
Letzten Monat sagten KI-Gründer und -Investoren gegenüber Tech, dass wir uns jetzt in der „zweiten Ära der Skalierungsgesetze“ befänden, und stellten fest, dass etablierte Methoden zur Verbesserung von KI-Modellen sinkende Erträge zeigten. Eine vielversprechende neue Methode, mit der sie die Gewinne beibehalten könnten, sei die „Testzeitskalierung“, die offenbar der Grund für die Leistung des o3-Modells von OpenAI ist – aber auch Nachteile mit sich bringt.
Ein Großteil der KI-Welt betrachtete die Ankündigung des o3-Modells von OpenAI als Beweis dafür, dass der KI-Skalierungsfortschritt nicht „an eine Wand gestoßen“ ist. Das o3-Modell schneidet bei Benchmarks gut ab, übertrifft alle anderen Modelle bei einem allgemeinen Fähigkeitstest namens ARC-AGI deutlich und erreicht 25 % bei a schwieriger Mathetest dass kein anderes KI-Modell mehr als 2 % erreichte.
Natürlich nehmen wir bei Tech das alles mit Vorsicht, bis wir o3 selbst testen können (bisher haben es nur sehr wenige ausprobiert). Doch schon vor der Veröffentlichung von o3 ist die KI-Welt davon überzeugt, dass sich etwas Großes verändert hat.
Noam Brown, Mitschöpfer der O-Serie von OpenAI-Modellen, stellte am Freitag fest, dass das Startup die beeindruckenden Zuwächse von o3 nur drei Monate nach der Ankündigung von o1 bekannt gibt – ein relativ kurzer Zeitrahmen für einen solchen Leistungssprung.
„Wir haben allen Grund zu der Annahme, dass sich dieser Trend fortsetzen wird“, sagte Brown in einem twittern.
Anthropic-Mitbegründer Jack Clark sagte in einem Blogbeitrag am Montag, dass o3 ein Beweis dafür ist, dass die KI „im Jahr 2025 schnellere Fortschritte machen wird als im Jahr 2024“. (Denken Sie daran, dass es Anthropic zugute kommt – insbesondere seiner Fähigkeit, Kapital zu beschaffen –, wenn man annimmt, dass die KI-Skalierungsgesetze fortbestehen, auch wenn Clark einen Konkurrenten ergänzt.)
Laut Clark wird die KI-Welt im nächsten Jahr Testzeitskalierung und traditionelle Skalierungsmethoden vor dem Training miteinander verbinden, um noch mehr Rendite aus KI-Modellen herauszuholen. Vielleicht schlägt er vor, dass Anthropic und andere Anbieter von KI-Modellen im Jahr 2025 eigene Argumentationsmodelle veröffentlichen werden, genau wie Google es letzte Woche getan hat.
Die Skalierung der Testzeit bedeutet, dass OpenAI während der Inferenzphase von ChatGPT, dem Zeitraum, nachdem Sie bei einer Eingabeaufforderung die Eingabetaste gedrückt haben, mehr Rechenleistung verbraucht. Es ist nicht genau klar, was sich hinter den Kulissen abspielt: OpenAI verwendet entweder mehr Computerchips, um die Frage eines Benutzers zu beantworten, führt leistungsfähigere Inferenzchips aus oder lässt diese Chips über längere Zeiträume – in manchen Fällen 10 bis 15 Minuten – laufen, bevor die Frage eines Benutzers beantwortet wird KI liefert eine Antwort. Wir kennen nicht alle Details darüber, wie o3 erstellt wurde, aber diese Benchmarks sind erste Anzeichen dafür, dass die Skalierung der Testzeit die Leistung von KI-Modellen verbessern könnte.
Während o3 einige zu neuem Glauben an den Fortschritt der KI-Skalierungsgesetze erwecken mag, verwendet das neueste Modell von OpenAI auch ein bisher nicht dagewesenes Maß an Rechenleistung, was einen höheren Preis pro Antwort bedeutet.
„Der vielleicht einzige wichtige Vorbehalt besteht hier darin, zu verstehen, dass ein Grund, warum O3 so viel besser ist, darin besteht, dass die Ausführung zur Inferenzzeit mehr Geld kostet – die Möglichkeit, Berechnungen zur Testzeit zu nutzen, bedeutet, dass man bei einigen Problemen Berechnungen in eine bessere Antwort umwandeln kann.“ “, schreibt Clark in seinem Blog. „Das ist interessant, weil dadurch die Kosten für den Betrieb von KI-Systemen etwas weniger vorhersehbar geworden sind – früher konnte man die Kosten für die Bereitstellung eines generativen Modells einfach durch einen Blick auf das Modell und die Kosten für die Generierung einer bestimmten Ausgabe ermitteln.“
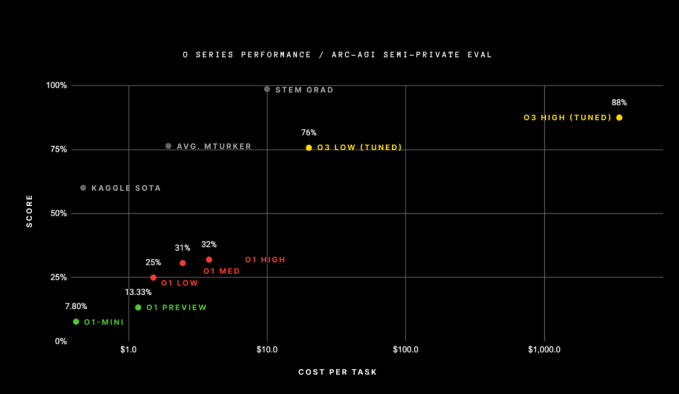
Clark und andere verwiesen auf die Leistung von o3 beim ARC-AGI-Benchmark – einem schwierigen Test zur Bewertung von Durchbrüchen bei AGI – als Indikator für seinen Fortschritt. Es ist erwähnenswert, dass das Bestehen dieses Tests laut seinen Erstellern kein KI-Modell bedeutet erreicht hat AGI, sondern vielmehr eine Möglichkeit, den Fortschritt in Richtung des nebulösen Ziels zu messen. Allerdings übertraf das o3-Modell die Ergebnisse aller vorherigen KI-Modelle, die den Test bestanden hatten, und erreichte in einem seiner Versuche 88 %. Das zweitbeste KI-Modell von OpenAI, o1, erzielte nur 32 %.
Aber die logarithmische x-Achse in diesem Diagramm könnte für einige alarmierend sein. Die Highscore-Version von o3 verbrauchte für jede Aufgabe Rechenleistung im Wert von über 1.000 US-Dollar. Die o1-Modelle verbrauchten etwa 5 US-Dollar an Rechenleistung pro Aufgabe, und o1-mini verbrauchte nur ein paar Cent.
Der Erfinder des ARC-AGI-Benchmarks, François Chollet, schreibt in einem Blog dass OpenAI etwa 170-mal mehr Rechenleistung benötigte, um diesen 88-Prozent-Wert zu erzielen, verglichen mit der hocheffizienten Version von o3, die nur 12 Prozent weniger Punkte erzielte. Die Version von o3 mit der höchsten Punktzahl verbrauchte mehr als 10.000 US-Dollar an Ressourcen, um den Test abzuschließen, was es zu teuer macht, um den ARC-Preis zu konkurrieren – ein ungeschlagener Wettbewerb für KI-Modelle, die den ARC-Test bestehen wollen.
Chollet sagt jedoch, dass o3 dennoch ein Durchbruch für KI-Modelle war.
„o3 ist ein System, das in der Lage ist, sich an Aufgaben anzupassen, mit denen es noch nie zuvor konfrontiert wurde, und im ARC-AGI-Bereich wohl an Leistung auf menschlichem Niveau herankommt“, sagte Chollet im Blog. „Natürlich ist eine solche Allgemeingültigkeit mit hohen Kosten verbunden und wäre noch nicht ganz wirtschaftlich: Sie könnten einen Menschen für die Lösung von ARC-AGI-Aufgaben für etwa 5 US-Dollar pro Aufgabe bezahlen (wir wissen, das haben wir getan), während Sie nur Cent verbrauchen an Energie.“
Es ist verfrüht, auf die genauen Preise für all das einzugehen – wir haben gesehen, dass die Preise für KI-Modelle im letzten Jahr stark gesunken sind, und OpenAI hat noch nicht bekannt gegeben, wie viel o3 tatsächlich kosten wird. Diese Preise zeigen jedoch, wie viel Rechenleistung erforderlich ist, um die Leistungsbarrieren, die heute von führenden KI-Modellen gesetzt werden, auch nur geringfügig zu durchbrechen.
Dies wirft einige Fragen auf. Wozu dient o3 eigentlich? Und wie viel mehr Rechenleistung ist erforderlich, um mit o4, o5 oder wie auch immer OpenAI seine nächsten Argumentationsmodelle nennt, mehr Fortschritte bei der Inferenz zu erzielen?
Es sieht nicht so aus, als ob o3 oder seine Nachfolger jedermanns „tägliche Treiber“ wären, wie es GPT-4o oder die Google-Suche sein könnten. Diese Modelle verbrauchen einfach zu viel Rechenleistung, um im Laufe des Tages kleine Fragen zu beantworten, wie zum Beispiel: „Wie können die Cleveland Browns es noch in die Playoffs 2024 schaffen?“
Stattdessen scheint es, als ob KI-Modelle mit skalierter Testzeitberechnung möglicherweise nur für Gesamtaufforderungen wie „Wie können die Cleveland Browns im Jahr 2027 ein Super Bowl-Franchise werden?“ geeignet sind. Selbst dann lohnen sich die hohen Rechenkosten vielleicht nur, wenn Sie der General Manager der Cleveland Browns sind und diese Tools verwenden, um wichtige Entscheidungen zu treffen.
Institutionen mit großen finanziellen Mitteln sind möglicherweise die einzigen, die sich zumindest für den Anfang o3 leisten können, wie Wharton-Professor Ethan Mollick in einem Artikel feststellt twittern.
Wir haben bereits gesehen, dass OpenAI eine 200-Dollar-Stufe veröffentlicht hat, um eine High-Computing-Version von o1 zu verwenden, aber das Startup hat es getan Berichten zufolge erwog er die Erstellung von Abonnementplänen, die bis zu 2.000 US-Dollar kosteten. Wenn Sie sehen, wie viel Rechenleistung o3 verbraucht, können Sie verstehen, warum OpenAI dies in Betracht zieht.
Die Verwendung von o3 für anspruchsvolle Arbeiten hat jedoch auch Nachteile. Wie Chollet anmerkt, ist o3 kein AGI und versagt dennoch bei einigen sehr einfachen Aufgaben, die ein Mensch problemlos erledigen würde.
Dies ist nicht unbedingt überraschend, da große Sprachmodelle immer noch ein großes Halluzinationsproblem haben, das o3 und die Testzeitberechnung offenbar nicht gelöst haben. Aus diesem Grund fügen ChatGPT und Gemini unter jeder von ihnen erstellten Antwort einen Haftungsausschluss ein und bitten die Benutzer, den Antworten nicht für bare Münze zu vertrauen. Vermutlich bräuchte AGI, sollte es jemals dazu kommen, einen solchen Haftungsausschluss nicht.
Eine Möglichkeit, weitere Fortschritte bei der Skalierung der Testzeit zu erzielen, könnten bessere KI-Inferenzchips sein. Es gibt keinen Mangel an Startups wie Groq oder Cerebras, die sich genau mit dieser Sache befassen, während andere Startups wie MatX kosteneffizientere KI-Chips entwickeln. Anjney Midha, General Partner von Andreessen Horowitz, sagte gegenüber Tech zuvor, er erwarte, dass diese Startups künftig eine größere Rolle bei der Testzeitskalierung spielen werden.
Obwohl o3 eine bemerkenswerte Verbesserung der Leistung von KI-Modellen darstellt, wirft es mehrere neue Fragen zu Nutzung und Kosten auf. Allerdings untermauert die Leistung von o3 die Behauptung, dass Testzeitberechnung die nächstbeste Methode der Technologiebranche zur Skalierung von KI-Modellen ist.