
Die generative KI-Landschaft wird von Tag zu Tag größer.
Meta hat heute eine neue Familie von KI-Modellen angekündigt. Lama 2, entwickelt, um Apps wie ChatGPT von OpenAI, Bing Chat und andere moderne Chatbots zu betreiben. Basierend auf einer Mischung öffentlich verfügbarer Daten behauptet Meta, dass sich die Leistung von Llama 2 im Vergleich zur vorherigen Generation von Llama-Modellen erheblich verbessert.
Llama 2 ist der Nachfolger von Llama – einer Sammlung von Modellen, die als Reaktion auf Eingabeaufforderungen Text und Code generieren können, vergleichbar mit anderen Chatbot-ähnlichen Systemen. Aber Lama war nur auf Anfrage erhältlich; Aus Angst vor Missbrauch beschloss Meta, den Zugang zu den Modellen zu sperren. (Trotz dieser Vorsichtsmaßnahme gelangte Llama später ins Internet und verbreitete sich in verschiedenen KI-Gemeinschaften.)
Im Gegensatz dazu wird Llama 2 – das für Forschung und kommerzielle Nutzung kostenlos ist – zur Feinabstimmung auf AWS, Azure und der KI-Modell-Hosting-Plattform von Hugging Face in vortrainierter Form verfügbar sein. Und es wird einfacher zu bedienen sein, sagt Meta – optimiert für Windows dank einer erweiterten Partnerschaft mit Microsoft sowie Smartphones und PCs mit Qualcomms Snapdragon-System-on-Chip. (Qualcomm sagt, dass man daran arbeitet, Llama 2 im Jahr 2024 auf Snapdragon-Geräte zu bringen.)
Wie unterscheidet sich Llama 2 von Llama? In vielerlei Hinsicht hebt Meta sie alle ausführlich hervor weißes Papier.
Llama 2 gibt es in zwei Varianten: Llama 2 und Llama 2-Chat, wobei letztere speziell auf Zwei-Wege-Gespräche abgestimmt wurde. Llama 2 und Llama 2-Chat sind weiter in Versionen unterschiedlicher Komplexität unterteilt: 7 Milliarden Parameter, 13 Milliarden Parameter und 70 Milliarden Parameter. („Parameter“ sind die Teile eines Modells, die aus Trainingsdaten gelernt wurden und im Wesentlichen die Fähigkeit des Modells für ein Problem definieren, in diesem Fall die Textgenerierung.)
Llama 2 wurde mit zwei Millionen Token trainiert, wobei „Token“ Rohtext darstellen – z. B. „fan“, „tas“ und „tic“ für das Wort „fantastisch“. Das sind fast doppelt so viele, wie Llama trainiert wurde (1,4 Billionen), und – allgemein gesagt – je mehr Token, desto besser, wenn es um generative KI geht. Googles aktuelles Flaggschiff-Large-Language-Modell (LLM), PaLM 2, war angeblich wurde auf 3,6 Millionen Token trainiert, und es wird spekuliert, dass GPT-4 auch auf Billionen von Token trainiert wurde.
Meta gibt die spezifischen Quellen der Trainingsdaten im Whitepaper nicht preis, außer dass sie aus dem Internet stammen, meist auf Englisch, und nicht von den eigenen Produkten oder Dienstleistungen des Unternehmens, und betont den Text „sachlicher“ Natur.
Ich wage zu vermuten, dass die Zurückhaltung, Trainingsdetails preiszugeben, nicht nur auf Wettbewerbsgründen beruht, sondern auch auf den rechtlichen Kontroversen rund um generative KI. Erst heute haben Tausende von Autoren einen Brief unterzeichnet, in dem sie Technologieunternehmen auffordern, ihre Texte nicht mehr ohne Erlaubnis oder Entschädigung für das Training von KI-Modellen zu verwenden.
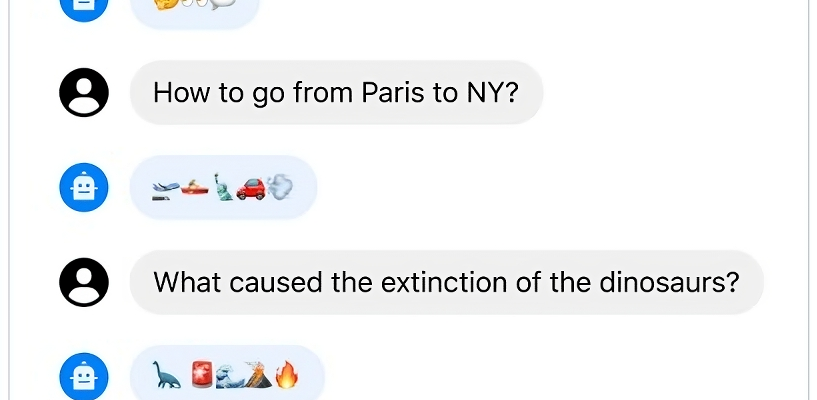
Aber ich schweife ab. Laut Meta schneiden die Llama-2-Modelle in einer Reihe von Benchmarks etwas schlechter ab als die bekanntesten Closed-Source-Konkurrenten GPT-4 und PaLM 2, wobei Llama 2 bei der Computerprogrammierung deutlich hinter GPT-4 zurückbleibt. Aber menschliche Bewerter finden Llama 2 ungefähr so „hilfreich“ wie ChatGPT, behauptet Meta; Lama 2 beantwortete eine Reihe von rund 4.000 Fragen, die darauf abzielten, nach „Hilfsbereitschaft“ und „Sicherheit“ zu fragen, gleichwertig.
Die Llama 2-Modelle von Meta können Fragen beantworten – in Emoji. Bildnachweis: Meta
Nehmen Sie die Ergebnisse jedoch mit Vorsicht. Meta räumt ein, dass seine Tests unmöglich jedes reale Szenario abbilden können und dass es seinen Benchmarks möglicherweise an Diversität mangelt – mit anderen Worten, dass sie Bereiche wie Codierung und menschliches Denken nicht ausreichend abdecken.
Meta gibt auch zu, dass Llama 2, wie alle generativen KI-Modelle, Vorurteile entlang bestimmter Achsen aufweist. Aufgrund von Ungleichgewichten in den Trainingsdaten besteht beispielsweise die Gefahr, dass „er“-Pronomen häufiger generiert werden als „sie“-Pronomen. Aufgrund des toxischen Texts in den Trainingsdaten übertrifft es andere Modelle bei Toxizitäts-Benchmarks nicht. Und Lama 2 hat eine westliche Ausrichtung, wiederum dank Datenungleichgewichten, einschließlich einer Fülle von Wörtern „Christ“, „Katholik“ und „Jüdisch“.
Die Llama 2-Chat-Modelle schneiden bei den internen „Hilfsbereitschafts“- und Toxizitäts-Benchmarks von Meta besser ab als die Llama 2-Modelle. Aber sie neigen auch dazu, übervorsichtig zu sein, und die Models neigen dazu, bestimmte Anfragen abzulehnen oder mit zu vielen Sicherheitsdetails zu antworten.
Fairerweise muss man sagen, dass die Benchmarks keine zusätzlichen Sicherheitsebenen berücksichtigen, die möglicherweise auf gehostete Llama 2-Modelle angewendet werden. Im Rahmen der Zusammenarbeit mit Microsoft nutzt Meta beispielsweise Azure AI Content Safety, einen Dienst, der darauf ausgelegt ist, „unangemessene“ Inhalte in KI-generierten Bildern und Texten zu erkennen, um schädliche Llama-2-Ausgaben auf Azure zu reduzieren.
Vor diesem Hintergrund unternimmt Meta immer noch alle Anstrengungen, um sich von potenziell schädlichen Folgen im Zusammenhang mit Llama 2 zu distanzieren, und betont im Whitepaper, dass Benutzer von Llama 2 die Lizenzbedingungen und Richtlinien zur akzeptablen Nutzung von Meta sowie Richtlinien zur „sicheren Entwicklung“ einhalten müssen Einsatz.“
„Wir glauben, dass der offene Austausch der heutigen großen Sprachmodelle auch die Entwicklung einer hilfreichen und sichereren generativen KI unterstützen wird“, schreibt Meta in einem Blogbeitrag. „Wir freuen uns darauf zu sehen, was die Welt mit Llama 2 baut.“
Angesichts der Natur von Open-Source-Modellen lässt sich jedoch nicht genau sagen, wie und wo die Modelle verwendet werden könnten. Angesichts der rasanten Geschwindigkeit, mit der sich das Internet bewegt, wird es nicht lange dauern, bis wir es herausfinden.