
Proteine sind die Moleküle, die in der Natur Arbeit leisten, und es entsteht eine ganze Industrie, die sich mit ihrer erfolgreichen Modifizierung und Herstellung für verschiedene Zwecke beschäftigt. Dies ist jedoch zeitaufwändig und willkürlich; Wiege zielt darauf ab, dies mit einem KI-gestützten Werkzeug zu ändern, das Wissenschaftlern sagt, welche neuen Strukturen und Sequenzen ein Protein dazu bringen, das zu tun, was sie wollen. Das Unternehmen ist heute mit einer beträchtlichen Seed-Runde aus der Tarnung hervorgegangen.
KI und Proteine waren in letzter Zeit in den Nachrichten, aber hauptsächlich aufgrund der Bemühungen von Forschungseinrichtungen wie DeepMind und Baker Lab. Ihre maschinellen Lernmodelle nehmen einfach zu sammelnde RNA-Sequenzdaten auf und sagen die Struktur voraus, die ein Protein annehmen wird – ein Schritt, der früher Wochen und teure Spezialausrüstung erforderte.
Aber so unglaublich diese Fähigkeit in manchen Bereichen auch ist, für andere ist sie nur der Ausgangspunkt. Ein Protein so zu modifizieren, dass es stabiler ist oder an ein bestimmtes anderes Molekül bindet, erfordert viel mehr als nur das Verständnis seiner allgemeinen Form und Größe.
„Wenn Sie ein Proteiningenieur sind und eine bestimmte Eigenschaft oder Funktion in ein Protein einbauen möchten, hilft Ihnen das bloße Wissen, wie es aussieht, nicht weiter. Es ist, als hätte man ein Bild von einer Brücke, das einem nicht sagt, ob sie einstürzen wird oder nicht“, erklärte Stef van Grieken, CEO und Mitbegründer von Cradle.
„Alphafold nimmt eine Sequenz und sagt voraus, wie das Protein aussehen wird“, fuhr er fort. „Wir sind der generative Bruder davon: Sie wählen die Eigenschaften aus, die Sie entwickeln möchten, und das Modell generiert Sequenzen, die Sie in Ihrem Labor testen können.“
Vorhersagen, was Proteine – insbesondere solche, die neu in der Wissenschaft sind – tun werden vor Ort ist aus vielen Gründen eine schwierige Aufgabe, aber im Zusammenhang mit maschinellem Lernen besteht das größte Problem darin, dass nicht genügend Daten verfügbar sind. Cradle erstellte also einen Großteil seines eigenen Datensatzes in einem Nasslabor, testete Protein nach Protein und sah, welche Änderungen in ihren Sequenzen zu welchen Effekten zu führen schienen.
Interessanterweise ist das Modell selbst nicht genau biotechspezifisch, sondern ein Derivat derselben „großen Sprachmodelle“, die Textproduktionsmaschinen wie GPT-3 hervorgebracht haben. Van Grieken stellte fest, dass diese Modelle nicht ausschließlich auf Sprache beschränkt sind, um Daten zu verstehen und vorherzusagen, eine interessante Eigenschaft der „Verallgemeinerung“, die Forscher noch erforschen.
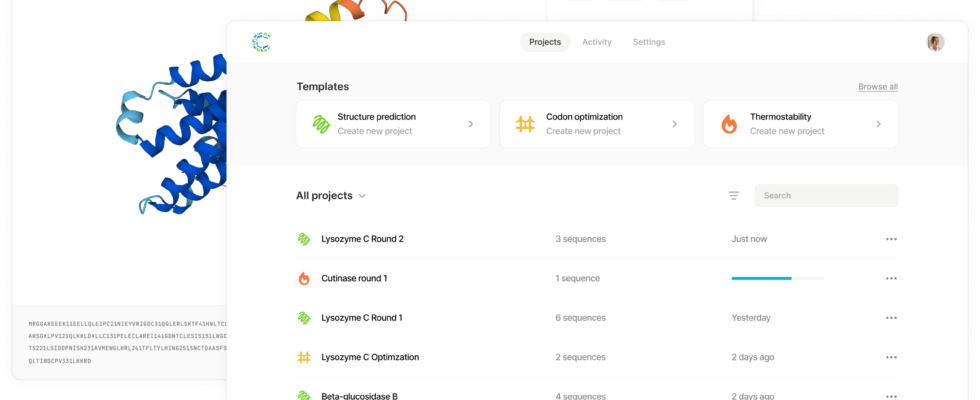
Beispiele der Cradle-Benutzeroberfläche in Aktion. Bildnachweis: Wiege
Die Proteinsequenzen, die Cradle aufnimmt und vorhersagt, liegen natürlich in keiner uns bekannten Sprache vor, aber sie sind relativ unkomplizierte lineare Textsequenzen mit zugehörigen Bedeutungen. „Es ist wie eine fremde Programmiersprache“, sagte van Grieken.
Protein-Ingenieure sind natürlich nicht hilflos, aber ihre Arbeit erfordert zwangsläufig eine Menge Vermutungen. Man kann ziemlich sicher sein, dass unter den 100 Sequenzen, die sie modifizieren, die Kombination ist, die den gewünschten Effekt erzeugt, aber darüber hinaus kommt es auf erschöpfende Tests an. Ein kleiner Hinweis hier könnte die Dinge erheblich beschleunigen und eine Menge fruchtloser Arbeit vermeiden.
Das Modell funktioniert in drei grundlegenden Schichten, erklärte er. Zuerst beurteilt es, ob eine gegebene Sequenz „natürlich“ ist, d.h. ob es sich um eine sinnvolle Abfolge von Aminosäuren handelt oder nur um zufällige. Dies ist vergleichbar mit einem Sprachmodell, das einfach mit 99%iger Sicherheit sagen kann, dass ein Satz auf Englisch (oder Schwedisch in van Griekens Beispiel) und die Wörter in der richtigen Reihenfolge sind. Dies weiß es aus dem „Lesen“ von Millionen solcher Sequenzen, die durch Laboranalysen bestimmt wurden.
Als nächstes wird die tatsächliche oder potenzielle Bedeutung in der fremden Sprache des Proteins untersucht. „Stellen Sie sich vor, wir geben Ihnen eine Sequenz, und das ist die Temperatur, bei der diese Sequenz auseinanderfällt“, sagte er. „Wenn Sie das für viele Sequenzen tun, können Sie nicht nur sagen: ‚Das sieht natürlich aus‘, sondern ‚Das sieht aus wie 26 Grad Celsius.‘ das hilft dem Modell herauszufinden, auf welche Regionen des Proteins es sich konzentrieren muss.“
Das Modell kann dann Sequenzen zum Einfügen vorschlagen – im Wesentlichen fundierte Vermutungen, aber ein stärkerer Ausgangspunkt als ein Kratzer. Der Ingenieur oder das Labor kann sie dann ausprobieren und diese Daten zurück auf die Cradle-Plattform bringen, wo sie erneut aufgenommen und zur Feinabstimmung des Modells für die Situation verwendet werden können.

Das Cradle-Team an einem schönen Tag in ihrem Hauptquartier (van Grieken in der Mitte). Bildnachweis: Wiege
Die Modifizierung von Proteinen für verschiedene Zwecke ist in der Biotechnologie nützlich, vom Arzneimitteldesign bis zur Bioherstellung, und der Weg vom Vanillemolekül zum maßgeschneiderten, effektiven und effizienten Molekül kann lang und teuer sein. Jede Möglichkeit, es zu verkürzen, wird wahrscheinlich zumindest von den Labortechnikern begrüßt, die Hunderte von Experimenten durchführen müssen, nur um ein gutes Ergebnis zu erzielen.
Cradle hat im Verborgenen gearbeitet und entwickelt sich nun, nachdem es in einer Seed-Runde unter der gemeinsamen Führung von Index Ventures und Kindred Capital 5,5 Millionen US-Dollar gesammelt hat, an der die Angels John Zimmer, Feike Sijbesma und Emily Leproust beteiligt waren.
Van Grieken sagte, die Finanzierung würde es dem Team ermöglichen, die Datenerfassung zu erweitern – je mehr, desto besser, wenn es um maschinelles Lernen geht – und an dem Produkt zu arbeiten, um es „selbstbedienbarer“ zu machen.
„Unser Ziel ist es, die Kosten und den Zeitaufwand für die Markteinführung eines biobasierten Produkts um eine Größenordnung zu reduzieren“, sagte van Grieken in der Pressemitteilung, „damit jeder – sogar „zwei Kinder in ihrer Garage“ – es mitbringen kann ein biobasiertes Produkt auf den Markt bringen.“