

Willkommen bei Perceptron, TechCrunchs wöchentlicher Zusammenfassung von KI-Nachrichten und -Forschung aus der ganzen Welt. Maschinelles Lernen ist heute in praktisch jeder Branche eine Schlüsseltechnologie, und es passiert viel zu viel, als dass irgendjemand mit allem Schritt halten könnte. Diese Kolumne zielt darauf ab, einige der interessantesten jüngsten Entdeckungen und Artikel auf dem Gebiet der künstlichen Intelligenz zu sammeln – und zu erklären, warum sie wichtig sind.
(Früher bekannt als Deep Science; frühere Ausgaben finden Sie hier.)
Die Zusammenfassung dieser Woche beginnt mit zwei zukunftsweisenden Studien von Facebook/Meta. Das erste ist eine Zusammenarbeit mit der University of Illinois in Urbana-Champaign, die darauf abzielt, die Menge der Emissionen aus der Betonproduktion zu reduzieren. Beton macht etwa 8 Prozent der Kohlenstoffemissionen aus, sodass uns selbst eine kleine Verbesserung helfen könnte, die Klimaziele zu erreichen.
Dies wird als „Slump-Test“ bezeichnet.
Was das Meta/UIUC-Team tat, war ein Modell mit über tausend Betonformeln zu trainieren, die sich in den Anteilen von Sand, Schlacke, gemahlenem Glas und anderen Materialien unterschieden (oben sehen Sie ein Musterstück von fotogenerem Beton). Durch das Auffinden der subtilen Trends in diesem Datensatz konnte eine Reihe neuer Formeln ausgegeben werden, die sowohl für die Festigkeit als auch für niedrige Emissionen optimiert wurden. Die Erfolgsformel stellte sich heraus, dass es 40 Prozent weniger Emissionen hatte als der regionale Standard und erfüllte … nun, etwas der Festigkeitsanforderungen. Es ist äußerst vielversprechend, und Folgestudien im Feld sollten den Ball bald wieder bewegen.
Die zweite Meta-Studie hat damit zu tun, wie Sprachmodelle funktionieren. Das Unternehmen möchte mit Experten für neuronale Bildgebung und anderen Forschern zusammenarbeiten, um zu vergleichen, wie Sprachmodelle bei ähnlichen Aufgaben mit der tatsächlichen Gehirnaktivität verglichen werden.
Sie interessieren sich insbesondere für die menschliche Fähigkeit, Wörter beim Sprechen oder Zuhören weit vor dem aktuellen zu antizipieren – etwa zu wissen, dass ein Satz auf eine bestimmte Weise enden wird oder dass ein „aber“ kommt. KI-Modelle werden sehr gut, aber sie funktionieren immer noch hauptsächlich, indem sie Wörter wie Legosteine einzeln hinzufügen und gelegentlich rückwärts schauen, um zu sehen, ob es Sinn macht. Sie fangen gerade erst an, aber sie haben es bereits getan einige interessante Ergebnisse.
Zurück zum Materialtipp: Forscher des Oak Ridge National Lab stürzen sich in den KI-Formulierungsspaß. Unter Verwendung eines Datensatzes aus quantenchemischen Berechnungen, was auch immer das sein mag, erstellte das Team ein neuronales Netzwerk, das Materialeigenschaften vorhersagen konnte – aber es dann so umkehrte, dass es möglich war Eigenschaften eingeben und Materialien vorschlagen lassen.
„Anstatt ein Material zu nehmen und seine gegebenen Eigenschaften vorherzusagen, wollten wir die idealen Eigenschaften für unseren Zweck auswählen und rückwärts arbeiten, um schnell und effizient mit einem hohen Maß an Vertrauen für diese Eigenschaften zu entwerfen. Das ist als inverses Design bekannt“, sagte Victor Fung vom ORNL. Es scheint funktioniert zu haben – aber Sie können es selbst überprüfen, indem Sie laufen den Code auf Github.
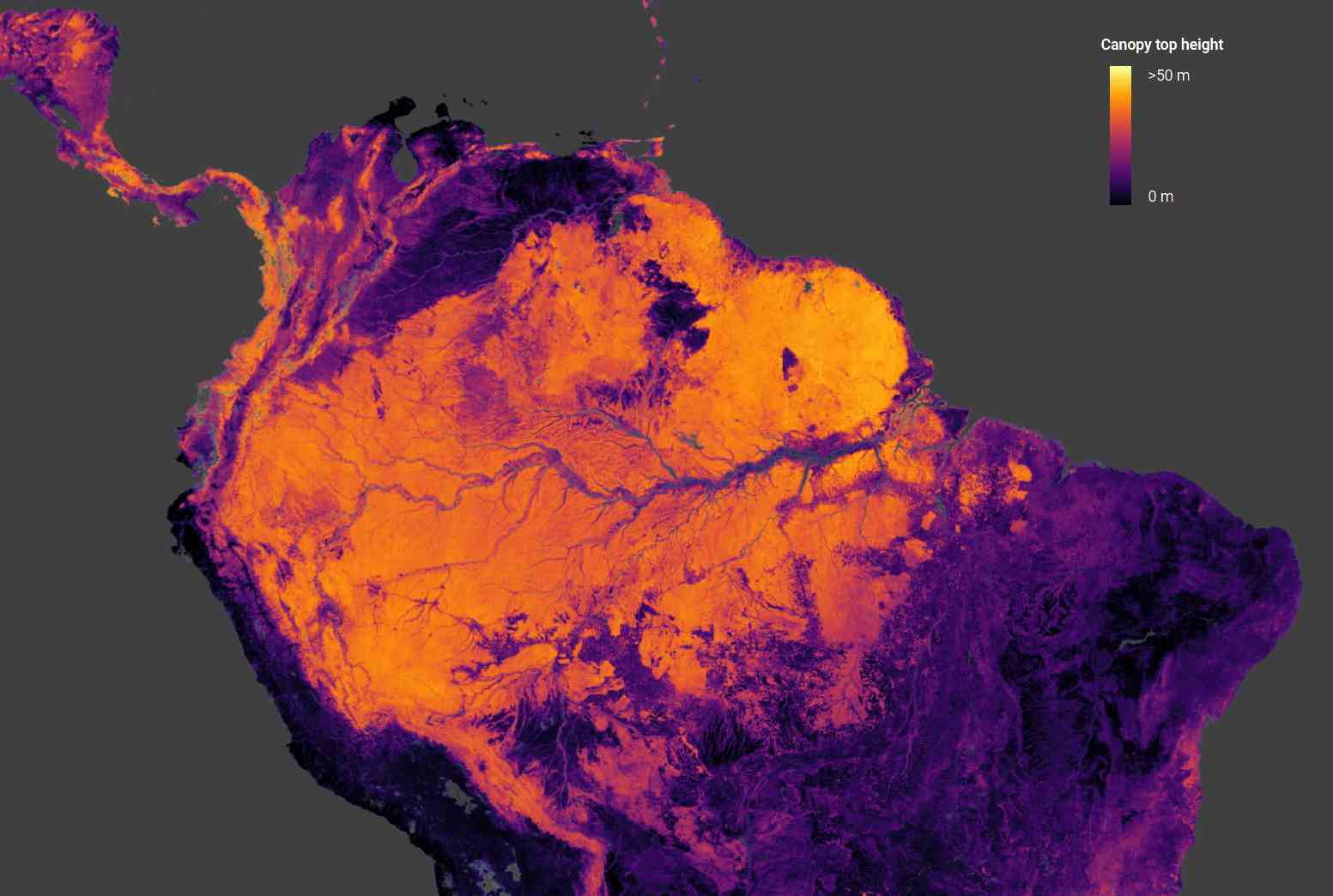
Bildnachweis: ETHZ
Beschäftigt mit physikalischen Vorhersagen in einem ganz anderen Maßstab, dieses ETHZ-Projekt schätzt die Höhe der Baumkronen auf der ganzen Welt anhand von Daten der Copernicus Sentinel-2-Satelliten der ESA (für optische Bilder) und GEDI (Orbital Laser Ranging) der NASA. Die Kombination der beiden in einem konvolutionellen neuronalen Netzwerk führt zu einer genauen globalen Karte von Baumhöhen von bis zu 55 Metern Höhe.
Eine solche regelmäßige Erfassung der Biomasse auf globaler Ebene ist wichtig für die Klimaüberwachung, wie Ralph Dubayah von der NASA erklärt: „Wir wissen einfach nicht, wie hoch Bäume weltweit sind. Wir brauchen gute globale Karten, wo Bäume sind. Denn wann immer wir Bäume fällen, setzen wir Kohlenstoff in die Atmosphäre frei, und wir wissen nicht, wie viel Kohlenstoff wir freisetzen.“
Sie können leicht Durchsuchen Sie die Daten in Kartenform hier.
Ebenfalls auf Landschaften bezogen ist dieses DARPA-Projekt, bei dem es darum geht, extrem groß angelegte simulierte Umgebungen zu schaffen, die von virtuellen autonomen Fahrzeugen durchquert werden können. Den Auftrag haben sie an Intel vergebenobwohl sie vielleicht etwas Geld gespart hätten, indem sie die Macher des Spiels kontaktiert hätten Schneeläuferdas im Grunde das tut, was DARPA für 30 US-Dollar will.

Bildnachweis: Intel
Das Ziel von RACER-Sim ist es, Offroad-AVs zu entwickeln, die bereits wissen, wie es ist, über eine felsige Wüste und anderes raues Gelände zu rumpeln. Das 4-Jahres-Programm konzentriert sich zunächst auf die Erstellung der Umgebungen, den Bau von Modellen im Simulator und später auf die Übertragung der Fähigkeiten auf physische Robotersysteme.
Im Bereich der KI-Pharmazeutika, die derzeit etwa 500 verschiedene Unternehmen umfasst, MIT hat einen vernünftigen Ansatz in einem Modell, das nur Moleküle vorschlägt, die tatsächlich hergestellt werden können. „Modelle suggerieren oft neue molekulare Strukturen, die im Labor nur schwer oder gar nicht herzustellen sind. Wenn ein Chemiker das Molekül nicht wirklich herstellen kann, können seine krankheitsbekämpfenden Eigenschaften nicht getestet werden.“
Sieht cool aus, aber geht es auch ohne Einhornpulver?
Das MIT-Modell „garantiert, dass Moleküle aus Materialien bestehen, die gekauft werden können, und dass die chemischen Reaktionen, die zwischen diesen Materialien stattfinden, den Gesetzen der Chemie folgen.“ Es klingt irgendwie wie das, was Molecule.one tut, aber in den Entdeckungsprozess integriert. Es wäre sicherlich schön zu wissen, dass das Wundermittel, das Ihre KI vorschlägt, keinen Feenstaub oder andere exotische Stoffe benötigt.
Eine weitere Arbeit des MIT, der University of Washington und anderer befasst sich damit, Robotern beizubringen, mit Alltagsgegenständen zu interagieren – etwas, von dem wir alle hoffen, dass es in den nächsten Jahrzehnten alltäglich wird, da einige von uns keine Spülmaschine haben. Das Problem ist, dass es sehr schwierig ist, genau zu sagen, wie Menschen mit Objekten interagieren, da wir unsere Daten nicht in hoher Genauigkeit weitergeben können, um damit ein Modell zu trainieren. Es sind also viele Datenanmerkungen und manuelle Beschriftungen erforderlich.
Die neue Technik konzentriert sich auf das genaue Beobachten und Ableiten von 3D-Geometrien, so dass es nur wenige Beispiele dafür braucht, wie eine Person ein Objekt ergreift, damit das System lernt, wie es selbst funktioniert. Normalerweise wären in einem Simulator Hunderte von Beispielen oder Tausende von Wiederholungen erforderlich, aber dieser benötigte nur 10 menschliche Demonstrationen pro Objekt, um dieses Objekt effektiv zu manipulieren.

Bildnachweis: MIT
Mit diesem minimalen Training erreichte es eine Erfolgsquote von 85 Prozent, viel besser als das Basismodell. Es ist derzeit auf eine Handvoll Kategorien beschränkt, aber die Forscher hoffen, dass es verallgemeinert werden kann.
Als letztes gibt es diese Woche einige vielversprechende Arbeit von Deepmind auf einem multimodalen „visuellen Sprachmodell“, das visuelles Wissen mit sprachlichem Wissen kombiniert, sodass Ideen wie „drei Katzen sitzen auf einem Zaun“ eine Art Crossover-Darstellung zwischen Grammatik und Bildsprache haben. So funktioniert schließlich unser eigener Verstand.
Flamingo, ihr neues „allgemeines“ Modell, kann sich visuell identifizieren, aber auch in Dialog treten, nicht weil es zwei Modelle in einem sind, sondern weil es Sprache und visuelles Verständnis miteinander verbindet. Wie wir von anderen Forschungsorganisationen gesehen haben, führt diese Art von multimodalem Ansatz zu guten Ergebnissen, ist aber immer noch sehr experimentell und rechenintensiv.