
Die Forschung auf dem Gebiet des maschinellen Lernens und der KI, mittlerweile eine Schlüsseltechnologie in praktisch jeder Branche und jedem Unternehmen, ist viel zu umfangreich, als dass jemand sie vollständig lesen könnte. Diese Kolumne, Perceptron (früher Deep Science), zielt darauf ab, einige der relevantesten jüngsten Entdeckungen und Artikel zu sammeln – insbesondere im Bereich der künstlichen Intelligenz, aber nicht darauf beschränkt – und zu erklären, warum sie wichtig sind.
Diese Woche in KI, Forscher entdeckt eine Methode, die es Angreifern ermöglichen könnte, die Bewegungen von ferngesteuerten Robotern zu verfolgen, selbst wenn die Kommunikation der Roboter Ende-zu-Ende verschlüsselt ist. Die Co-Autoren, die von der University of Strathclyde in Glasgow stammen, sagten, dass ihre Studie zeigt, dass die Anwendung der besten Cybersicherheitspraktiken nicht ausreicht, um Angriffe auf autonome Systeme zu stoppen.
Die Fernsteuerung oder Teleoperation verspricht, Bediener in die Lage zu versetzen, einen oder mehrere Roboter aus der Ferne in einer Reihe von Umgebungen zu steuern. Startups wie Pollen Robotics, Beam und Tortoise haben die Nützlichkeit teleoperierter Roboter in Lebensmittelgeschäften, Krankenhäusern und Büros demonstriert. Andere Unternehmen entwickeln ferngesteuerte Roboter für Aufgaben wie die Bombenräumung oder die Vermessung von Orten mit starker Strahlung.
Aber die neue Forschung zeigt, dass Teleoperation, selbst wenn sie vermeintlich „sicher“ ist, riskant ist, da sie anfällig für Überwachung ist. Die Mitautoren von Strathclyde beschreiben in einem Artikel, wie sie mithilfe eines neuronalen Netzwerks Informationen darüber ableiten, welche Operationen ein ferngesteuerter Roboter ausführt. Nach dem Sammeln von Proben von TLS-geschützten Datenverkehr zwischen Roboter und Steuerung und führten eine Analyse durch, fanden sie heraus, dass das neuronale Netzwerk Bewegungen in etwa 60 % der Zeit identifizieren und auch „Lagerungsabläufe“ (z. B. das Aufnehmen von Paketen) mit „hoher Genauigkeit“ rekonstruieren konnte.
Bildnachweis: Shahet al.
Eine weniger unmittelbare Alarmierung ist neu lernen von Forschern bei Google und der University of Michigan, die die Beziehungen der Menschen zu KI-gestützten Systemen in Ländern mit schwacher Gesetzgebung und „landesweitem Optimismus“ für KI untersuchten. Die Arbeit befragte in Indien ansässige, „finanziell gestresste“ Benutzer von Sofortkreditplattformen, die auf Kreditnehmer mit Krediten abzielen, die durch Risikomodellierungs-KI bestimmt wurden. Laut den Co-Autoren fühlten sich die Benutzer für den „Segen“ von Sofortkrediten und die Verpflichtung, harte Bedingungen zu akzeptieren, sensible Daten zu teilen und hohe Gebühren zu zahlen, verschuldet.
Die Forscher argumentieren, dass die Ergebnisse die Notwendigkeit einer größeren „algorithmischen Rechenschaftspflicht“ veranschaulichen, insbesondere wenn es um KI in Finanzdienstleistungen geht. „Wir argumentieren, dass die Rechenschaftspflicht von den Machtverhältnissen zwischen Plattform und Benutzer geprägt ist, und fordern die politischen Entscheidungsträger auf, einen rein technischen Ansatz zur Förderung der algorithmischen Rechenschaftspflicht zu verfolgen“, schrieben sie. „Stattdessen fordern wir situative Interventionen, die die Handlungsfähigkeit der Nutzer stärken, sinnvolle Transparenz ermöglichen, Designer-Nutzer-Beziehungen neu konfigurieren und Praktiker zu einer kritischen Reflexion hin zu einer breiteren Verantwortlichkeit anregen.“
In weniger mürrisch Forschung, hat ein Team von Wissenschaftlern der TU Dortmund, der Universität Rhein-Waal und der LIACS Universiteit Leiden in den Niederlanden einen Algorithmus entwickelt, von dem sie behaupten, dass er das Spiel Rocket League „lösen“ kann. Motiviert, einen weniger rechenintensiven Weg zu finden, um spielerische KI zu entwickeln, nutzte das Team eine sogenannte „Sim-to-Sim“-Übertragungstechnik, die das KI-System trainierte, Aufgaben im Spiel wie Torwarten und Schlagen innerhalb von a auszuführen abgespeckte, vereinfachte Version von Rocket League. (Rocket League ähnelt im Grunde Hallenfußball, außer mit Autos anstelle von menschlichen Spielern in Dreierteams.)

Bildnachweis: Pleines et al.
Es war nicht perfekt, aber das Rocket League-Spielsystem der Forscher schaffte es, fast alle Schüsse zu retten, die beim Torhüter abgefeuert wurden. In der Offensive erzielte das System erfolgreich 75 % der Schüsse – ein respektabler Rekord.
Auch Simulatoren für menschliche Bewegungen entwickeln sich rasant weiter. Die Arbeit von Meta zur Verfolgung und Simulation menschlicher Gliedmaßen hat offensichtliche Anwendungen in seinen AR- und VR-Produkten, könnte aber auch in der Robotik und der verkörperten KI breiter eingesetzt werden. Forschung, die diese Woche herauskam, erhielt einen Tipp von der Kappe kein Geringerer als Mark Zuckerberg.
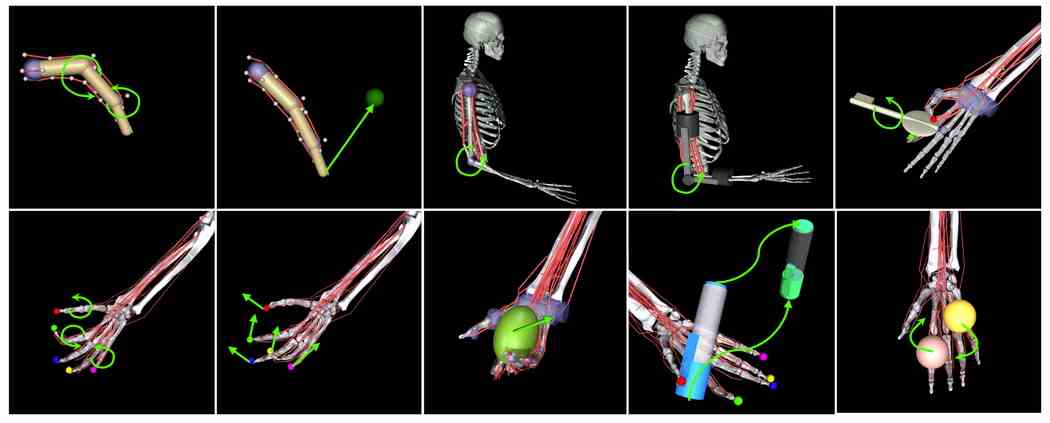
Simulierte Skelett- und Muskelgruppen in Myosuite.
MyoSuite simuliert Muskeln und Skelette in 3D, während sie mit Objekten und sich selbst interagieren – dies ist wichtig für Agenten, um zu lernen, wie man Dinge richtig hält und manipuliert, ohne sie zu zerquetschen oder fallen zu lassen, und bietet auch in einer virtuellen Welt realistische Griffe und Interaktionen. Es soll bei bestimmten Aufgaben tausendfach schneller laufen, was simulierte Lernprozesse viel schneller ablaufen lässt. „Wir werden diese Modelle als Open Source freigeben, damit Forscher sie verwenden können, um das Gebiet weiter voranzubringen“, sagt Zuck. Und das taten sie!
Viele dieser Simulationen sind agenten- oder objektbasiert, aber dieses Projekt vom MIT befasst sich mit der Simulation eines Gesamtsystems unabhängiger Agenten: selbstfahrende Autos. Die Idee ist, dass Sie, wenn Sie eine gute Anzahl von Autos auf der Straße haben, sie zusammenarbeiten lassen können, um nicht nur Kollisionen zu vermeiden, sondern auch Leerlauf und unnötige Stopps an Ampeln zu vermeiden.

Wenn man genau hinschaut, halten immer nur die vorderen Autos wirklich an.
Wie Sie in der obigen Animation sehen können, kann eine Reihe von autonomen Fahrzeugen, die über v2v-Protokolle kommunizieren, im Grunde verhindern, dass alle außer den allervordersten Autos überhaupt anhalten, indem sie hintereinander allmählich langsamer werden, aber nicht so sehr, dass sie tatsächlich zum Stillstand kommen . Diese Art von Hypermiling-Verhalten mag so aussehen, als würde es nicht viel Benzin oder Batterie sparen, aber wenn Sie es auf Tausende oder Millionen von Autos skalieren, macht es einen Unterschied – und es könnte auch eine komfortablere Fahrt sein. Viel Glück, alle dazu zu bringen, sich der Kreuzung mit perfektem Abstand zu nähern.
Die Schweiz wirft einen guten, langen Blick auf sich selbst – mit 3D-Scanning-Technologie. Das Land erstellt eine riesige Karte mit UAVs, die mit Lidar und anderen Werkzeugen ausgestattet sind, aber es gibt einen Haken: Die Bewegung der Drohne (absichtlich und versehentlich) führt zu Fehlern in der Punktkarte, die manuell korrigiert werden müssen. Kein Problem, wenn Sie nur ein einzelnes Gebäude, sondern ein ganzes Land scannen?
Glücklicherweise integriert ein Team der EPFL ein ML-Modell direkt in den Lidar-Erfassungsstapel, der feststellen kann, wann ein Objekt mehrmals aus verschiedenen Winkeln gescannt wurde, und diese Informationen verwendet, um die Punktkarte in einem einzigen zusammenhängenden Netz auszurichten. Dieser Nachrichtenartikel ist nicht besonders erhellend, aber das Begleitpapier geht näher darauf ein. Ein Beispiel der resultierenden Karte ist im obigen Video zu sehen.
Schließlich hat ein Team der Universität Zürich unerwartete, aber sehr erfreuliche KI-Nachrichten einen Algorithmus zur Verfolgung des Verhaltens von Tieren entwickelt Zoologen müssen sich also nicht durch wochenlanges Filmmaterial wühlen, um die beiden Beispiele für Balztänze zu finden. Es ist eine Zusammenarbeit mit dem Zoo Zürich, was Sinn macht, wenn man bedenkt: «Unsere Methode kann bei Versuchstieren auch subtile oder seltene Verhaltensänderungen erkennen, etwa Anzeichen von Stress, Angst oder Unwohlsein», sagt Laborleiter Mehmet Fatih Yanik.
Das Tool könnte also sowohl zum Lernen und Verfolgen von Verhaltensweisen in Gefangenschaft, zum Wohlergehen von in Gefangenschaft gehaltenen Tieren in Zoos als auch für andere Formen von Tierstudien verwendet werden. Sie könnten weniger Versuchstiere verwenden und mehr Informationen in kürzerer Zeit erhalten, mit weniger Arbeit von Doktoranden, die bis spät in die Nacht über Videodateien brüten. Klingt für mich nach einer Win-Win-Win-Win-Situation.

Bildnachweis: Ella Marushenko / ETH Zürich
Lieben Sie auch die Illustration.