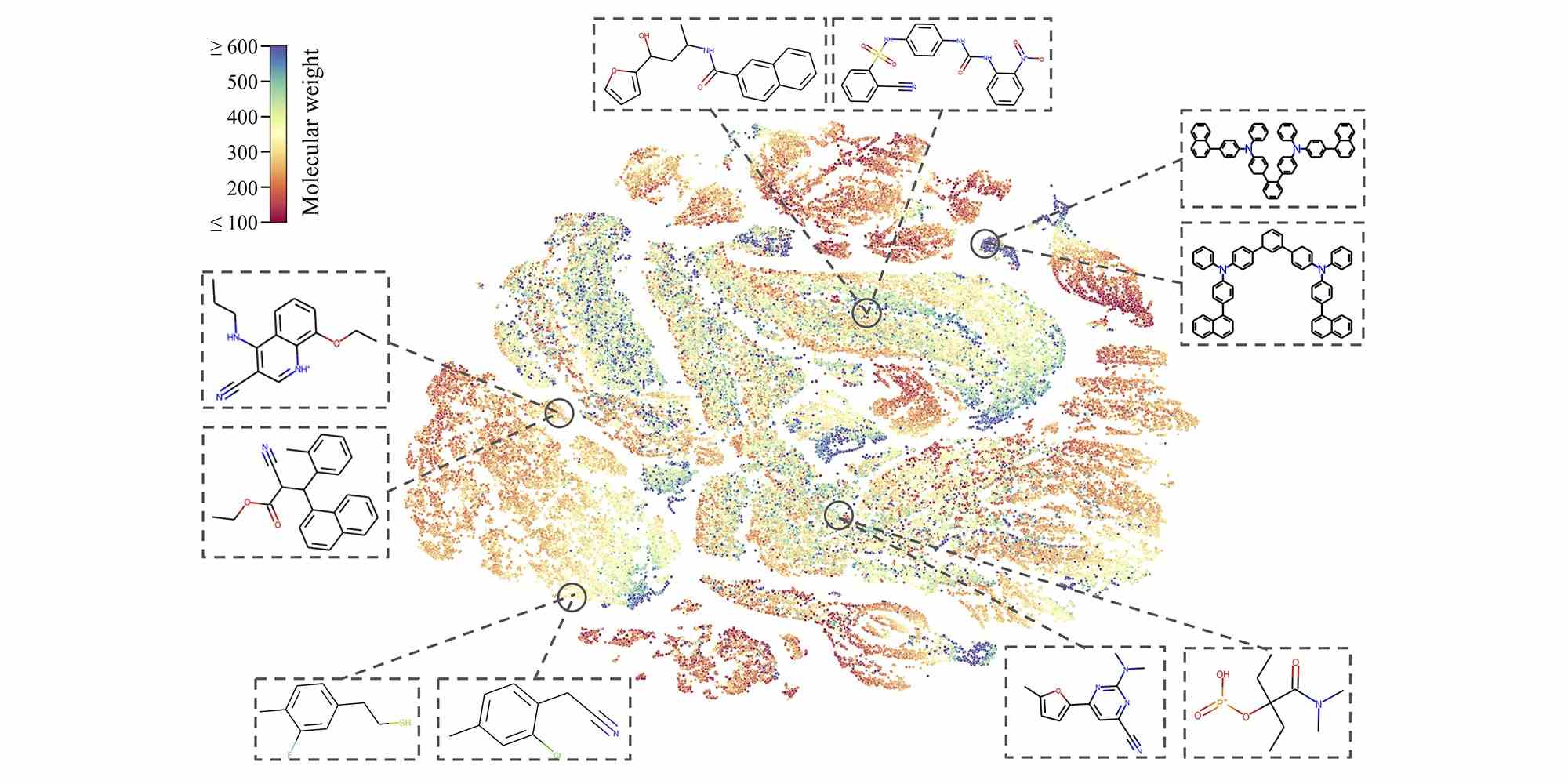
Bildnachweis: CMU
CMU-Forscher haben daran gearbeitet, ein Modell zu erstellen, um Milliarden nicht charakterisierter Moleküle zu sortieren, indem sie es darauf trainiert haben, sie ohne zusätzliche Informationen zu verstehen. Dies geschieht, indem es geringfügige Änderungen an der Struktur des (virtuellen) Moleküls vornimmt, z. B. ein Atom versteckt oder eine Bindung entfernt, und beobachtet, wie sich das resultierende Molekül ändert. Dadurch lernt es intrinsische Eigenschaften, wie solche Moleküle gebildet werden und sich verhalten – und führte dazu, dass es andere KI-Modelle bei der Identifizierung giftiger Chemikalien in einer Testdatenbank übertraf.
Molekulare Signaturen sind auch der Schlüssel zur Diagnose von Krankheiten – zwei Patienten können ähnliche Symptome aufweisen, aber eine sorgfältige Analyse ihrer Laborergebnisse zeigt, dass sie sehr unterschiedliche Zustände haben. Natürlich ist das gängige Arztpraxis, aber wenn sich Daten aus mehreren Tests und Analysen häufen, wird es schwierig, alle Korrelationen zu verfolgen. Die Technische Universität München arbeitet daran eine Art klinischer Meta-Algorithmus das mehrere Datenquellen (einschließlich anderer Algorithmen) integriert, um zwischen bestimmten Lebererkrankungen mit ähnlichen Präsentationen zu unterscheiden. Obwohl solche Modelle Ärzte nicht ersetzen werden, werden sie weiterhin dabei helfen, die wachsenden Datenmengen zu verarbeiten, für deren Interpretation selbst Spezialisten möglicherweise nicht die Zeit oder das Fachwissen haben.