
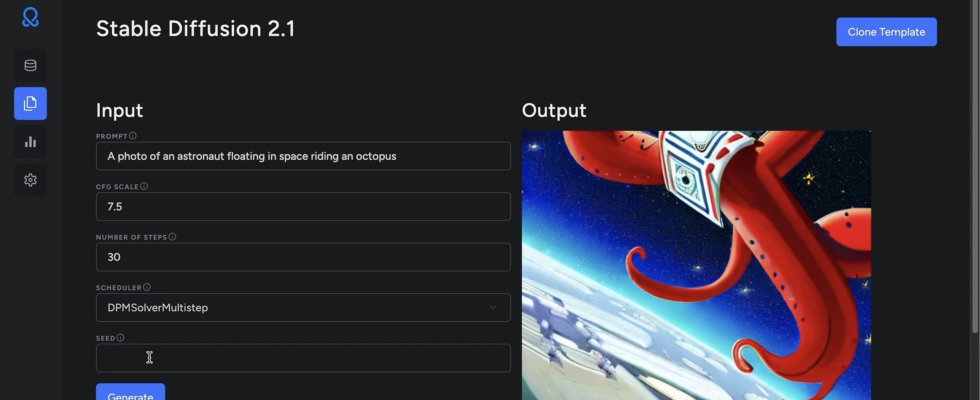
Wenn OctoML Das 2019 eingeführte Unternehmen konzentrierte sich in erster Linie auf die Optimierung von Modellen für maschinelles Lernen (ML). Seitdem hat das Unternehmen Funktionen hinzugefügt, die die Bereitstellung von ML-Modellen erleichtern (und 132 Millionen US-Dollar eingesammelt). Heute bringt das Unternehmen die neueste Version seines Dienstes auf den Markt – und obwohl dies kein echter Dreh- und Angelpunkt ist, verlagert es den Schwerpunkt des Unternehmens von der Optimierung von Modellen hin zur Unterstützung von Unternehmen bei der Nutzung bestehender Open-Source-Modelle und deren Feinabstimmung mit ihren eigenen Daten oder Nutzungen den Service, ihre eigenen benutzerdefinierten Modelle zu hosten. Die neue OctoML-Plattform – OctoAI genannt – ist ein selbstoptimierender Rechendienst für KI mit besonderem Schwerpunkt auf generativer KI, der Unternehmen dabei hilft, ML-basierte Anwendungen zu erstellen und in Produktion zu bringen, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen.
„Die vorherige Plattform konzentrierte sich auf ML-Ingenieure und die Optimierung und Verpackung der Modelle in Containern, die auf verschiedenen Hardwaresätzen eingesetzt werden konnten“, erklärte OctoML-Mitbegründer und CEO Luis Ceze. „Wir haben daraus eine Menge gelernt, aber die nächste natürliche Entwicklung besteht darin, einen vollständig verwalteten Rechendienst zu haben, der all das abstrahiert [ML infrastructure] weg.“
Bildnachweis: OctoML
Mit OctoAI entscheiden Benutzer einfach, was sie priorisieren möchten (z. B. Latenz vs. Kosten), und OctoAI wählt automatisch die richtige Hardware für sie aus. Der Dienst optimiert diese Modelle außerdem automatisch (was zu zusätzlichen Kosteneinsparungen und Leistungssteigerungen führt) und entscheidet, ob es am besten ist, sie auf Nvidia-GPUs oder den Inferentia-Maschinen von AWS auszuführen. Dadurch wird die Komplexität der Produktion von Modellen erheblich verringert, was für viele ML-Projekte immer noch oft ein Hindernis darstellt. Wer die volle Kontrolle über den Betrieb seiner Modelle haben möchte, kann natürlich auch eigene Parameter festlegen und entscheiden, auf welcher Hardware sie laufen sollen. Ceze glaubt jedoch, dass sich die meisten Benutzer dafür entscheiden werden, OctoAI all dies für sich erledigen zu lassen.
Bildnachweis: OctoML
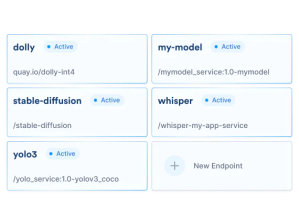
Es hilft auch, dass OctoML beschleunigte Versionen beliebter Foundation-Modelle wie Dolly 2, Whisper, FILM, FLAN-UL2 und Stable Diffusion sofort einsatzbereit bietet, weitere Modelle sind in Vorbereitung. OctoML hat es geschafft, Stable Diffusion zum Laufen zu bringen dreimal schneller und reduzieren Sie die Kosten um das Fünffache im Vergleich zum Betrieb des Vanilla-Modells.
Es ist erwähnenswert, dass OctoML zwar weiterhin mit bestehenden Kunden zusammenarbeiten wird, die den Service nur zur Optimierung ihrer Modelle nutzen möchten, der Fokus des Unternehmens jedoch künftig auf dieser neuen Rechenplattform liegen wird.