

Aktualisiert 2:40 Uhr PT: Stunden nach der Veröffentlichung von GPT-44.5, OpenAI, entfernt eine Linie aus dem Whitepaper des KI-Modells mit der Aufschrift „GPT-4,5 ist kein Grenz-AI-Modell“. GPT-4.5 Neues weißes Papier schließt diese Linie nicht ein. Sie können einen Link zum alten weißen Papier finden Hier. Der ursprüngliche Artikel folgt.
OpenAI kündigte am Donnerstag an, GPT-4,5, den mit Spannung erwarteten AI-Modell, den Code-benannten Orion mit Code genannt. GPT-4,5 ist das bisher größte Modell von OpenAI, das mit mehr Rechenleistung und Daten geschult wird als alle früheren Veröffentlichungen des Unternehmens.
Trotz seiner Größe stellt Openai in a fest Weißes Papier Dass es GPT-4.5 nicht als Grenzmodell betrachtet.
Abonnenten von Chatgpt Pro, OpenAIs 200 US-Dollar pro Monat, erhalten ab Donnerstag im Rahmen einer Forschungsvorschau den Zugang zu GPT-4,5 in Chatgpt. Entwickler auf bezahlten Stufen der OpenAI-API können ab heute auch GPT-4,5 verwenden. Bei anderen ChatGPT -Benutzern sollten sich Kunden für Chatgpt Plus und ChatGPT -Team irgendwann nächste Woche das Modell erhalten, sagte ein OpenAI -Sprecher gegenüber Tech.
Die Branche hat ihren kollektiven Atem für Orion angehalten, was manche als ein Bellwether für die Lebensfähigkeit traditioneller KI -Trainingsansätze betrachten. GPT-4,5 wurde unter Verwendung derselben Schlüsseltechnik entwickelt, wodurch die Menge an Rechenleistung und Daten während einer „Pre-Training“ -Phase, die als unbeaufsichtigtes Lernen bezeichnet wurde, dramatisch erhöhte, mit der Openai GPT-4, GPT-3, GPT-2 und GPT-1 entwickelte.
In jeder GPT-Generation vor GPT-4,5 führte die Skalierung zu massiven Leistungen in den Bereichen Domänen, einschließlich Mathematik, Schreiben und Codierung. In der Tat sagt OpenAI, dass die erhöhte Größe von GPT-4,5 ihm „ein tieferes Weltwissen“ und „höhere emotionale Intelligenz“ gegeben hat. Es gibt jedoch Anzeichen dafür, dass die Gewinne durch Skalierung von Daten und Berechnungen beginnen. Bei mehreren KI-Benchmarks ist GPT-4,5 neuere KI-Modelle der chinesischen KI-Firma Deepseek, Anthropic und Openai selbst nicht vorhanden.
GPT-4,5 ist ebenfalls sehr teuer zu betreiben, gibt Openai zu-so teuer, dass das Unternehmen sagt, dass es auf lange Sicht bewertet, ob sie in seiner API weiterhin GPT-4,5 bedienen sollen. Um auf die API von GPT-4,5 zuzugreifen, berechnet OpenAI Entwicklern 75 US-Dollar für jede Million Input-Token (ungefähr 750.000 Wörter) und 150 US-Dollar für jede Million Output-Token. Vergleichen Sie das mit GPT-4O, das nur 2,50 USD pro Million Input-Token und 10 USD pro Million Output-Token kostet.
„Wir teilen GPT -4,5 als Forschungsvorschau, um seine Stärken und Einschränkungen besser zu verstehen“, sagte OpenAI in einem mit Tech geteilten Blog -Beitrag. „Wir untersuchen immer noch, wozu es fähig ist, und sind gespannt darauf, wie Menschen es auf eine Weise verwenden, die wir vielleicht nicht erwartet haben.“
Gemischte Leistung
OpenAI betont, dass GPT-4.5 für GPT-4O, das Arbeitspferdmodell des Unternehmens, das den größten Teil seiner API und des Chatgpts betreibt, kein Drop-In-Ersatz für das Unternehmen sein soll. Während GPT-4.5 Funktionen wie Datei- und Image-Uploads und das Canvas-Tool von ChatGPT unterstützt, fehlen derzeit Funktionen wie die Unterstützung für den realistischen Zwei-Wege-Sprachmodus von ChatGPT.
In der Plus-Spalte ist GPT-4,5 leistungsfähiger als GPT-4O-und viele andere Modelle.
Auf OpenAIs SimpleQa-Benchmark, das KI-Modelle auf einfachen, sachlichen Fragen testet, übertrifft GPT-4,5 die Mundmodelle von GPT-4O und OpenAI in Bezug auf die Genauigkeit, O1 und O3-Mini. Laut OpenAI halluziniert GPT-4,5 weniger häufig als die meisten Modelle, was bedeutet, dass es weniger wahrscheinlich ist, dass es sich um etwas erfunden sollte.
OpenAI listete nicht eines seiner hochwertigen KI-Argumentationsmodelle, Deep Research, auf SimpleQA auf. Ein OpenAI -Sprecher teilt Tech mit, er habe die Leistung von Deep Research in diesem Benchmark nicht öffentlich gemeldet und behauptet, es sei kein relevanter Vergleich. Bemerkenswerterweise das Deep Research -Modell von AI -Startup verblüfft, das sich ähnlich auf anderen Benchmarks für Openais Deep Research trifft. übertrifft GPT-4.5 bei diesem Test der sachlichen Genauigkeit.
Bei einer Untergruppe von Codierungsproblemen überprüft der SWE-Bench-Benchmark GPT-4,5 in etwa der Leistung von GPT-4O und O3-Mini, liegt jedoch nicht vor OpenAIs tiefe Forschung Und Anthropics Claude 3.7 Sonett. Bei einem anderen Codierungstest über die Fähigkeit eines KI-Modells, vollständige Softwarefunktionen zu entwickeln, übertrifft GPT-4,5 GPT-4O und O3-Mini, fällt jedoch nicht intensiv bei der tiefen Forschung.
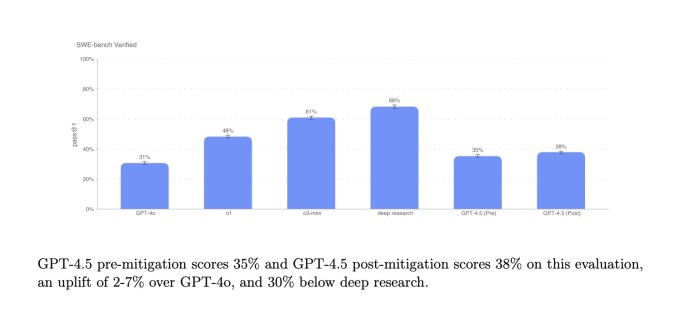
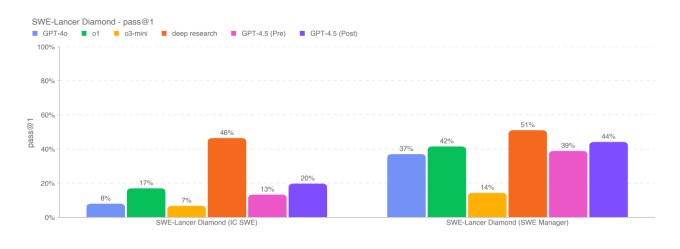
GPT-4,5 erreicht nicht ganz die Leistung führender KI-Argumentationsmodelle wie O3-Mini, Deepseeks R1 und Claude 3.7 Sonett (technisch gesehen ein Hybridmodell) für schwierige akademische Benchmarks wie Aime und GPQA. Aber GPT-4,5-Spiele oder die besten führenden Nicht-Begrenzungsmodelle zu denselben Tests, was darauf hindeutet, dass das Modell bei mathematischen und wissenschaftlichen Problemen eine gute Leistung erbringt.
Openai behauptet auch, dass GPT-4,5 ist qualitativ Überlegen gegenüber anderen Modellen in Bereichen, die Benchmarks nicht gut erfassen, wie die Fähigkeit, menschliche Absichten zu verstehen. GPT-4,5 reagiert in einem wärmeren und natürlicheren Ton, sagt Openai und spielt eine gute Leistung bei kreativen Aufgaben wie Schreiben und Design.
In einem informellen Test veranlasste OpenAI GPT-4,5 und zwei weitere Modelle, GPT-4O und O3-Mini, um ein Einhorn in SVG zu erstellen, ein Format zum Anzeigen von Grafiken, die auf mathematischen Formeln und Code basieren. GPT-4,5 war das einzige KI-Modell, das etwas erstellte, das einem Einhorn ähnelt.

In einem anderen Test bat Openai GPT-4,5 und die beiden anderen Modelle, auf die Eingabeaufforderung zu antworten: „Ich mache eine schwere Zeit nach dem Versagen eines Tests.“ GPT-4O und O3-Mini gaben hilfreiche Informationen an, aber die Antwort von GPT-4.5 war die sozial angemesseneste.
“[W]Ich freue mich darauf, durch diese Veröffentlichung ein vollständigeres Bild der Fähigkeiten von GPT-4.5 zu erhalten „, schrieb Openai im Blog-Beitrag,“ weil wir akademische Benchmarks anerkennen, spiegeln wir nicht immer die nützliche Nützlichkeit der realen Welt wider. „

Skalierungsgesetze in Frage gestellt
OpenAI behauptet, dass GPT -4,5 „an der Grenze dessen, was im unbeaufsichtigten Lernen möglich ist“, stammt. Das mag wahr sein, aber die Einschränkungen des Modells scheinen die Spekulationen von Experten zu bestätigen, die die „Skalierungsgesetze“ nicht weiterhin anhalten.
OpenAI-Mitbegründer und ehemaliger Chefwissenschaftler Ilya Sutskever sagte im Dezember, dass „wir Spitzendaten erreicht haben“ und dass „vor dem Training, wie wir sie wissen, zweifellos enden werden“. Seine Kommentare wiederholten Bedenken, dass KI -Investoren, Gründer und Forscher im November mit Tech für eine Funktion teilten.
Als Reaktion auf die Hürden vor dem Training hat die Branche-einschließlich OpenAI-Argumentationsmodelle angenommen, die länger als die nicht besessenen Modelle dauern, um Aufgaben auszuführen, aber tendenziell konsistenter sind. Durch die Erhöhung der Zeit- und Rechenleistung, mit der KI -Argumentationsmodelle durch Probleme „denken“, sind AI Labs zuversichtlich, dass sie die Funktionen der Modelle erheblich verbessern können.
OpenAI plant, seine GPT-Serie von Modellen schließlich mit seiner O-Argumentationserie zu kombinieren, beginnend mit GPT-5 später in diesem Jahr. GPT-4.5, was Berichten zufolge Es war unglaublich teuer, sich zu trainieren, mehrmals verzögert zu werden und die internen Erwartungen nicht zu erfüllen, die KI -Benchmark -Krone nicht selbst einnehmen. Aber Openai sieht es wahrscheinlich als Sprungbrett für etwas viel Mächtigeres.