
Fragen Sie jeden in der Open-Source-KI-Community und er wird Ihnen sagen, dass die Kluft zwischen ihnen und den großen Privatunternehmen nicht nur in der Rechenleistung liegt. Ai2 arbeitet daran, dies zu beheben, zunächst mit vollständig Open-Source-Datenbanken und -Modellen und jetzt mit einem offenen und leicht anpassbaren Post-Training-Programm, um „rohe“ große Sprachmodelle (LLMs) in nutzbare Modelle umzuwandeln.
Im Gegensatz zu dem, was viele denken, kommen „Grundlagen“-Sprachmodelle nicht einsatzbereit aus dem Trainingsprozess. Der Vorschulungsprozess ist natürlich notwendig, aber bei weitem nicht ausreichend. Manche glauben sogar, dass die Vorschulung bald gar nicht mehr der wichtigste Teil sein könnte.
Denn der Post-Training-Prozess erweist sich zunehmend als der Ort, an dem echter Mehrwert geschaffen werden kann. Hier wird das Modell aus einem riesigen Besserwisser-Netzwerk geformt, das ebenso bereitwillig Gesprächsthemen zur Holocaust-Leugnung hervorbringt wie Keksrezepte. Das will man generell nicht!
Unternehmen halten ihre Post-Training-Programme geheim, denn während jeder das Internet durchstöbern und mit modernsten Methoden ein Modell erstellen kann, ist es eine ganz andere Herausforderung, dieses Modell beispielsweise für einen Therapeuten oder Forschungsanalytiker nutzbar zu machen.
Ai2 (früher bekannt als Allen Institute for AI) hat sich über den Mangel an Offenheit in vermeintlich „offenen“ KI-Projekten wie Metas Llama geäußert. Während das Modell tatsächlich von jedermann kostenlos verwendet und optimiert werden kann, bleiben die Quellen und der Prozess zur Erstellung des Rohmodells sowie die Methode, es für den allgemeinen Gebrauch zu trainieren, sorgfältig gehütete Geheimnisse. Es ist nicht schlecht – aber es ist auch nicht wirklich „offen“.
Ai2 hingegen ist bestrebt, so offen wie möglich zu sein, von der Offenlegung seiner Datenerfassung, Kuration, Bereinigung und anderen Pipelines bis hin zu den genauen Trainingsmethoden, die es zur Erstellung von LLMs wie OLMo verwendet hat.
Aber die einfache Wahrheit ist, dass nur wenige Entwickler das Zeug dazu haben, ihre eigenen LLMs zu starten, und noch weniger können das Post-Training so durchführen, wie es Meta, OpenAI oder Anthropic tun – teils, weil sie nicht wissen, wie, aber auch, weil es ist technisch komplex und zeitaufwändig.
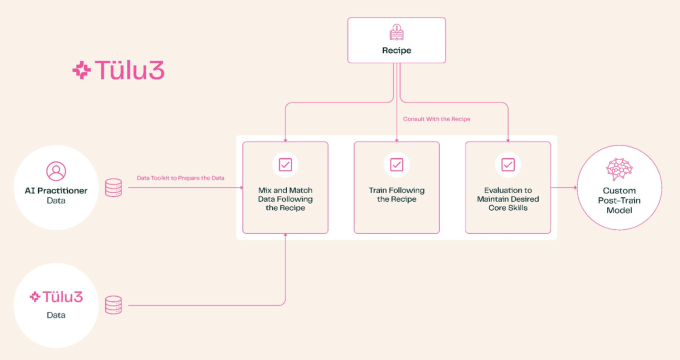
Glücklicherweise möchte Ai2 auch diesen Aspekt des KI-Ökosystems demokratisieren. Hier kommt Tülu 3 ins Spiel. Es ist eine enorme Verbesserung gegenüber einem früheren, rudimentäreren Post-Training-Prozess (genannt, Sie haben es erraten, Tülu 2). In den Tests der gemeinnützigen Organisation ergab dies Ergebnisse, die mit den fortschrittlichsten „offenen“ Modellen auf dem Markt vergleichbar waren. Es basiert auf monatelangem Experimentieren, Lesen und Interpretieren der Andeutungen der Großen sowie vielen iterativen Trainingsläufen.
Im Grunde deckt Tülu 3 alles ab, von der Auswahl der Themen, die Ihr Modell berücksichtigen soll – zum Beispiel das Herunterspielen von Mehrsprachigkeitsfunktionen, aber die Aufwertung von Mathematik und Codierung – bis hin zur Durchführung eines langen Programms aus Datenkuratierung, Verstärkungslernen, Feinabstimmung und Präferenzen Tuning, bis hin zur Optimierung einer Reihe anderer Metaparameter und Trainingsprozesse, die ich Ihnen nicht ausreichend beschreiben konnte. Das Ergebnis ist hoffentlich ein weitaus leistungsfähigeres Modell, das sich auf die Fähigkeiten konzentriert, die Sie benötigen.
Der eigentliche Sinn besteht jedoch darin, ein weiteres Spielzeug aus der Spielzeugkiste der Privatunternehmen herauszuholen. Wenn Sie bisher ein individuell geschultes LLM aufbauen wollten, war es sehr schwer zu vermeiden, die Ressourcen eines großen Unternehmens auf die eine oder andere Weise zu nutzen oder einen Mittelsmann zu engagieren, der die Arbeit für Sie erledigte. Das ist nicht nur teuer, sondern birgt auch Risiken, die manche Unternehmen ungern eingehen.
Zum Beispiel medizinische Forschungs- und Dienstleistungsunternehmen: Sicher, Sie könnten die API von OpenAI verwenden oder mit Scale oder wem auch immer sprechen, um ein internes Modell anzupassen, aber beides bezieht externe Unternehmen in sensible Benutzerdaten ein. Wenn es unvermeidbar ist, müssen Sie einfach in den sauren Apfel beißen – aber wenn nicht? Zum Beispiel, wenn eine Forschungsorganisation ein Programm vor und nach dem Training veröffentlichen würde, das Sie vor Ort umsetzen könnten? Das könnte durchaus eine bessere Alternative sein.
Ai2 nutzt dies selbst, was die beste Bestätigung ist, die man geben kann. Auch wenn die heute veröffentlichten Testergebnisse Llama als Basismodell verwenden, planen sie, bald ein OLMo-basiertes, Tülu 3-trainiertes Modell herauszubringen, das noch mehr Verbesserungen gegenüber der Basislinie bieten und außerdem vollständig Open Source sein soll, Tipp zum Schwanz.
Wenn Sie neugierig sind, wie das Modell derzeit funktioniert, Probieren Sie die Live-Demo aus.