
Meta hat bestätigt dass das Unternehmen seine Pläne, mit dem Training seiner KI-Systeme mithilfe von Daten seiner Nutzer in der Europäischen Union und im Vereinigten Königreich zu beginnen, pausieren wird
Der Schritt folgte dem Widerstand der irischen Datenschutzkommission (DPC), Metas wichtigster Regulierungsbehörde in der EU, die im Auftrag mehrerer Datenschutzbehörden im gesamten Block handelt. Das britische Information Commissioner’s Office (ICO) auch angefordert Meta solle seine Pläne auf Eis legen, bis die von ihm geäußerten Bedenken ausgeräumt seien.
„Der DPC begrüßt die Entscheidung von Meta, seine Pläne zur Schulung seines großen Sprachmodells mit öffentlichen Inhalten, die von Erwachsenen auf Facebook und Instagram in der gesamten EU/EWR geteilt werden, auszusetzen“, sagte der DPC in einem Stellungnahme Freitag. „Diese Entscheidung folgte einer intensiven Zusammenarbeit zwischen dem DPC und Meta. Der DPC wird in Zusammenarbeit mit den anderen EU-Datenschutzbehörden weiterhin mit Meta in dieser Angelegenheit zusammenarbeiten.“
Während Meta in Märkten wie den USA bereits benutzergenerierte Inhalte nutzt, um seine KI zu trainieren, stellen die strengen DSGVO-Vorschriften in Europa Hindernisse für Meta – und andere Unternehmen – dar, die ihre KI-Systeme, darunter große Sprachmodelle, mit benutzergeneriertem Trainingsmaterial verbessern möchten.
Meta begann jedoch, Benutzer über eine bevorstehende Änderung Im vergangenen Monat hat das Unternehmen seine Datenschutzrichtlinie geändert. Es soll dem Unternehmen das Recht einräumen, öffentliche Inhalte auf Facebook und Instagram zu verwenden, um seine KI zu trainieren. Dazu gehören Inhalte aus Kommentaren, Interaktionen mit Unternehmen, Statusaktualisierungen, Fotos und die dazugehörigen Bildunterschriften. Das Unternehmen argumentierte, dass dies notwendig sei um „die sprachliche Vielfalt, die geografische Lage und die kulturellen Besonderheiten der Menschen in Europa“ widerzuspiegeln.
Diese Änderungen sollten am 26. Juni 2024 in Kraft treten – also in 12 Tagen. Aber die Pläne angespornt gemeinnützige Datenschutz-Aktivistenorganisation NOYB („geht Sie nichts an“), 11 Beschwerden bei EU-Mitgliedstaaten einzureichen, mit der Begründung, dass Meta gegen verschiedene Aspekte der DSGVO verstößt. Eine davon betrifft die Frage von Opt-in versus Opt-out. gegenüber Wenn eine Verarbeitung personenbezogener Daten stattfindet, sollte der Benutzer zunächst um seine Erlaubnis gebeten werden, anstatt eine Ablehnung durch Maßnahmen zu verlangen.
Meta wiederum berief sich auf eine DSGVO-Bestimmung namens „legitime Interessen“, um zu behaupten, dass seine Handlungen den Vorschriften entsprächen. Dies ist nicht das erste Mal, dass Meta diese Rechtsgrundlage zu seiner Verteidigung heranzieht. Zuvor hatte das Unternehmen dies bereits getan, um die Verarbeitung der Daten europäischer Nutzer für gezielte Werbung zu rechtfertigen.
Es schien immer wahrscheinlich, dass die Regulierungsbehörden zumindest einen Aufschub der Umsetzung der geplanten Änderungen von Meta erwirken würden, insbesondere angesichts der Tatsache, wie schwierig das Unternehmen es seinen Benutzern gemacht hatte, der Verwendung ihrer Daten zu widersprechen. Das Unternehmen gab an, mehr als 2 Milliarden Benachrichtigungen verschickt zu haben, um die Benutzer über die bevorstehenden Änderungen zu informieren. Im Gegensatz zu anderen wichtigen öffentlichen Nachrichten, die oben in den Feeds der Benutzer angezeigt werden, wie z. B. Aufforderungen, wählen zu gehen, erschienen diese Benachrichtigungen jedoch neben den Standardbenachrichtigungen der Benutzer – Geburtstagen von Freunden, Foto-Tag-Benachrichtigungen, Gruppenankündigungen und mehr. Wenn jemand seine Benachrichtigungen also nicht regelmäßig überprüft, konnte er dies nur allzu leicht übersehen.
Und diejenigen, die die Benachrichtigung gesehen haben, wussten nicht automatisch, dass es eine Möglichkeit gab, Einspruch zu erheben oder sich abzumelden, da die Benutzer lediglich aufgefordert wurden, durchzuklicken, um herauszufinden, wie Meta ihre Informationen verwendet. Nichts deutete darauf hin, dass es hier eine Wahl gab.
Darüber hinaus war es den Nutzern technisch nicht möglich, der Nutzung ihrer Daten zu widersprechen. Stattdessen mussten sie ein Widerspruchsformular ausfüllen, in dem sie ihre Argumente darlegten, warum sie die Verarbeitung ihrer Daten nicht wollten. Es lag ganz im Ermessen von Meta, ob dieser Anfrage entsprochen wurde, obwohl das Unternehmen zusagte, jeder Anfrage nachzukommen.
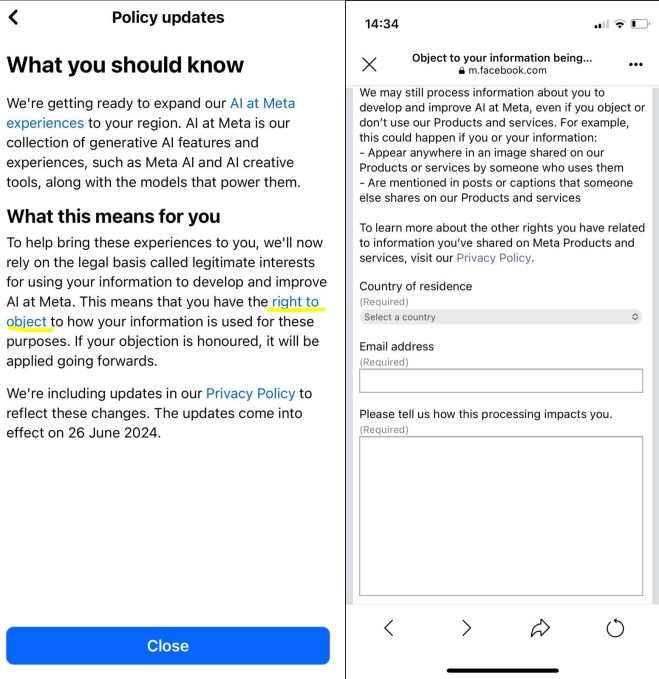
Zwar war in der Benachrichtigung selbst ein Link zum Widerspruchsformular enthalten, wer jedoch proaktiv in seinen Kontoeinstellungen nach dem Widerspruchsformular suchte, hatte keine große Mühe.
Auf der Facebook-Website mussten sie zuerst auf ihre Profilfoto oben rechts; drücke Einstellungen & Datenschutz; klopfen Datenschutzzentrum; scrollen Sie nach unten und klicken Sie auf das Generative KI bei Meta Abschnitt; scrollen Sie erneut nach unten, vorbei an einer Reihe von Links zu einem Abschnitt mit dem Titel mehr Ressourcen. Der erste Link in diesem Abschnitt heißt „Wie Meta Informationen für generative KI-Modelle verwendet”, und sie mussten etwa 1.100 Wörter lesen, bevor sie zu einem diskreten Link zum „Widerspruchsrecht“-Formular des Unternehmens gelangten. In der mobilen App von Facebook war es ähnlich.
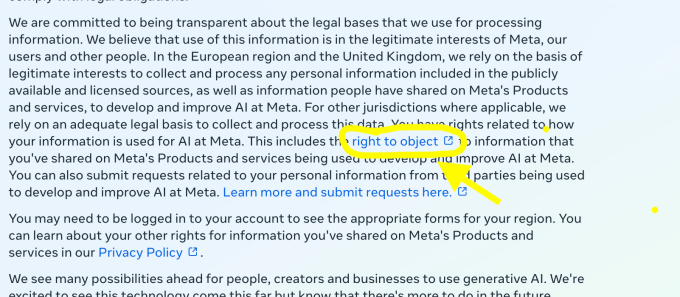
Anfang dieser Woche wurde Metas Policy Communications Manager gefragt, warum dieser Prozess einen Einspruch und kein Opt-in erforderte. Matt Pollard verwies Tech auf seine bestehender Blogbeitragin der es heißt: „Wir glauben, dass diese Rechtsgrundlage [“legitimate interests”] ist der beste Ausgleich für die Verarbeitung öffentlicher Daten in dem für das Training von KI-Modellen erforderlichen Umfang, unter gleichzeitiger Wahrung der Rechte der Menschen.“
Um dies zu übersetzen: Die Möglichkeit, diese Einwilligung zu geben, würde wahrscheinlich nicht genügend „Größenordnung“ in Bezug auf Personen schaffen, die bereit sind, ihre Daten preiszugeben. Die beste Lösung bestand also darin, eine einzelne Benachrichtigung neben den anderen Benachrichtigungen der Benutzer auszugeben, das Widerspruchsformular hinter einem halben Dutzend Klicks für diejenigen zu verbergen, die unabhängig voneinander die Einwilligung zum „Opt-out“ wünschen, und sie dann ihren Widerspruch begründen zu lassen, anstatt ihnen eine direkte Einwilligung zum Opt-out zu geben.
In einem (n aktualisierter Blogbeitrag Stefano Fratta, Global Engagement Director für Datenschutz bei Meta, äußerte heute seine „Enttäuschung“ über die Anfrage, die es vom DPC erhalten habe.
„Dies ist ein Rückschritt für europäische Innovation und den Wettbewerb in der KI-Entwicklung und eine weitere Verzögerung bei der Bereitstellung der Vorteile der KI für die Menschen in Europa“, schrieb Fratta. „Wir sind weiterhin sehr zuversichtlich, dass unser Ansatz den europäischen Gesetzen und Vorschriften entspricht. KI-Schulungen sind kein Alleinstellungsmerkmal unserer Dienstleistungen und wir sind transparenter als viele unserer Branchenkollegen.“
KI-Wettrüsten
Nichts davon ist natürlich neu, und Meta befindet sich in einem KI-Wettrüsten, das ein gewaltiges Schlaglicht auf das riesige Arsenal an Daten geworfen hat, das die Big Tech-Unternehmen über uns alle besitzen.
Anfang des Jahres gab Reddit bekannt, dass es in den kommenden Jahren einen Vertrag über 200 Millionen US-Dollar für die Lizenzierung seiner Daten an Unternehmen wie den ChatGPT-Hersteller OpenAI und GoogleUnd letzteres dieser Unternehmen muss bereits mit hohen Geldstrafen rechnen, weil es sich beim Training seiner generativen KI-Modelle auf urheberrechtlich geschützte Nachrichteninhalte stützt.
Diese Bemühungen zeigen jedoch auch, wie weit Unternehmen gehen, um sicherzustellen, dass sie diese Daten im Rahmen der bestehenden Gesetzgebung nutzen können – eine Einwilligung zur Teilnahme steht selten auf der Tagesordnung, und der Prozess der Ablehnung ist oft unnötig mühsam. Erst letzten Monat entdeckte jemand eine zweifelhafte Formulierung in einer bestehenden Datenschutzrichtlinie von Slack, die darauf hindeutete, dass das Unternehmen Benutzerdaten zum Trainieren seiner KI-Systeme nutzen könnte, wobei Benutzer nur per E-Mail an das Unternehmen widersprechen könnten.
Und im vergangenen Jahr gab Google Online-Publishern endlich die Möglichkeit, ihre Websites von der Schulung seiner Modelle auszuschließen, indem sie einen Code in ihre Websites einfügen konnten. OpenAI wiederum entwickelt ein spezielles Tool, mit dem Content-Ersteller die Schulung seiner generativen KI-Intelligenz ablehnen können – dies sollte bis 2025 verfügbar sein.
Während Metas Versuche, seine KI anhand öffentlicher Inhalte der Benutzer in Europa zu trainieren, derzeit auf Eis liegen, werden sie nach Rücksprache mit DPC und ICO wahrscheinlich in anderer Form wieder auftauchen – hoffentlich mit einem anderen Benutzerberechtigungsprozess im Schlepptau.
„Um das Beste aus generativer KI und den damit verbundenen Möglichkeiten herauszuholen, ist es entscheidend, dass die Öffentlichkeit darauf vertrauen kann, dass ihre Datenschutzrechte von Anfang an respektiert werden“, sagte Stephen Almond, der Exekutivdirektor des ICO für regulatorische Risiken, in einem Erklärung heute„Wir werden die wichtigsten Entwickler generativer KI, einschließlich Meta, weiterhin beobachten, um die von ihnen getroffenen Sicherheitsvorkehrungen zu überprüfen und sicherzustellen, dass die Informationsrechte der britischen Benutzer geschützt sind.“