
KI-generierte Musik ist bereits ein innovatives Konzept, aber Riffus bringt es mit einem cleveren, seltsamen Ansatz auf eine andere Ebene, der seltsame und überzeugende Musik produziert, die nicht Audio verwendet, sondern Bilder von Audio.
Klingt seltsam, ist seltsam. Aber wenn es funktioniert, funktioniert es. Und es funktioniert! So’ne Art.
Diffusion ist eine maschinelle Lerntechnik zur Generierung von Bildern, die die KI-Welt im letzten Jahr aufgeladen hat. DALL-E 2 und Stable Diffusion sind die beiden bekanntesten Modelle, die visuelles Rauschen schrittweise durch das ersetzen, was die KI für eine Eingabeaufforderung hält.
Die Methode hat sich in vielen Kontexten als leistungsstark erwiesen und ist sehr anfällig für Feinabstimmungen, bei denen Sie dem meist trainierten Modell viele Inhalte einer bestimmten Art geben, damit es sich darauf spezialisiert, mehr Beispiele für diese Inhalte zu produzieren. Sie könnten es beispielsweise auf Aquarellen oder Fotos von Autos feinabstimmen, und es würde sich als besser geeignet erweisen, beides zu reproduzieren.
Was Seth Forsgren und Hayk Martiros für ihr Hobbyprojekt Riffus gemacht haben, war die Feinabstimmung von Stable Diffusion auf Spektrogrammen.
„Hayk und ich spielen zusammen in einer kleinen Band, und wir haben das Projekt einfach gestartet, weil wir Musik lieben und nicht wussten, ob es Stable Diffusion überhaupt möglich wäre, ein Spektrogrammbild mit genügend Genauigkeit zu erstellen, um es in Audio umzuwandeln“, Forsgren sagte Tech. „Mit jedem Schritt auf unserem Weg waren wir mehr und mehr beeindruckt von dem, was möglich ist, und eine Idee führt zur nächsten.“
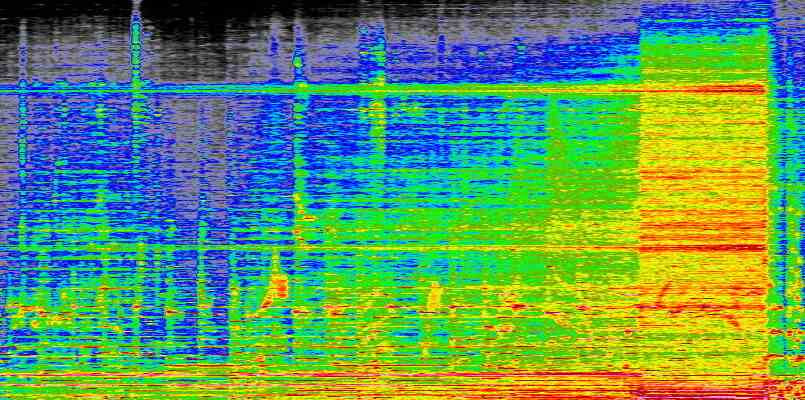
Was sind Spektrogramme, fragen Sie? Sie sind visuelle Darstellungen von Audio, die die Amplitude verschiedener Frequenzen im Laufe der Zeit zeigen. Sie haben wahrscheinlich schon Wellenformen gesehen, die die Lautstärke im Laufe der Zeit anzeigen und Audio wie eine Reihe von Hügeln und Tälern aussehen lassen; Stellen Sie sich vor, es würde anstelle der Gesamtlautstärke die Lautstärke jeder Frequenz vom unteren bis zum oberen Ende anzeigen.
Hier ist ein Teil von einem, den ich aus einem Lied gemacht habe („Marconis Radio“ von Secret Machinesfalls du dich fragst):
Bildnachweis: Devin Coldewey
Sie können sehen, wie es in allen Frequenzen lauter wird, während sich der Song aufbaut, und Sie können sogar einzelne Noten und Instrumente erkennen, wenn Sie wissen, wonach Sie suchen müssen. Der Prozess ist nicht von Natur aus perfekt oder verlustfrei, aber es ist eine genaue, systematische Darstellung des Klangs. Und Sie können es wieder in Ton umwandeln, indem Sie den gleichen Vorgang in umgekehrter Reihenfolge durchführen.
Forsgren und Martiros machten Spektrogramme von einer Menge Musik und markierten die resultierenden Bilder mit den relevanten Begriffen wie „Blues-Gitarre“, „Jazz-Piano“, „Afrobeat“ und solchen Sachen. Die Fütterung des Modells mit dieser Sammlung gab ihm eine gute Vorstellung davon, wie bestimmte Klänge „aussehen“ und wie es sie nachbilden oder kombinieren könnte.
So sieht der Diffusionsprozess aus, wenn Sie ihn beim Verfeinern des Bildes abtasten:

Bildnachweis: Seth Forsgren / Hayk Martiros
Und tatsächlich hat sich das Modell als in der Lage erwiesen, Spektrogramme zu erzeugen, die, wenn sie in Sound umgewandelt werden, ziemlich gut zu Eingabeaufforderungen wie „funky piano“, „jazzy saxophone“ und so weiter passen. Hier ist ein Beispiel:

Bildnachweis: Seth Forsgren / Hayk Martiros
Aber natürlich stellt ein quadratisches Spektrogramm (512 x 512 Pixel, eine Standard-Stable-Diffusion-Auflösung) nur einen kurzen Clip dar; Ein dreiminütiger Song wäre ein viel, viel breiteres Rechteck. Niemand möchte Musik fünf Sekunden am Stück hören, aber die Einschränkungen des von ihnen erstellten Systems bedeuten, dass sie nicht einfach ein Spektrogramm mit einer Höhe von 512 Pixeln und einer Breite von 10.000 erstellen konnten.
Nachdem sie ein paar Dinge ausprobiert hatten, machten sie sich die grundlegende Struktur großer Modelle wie Stable Diffusion zunutze, die viel „latenten Raum“ haben. Dies ist so etwas wie das Niemandsland zwischen besser definierten Knoten. Als ob Sie einen Bereich des Modells hätten, der Katzen darstellt, und einen anderen, der Hunde darstellt, was „zwischen“ ihnen ist, ist ein latenter Raum, der, wenn Sie der KI einfach sagen würden, dass er zeichnen soll, eine Art Hund oder Katze wäre, obwohl es keinen gibt sowas.
Übrigens wird Latent-Space-Zeug viel seltsamer als das:
Keine gruseligen Alptraumwelten für das Riffusion-Projekt. Stattdessen fanden sie heraus, dass man, wenn man zwei Eingabeaufforderungen hat, wie „Kirchenglocken“ und „elektronische Beats“, ein bisschen nach und nach von einer zur anderen wechseln kann und es allmählich und überraschend natürlich von einer zur anderen übergeht. sogar im Takt:
Es ist ein seltsamer, interessanter Sound, obwohl offensichtlich nicht besonders komplex oder High-Fidelity; Denken Sie daran, sie waren sich nicht einmal sicher, ob Diffusionsmodelle dies überhaupt können, also ist die Leichtigkeit, mit der dieses Gerät Glocken in Beats oder Schreibmaschinentaps in Piano und Bass verwandelt, ziemlich bemerkenswert.
Das Produzieren längerer Clips ist möglich, aber immer noch theoretisch:
„Wir haben nicht wirklich versucht, einen klassischen 3-Minuten-Song mit sich wiederholenden Refrains und Strophen zu kreieren“, sagte Forsgren. „Ich denke, es könnte mit einigen cleveren Tricks erreicht werden, wie z. B. dem Aufbau eines Modells auf höherer Ebene für die Songstruktur und der Verwendung des Modells auf niedrigerer Ebene für einzelne Clips. Alternativ könnten Sie unser Modell mit viel höher aufgelösten Bildern vollständiger Songs intensiv trainieren.“
Wo geht es von hier aus weiter? Andere Gruppen versuchen, KI-generierte Musik auf verschiedene Weise zu erstellen, indem sie sie verwenden Sprachsynthesemodelle bis hin zu speziell ausgebildeten Audiogeräten wie Dance Diffusion.
Riffusion ist eher ein „Wow, schaut euch das an“-Demo als irgendein großartiger Plan, Musik neu zu erfinden, und Forsgren sagte, er und Martiros seien einfach glücklich zu sehen, wie sich die Leute mit ihrer Arbeit beschäftigen, Spaß haben und sie wiederholen:
„Es gibt viele Richtungen, die wir von hier aus einschlagen könnten, und wir freuen uns darauf, auf diesem Weg weiter zu lernen. Es hat Spaß gemacht zu sehen, wie andere Leute heute Morgen auch bereits ihre eigenen Ideen auf unserem Code aufbauen. Eines der erstaunlichen Dinge an der Stable Diffusion-Community ist, wie schnell die Leute auf Dingen in Richtungen aufbauen, die die ursprünglichen Autoren nicht vorhersagen können.“
Sie können es in einer Live-Demo unter testen Riffus.com, aber Sie müssen möglicherweise etwas warten, bis Ihr Clip gerendert ist – dies hat etwas mehr Aufmerksamkeit erregt, als die Ersteller erwartet hatten. Der Code ist alle verfügbar über die About-Seitealso fühlen Sie sich frei, auch Ihr eigenes zu betreiben, wenn Sie die Chips dafür haben.