
OpenAI bringt seine API, die das Unternehmen behauptet, seine früheren Veröffentlichungen zu verbessern, neue Transkriptions- und Sprach-generierende KI-Modelle ein.
Für OpenAI passen die Modelle in ihre breitere „agentische“ Vision: Erstellen automatisierter Systeme, die Aufgaben im Namen der Benutzer unabhängig erfüllen können. Die Definition von „Agent“ könnte umstritten sein, aber der Openai -Produktleiter Olivier Godement beschrieb eine Interpretation als Chatbot, die mit den Kunden eines Unternehmens sprechen kann.
„Wir werden in den kommenden Monaten immer mehr Agenten auftauchen“, sagte Godement gegenüber Tech während eines Briefings. „Und so hilft das allgemeine Thema Kunden und Entwicklern dabei, Agenten zu nutzen, die nützlich, verfügbar und genau sind.“
OpenAI behauptet, dass sein neues Text-zu-Speech-Modell, „GPT-4O-Mini-TTS“, nicht nur eine nuanciertere und realistisch klingende Sprache liefert, sondern auch „lenkbarer“ ist als die Sprachsynthotisierungsmodelle für frühere Generation. Entwickler können GPT-4O-Mini-TTs unterweisen, wie man Dinge in der natürlichen Sprache sagt-zum Beispiel „sprechen wie ein verrückter Wissenschaftler“ oder „Verwenden Sie eine ruhige Stimme, wie ein Achtsamkeitslehrer“.
Hier ist eine „wahre, kriminelle“, verwitterte Stimme:
Und hier ist eine Stichprobe einer weiblichen „professionellen“ Stimme:
Jeff Harris, ein Mitarbeiter des Produktpersonals bei OpenAI, sagte gegenüber Tech, dass das Ziel darin besteht, Entwicklern sowohl die Stimme „Erfahrung“ als auch „Kontext“ anpassen zu lassen.
„In verschiedenen Kontexten wollen Sie nicht nur eine flache, monotone Stimme“, sagte Harris. „Wenn Sie sich in einer Kundensupporterfahrung befinden und die Stimme entschuldigen möchten, weil sie einen Fehler gemacht hat, können Sie tatsächlich die Stimme haben, die diese Emotionen darin haben … Unser großer Glaube ist hier, dass Entwickler und Benutzer wirklich nicht nur kontrollieren möchten, was gesprochen wird, sondern wie die Dinge gesprochen werden.“
In Bezug auf die neuen Sprachmodelle von OpenAI, „GPT-4O-Transcribe“ und „GPT-4O-Mini-Transcribe“, ersetzen sie das langweilige Flüstertranskriptionsmodell des Unternehmens effektiv. Die neuen Modelle sind auf „vielfältige, hochwertige Audio-Datensätze“ ausgebildet und können akzentuale und abwechslungsreiche Sprache besser erfassen, auch in chaotischen Umgebungen.
Es ist auch weniger wahrscheinlich, dass Harris hinzugefügt wird. Whisper neigte notorisch dazu, in Gesprächen Wörter – und sogar ganze Passagen – zu fabrizieren und alles von rassistischer Kommentar bis hin zu imaginären medizinischen Behandlungen in Transkripte einführte.
“[T]HESE -Modelle sind an dieser Front viel verbessert gegenüber Whisper „, sagte Harris. [in this context] bedeutet, dass die Modelle die Wörter genau hören [and] Füllen Sie keine Details aus, die sie nicht hörten. “
Ihre Kilometerleistung kann jedoch je nach der transkribierenden Sprache variieren.
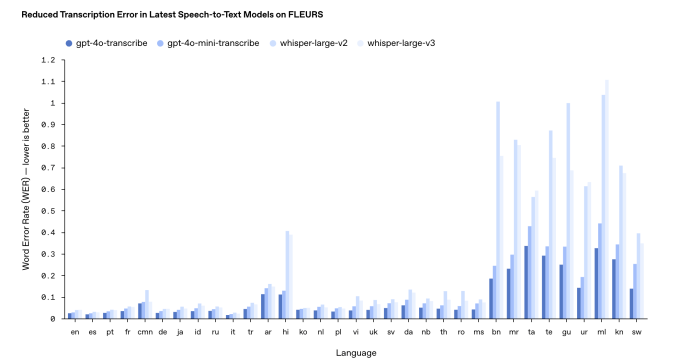
Laut den internen Benchmarks von OpenAI hat GPT-4O-Transcribe, je genauer der beiden Transkriptionsmodelle, eine „Wortfehlerrate“ für 30% (von 120%) für IND- und Dravidian-Sprachen wie Tamil, Telugu, Malayalam und Kannada nähert. Das bedeutet, dass drei von 10 Wörtern des Modells von einer menschlichen Transkription in diesen Sprachen unterscheiden.
In einer Pause von der Tradition plant Openai nicht, seine neuen Transkriptionsmodelle offen verfügbar zu machen. Die Firma Historisch veröffentlichte neue Versionen von Whisper für die kommerzielle Verwendung im Rahmen einer MIT -Lizenz.
Harris sagte, dass GPT-4O-transkribe und gpt-4o-mini-transkribe „viel größer als Whisper“ sind und daher keine guten Kandidaten für eine offene Veröffentlichung.
“[T]Hey, nicht die Art von Modell, die du einfach vor Ort auf deinem Laptop laufen kannst, wie Flüstern “, fuhr er fort.“[W]Ich möchte sicherstellen, dass wir es nachdenklich tun, wenn wir Dinge in Open Source veröffentlichen, und wir haben ein Modell, das wirklich für dieses bestimmte Bedürfnis geprägt ist. Und wir glauben, dass Endbenutzergeräte eines der interessantesten Fälle für Open-Source-Modelle sind. “
Aktualisiert 20. März 2025, 11:54 Uhr PT, um die Sprache zu klären Rund um die Wortfehlerrate und aktualisierte das Benchmark -Ergebnisdiagramm mit einer neueren Version.