
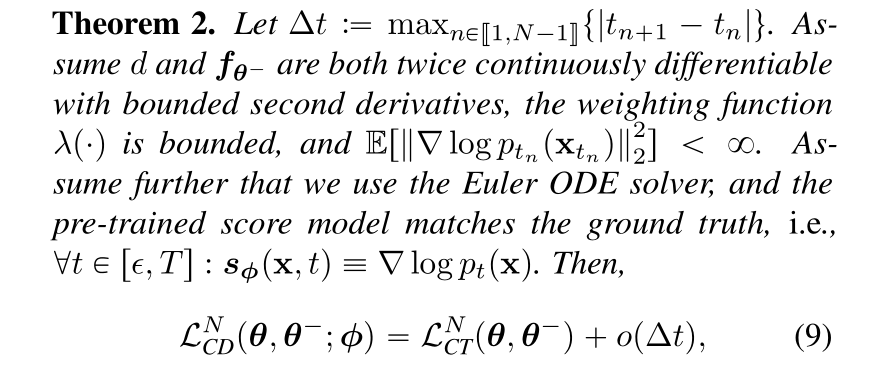
Das Feld der Bilderzeugung bewegt sich schnell. Obwohl die Diffusionsmodelle, die von beliebten Tools wie Midjourney und Stable Diffusion verwendet werden, wie die besten erscheinen, die wir haben, kommt immer das Nächste – und OpenAI könnte mit „Konsistenzmodellen“ darauf gestoßen sein, die bereits einfache Aufgaben erledigen können Größenordnung schneller als DALL-E.
Das Papier war letzten Monat als Preprint online gestellt, und wurde nicht von den untertriebenen Fanfaren begleitet, die OpenAI für seine Hauptversionen reserviert. Das ist keine Überraschung: Dies ist definitiv nur eine Forschungsarbeit und sehr technisch. Aber die Ergebnisse dieser frühen und experimentellen Technik sind interessant genug, um darauf hingewiesen zu werden.
Konsistenzmodelle sind nicht besonders einfach zu erklären, aber im Gegensatz zu Diffusionsmodellen sinnvoller.
Bei der Diffusion lernt ein Modell, wie man Rauschen allmählich von einem Ausgangsbild subtrahiert, das vollständig aus Rauschen besteht, und es Schritt für Schritt näher an den Zielprompt heranführt. Dieser Ansatz hat die beeindruckendsten KI-Bilder von heute ermöglicht, aber im Grunde ist es darauf angewiesen, zehn bis tausend Schritte auszuführen, um gute Ergebnisse zu erzielen. Das bedeutet, dass es teuer im Betrieb und auch langsam genug ist, dass Echtzeitanwendungen unpraktisch sind.
Das Ziel bei Konsistenzmodellen war es, etwas zu erstellen, das in einem oder höchstens zwei Berechnungsschritten anständige Ergebnisse liefert. Dazu wird das Modell wie ein Diffusionsmodell darauf trainiert, den Bildzerstörungsprozess zu beobachten, lernt aber, ein Bild auf jeder Ebene der Verdunkelung (dh mit wenigen oder vielen fehlenden Informationen) aufzunehmen und ein vollständiges Quellbild zu erzeugen nur ein Schritt.
Aber ich beeile mich hinzuzufügen, dass dies nur die schwammigste Beschreibung dessen ist, was passiert. Es ist diese Art von Papier:
Ein repräsentativer Auszug aus dem Konsistenzpapier.
Die resultierende Bildsprache ist nicht umwerfend – viele der Bilder können kaum als gut bezeichnet werden. Aber was zählt, ist, dass sie in einem einzigen Schritt generiert wurden und nicht in hundert oder tausend. Darüber hinaus lässt sich das Konsistenzmodell auf verschiedene Aufgaben wie Kolorieren, Hochskalieren, Skizzeninterpretation, Ausfüllen usw. verallgemeinern, ebenfalls in einem einzigen Schritt (obwohl häufig um einen zweiten Schritt verbessert).

Unabhängig davon, ob das Bild hauptsächlich aus Rauschen oder hauptsächlich aus Daten besteht, führen Konsistenzmodelle direkt zu einem Endergebnis.
Dies ist erstens wichtig, weil das Muster in der Forschung zum maschinellen Lernen im Allgemeinen darin besteht, dass jemand eine Technik etabliert, jemand anderes einen Weg findet, damit sie besser funktioniert, und dann andere sie im Laufe der Zeit optimieren, während sie Berechnungen hinzufügen, um drastisch bessere Ergebnisse zu erzielen, als Sie begonnen haben. So sind wir mehr oder weniger sowohl bei modernen Diffusionsmodellen als auch bei ChatGPT gelandet. Dies ist ein selbstbegrenzender Prozess, da Sie praktisch nur eine begrenzte Rechenleistung für eine bestimmte Aufgabe aufwenden können.
Als nächstes wird jedoch eine neue, effizientere Technik identifiziert, die das kann, was das Vorgängermodell getan hat, zunächst viel schlechter, aber auch viel effizienter. Konsistenzmodelle zeigen dies, obwohl es noch früh genug ist, dass sie nicht direkt mit Diffusionsmodellen verglichen werden können.
Aber es ist auf einer anderen Ebene von Bedeutung, denn es zeigt, wie OpenAI, derzeit mit Abstand das einflussreichste KI-Forschungsinstitut der Welt, aktiv nach Anwendungsfällen der nächsten Generation sucht, die über die Verbreitung hinausgehen.
Ja, wenn Sie 1500 Iterationen über ein oder zwei Minuten mit einem GPU-Cluster durchführen möchten, können Sie mit Diffusionsmodellen erstaunliche Ergebnisse erzielen. Aber was ist, wenn Sie einen Bildgenerator auf dem Telefon einer anderen Person ausführen möchten, ohne deren Akku zu entladen, oder ultraschnelle Ergebnisse beispielsweise in einer Live-Chat-Oberfläche liefern möchten? Diffusion ist einfach das falsche Werkzeug für diesen Job, und die Forscher von OpenAI suchen aktiv nach dem richtigen – darunter Ilya Sutskever, ein bekannter Name auf diesem Gebiet, um die Beiträge der anderen Autoren, Yang Song, Prafulla Dhariwal und nicht herunterzuspielen Markus Chen.
Ob Konsistenzmodelle der nächste große Schritt für OpenAI oder nur ein weiterer Pfeil im Köcher sind – die Zukunft ist mit ziemlicher Sicherheit sowohl multimodal als auch multimodellig – wird davon abhängen, wie sich die Forschung entwickelt. Ich habe nach weiteren Details gefragt und werde diesen Beitrag aktualisieren, wenn ich von den Forschern höre.