
Traditionell haben Unternehmen zum Schutz der Privatsphäre auf Datenmaskierung, manchmal auch Anonymisierung genannt, angewiesen. Die Grundidee besteht darin, alle personenbezogenen Daten (PII) aus jedem Datensatz zu entfernen. Eine Reihe hochkarätiger Vorfälle hat jedoch gezeigt, dass selbst vermeintlich anonymisierte Daten die Privatsphäre der Verbraucher preisgeben können.
1996 identifizierte ein MIT-Forscher die Gesundheitsakten des damaligen Gouverneurs von Massachusetts in einem angeblich maskierten Datensatz, indem er Gesundheitsakten mit öffentlichen Wählerregistrierungsdaten abgleichte. Im Jahr 2006 identifizierten Forscher von UT Austin Filme, die von Tausenden von Personen in einem angeblich anonymen Datensatz angesehen wurden, den Netflix veröffentlicht hatte, indem sie ihn mit Daten von IMDB kombinierten.
In einem 2022 Naturartikelverwendeten Forscher KI, um mehr als die Hälfte der Mobiltelefonaufzeichnungen in einem angeblich anonymen Datensatz mit Fingerabdrücken zu versehen und neu zu identifizieren. Diese Beispiele zeigen alle, wie „Nebeninformationen“ von Angreifern genutzt werden können, um vermeintlich maskierte Daten erneut zu identifizieren.
Diese Fehler führten zu differenzierte Privatsphäre. Anstatt Daten zu teilen, würden Unternehmen Datenverarbeitungsergebnisse in Kombination mit zufälligem Rauschen teilen. Der Rauschpegel ist so eingestellt, dass die Ausgabe einem potenziellen Angreifer nichts statistisch Signifikantes über ein Ziel sagt: Die gleiche Ausgabe könnte von einer Datenbank mit dem Ziel oder von genau derselben Datenbank, aber ohne das Ziel, stammen. Die Ergebnisse der gemeinsamen Datenverarbeitung geben keine Informationen über irgendjemanden preis, wodurch die Privatsphäre aller gewahrt bleibt.
Um die differenzielle Privatsphäre zu implementieren, sollte man nicht bei Null anfangen, da jeder Implementierungsfehler katastrophal für die Datenschutzgarantien sein könnte.
Die Operationalisierung der differenziellen Privatsphäre war in den frühen Tagen eine große Herausforderung. Die ersten Anwendungen waren vor allem von Organisationen mit großen Data-Science- und Engineering-Teams wie Apple, Google oder Microsoft hergeleitet. Wie können alle Organisationen mit modernen Dateninfrastrukturen den differenziellen Datenschutz in realen Anwendungen nutzen, wenn die Technologie ausgereifter wird und ihre Kosten sinken?
Der differenzielle Datenschutz gilt sowohl für aggregierte als auch für Daten auf Zeilenebene
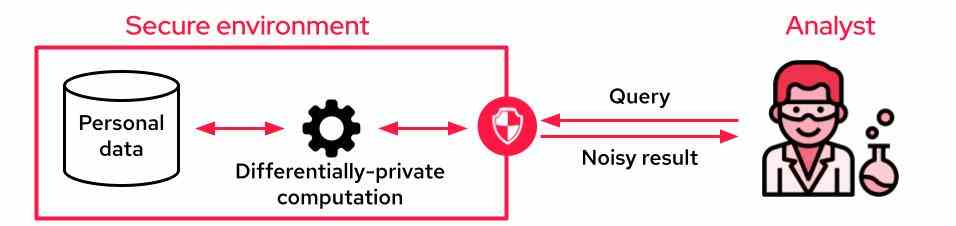
Wenn der Analyst nicht auf die Daten zugreifen kann, ist es üblich, Differential Privacy zu verwenden, um differentiell private Aggregate zu erstellen. Auf die sensiblen Daten kann über eine API zugegriffen werden, die nur verrauschte Ergebnisse ausgibt, die die Privatsphäre wahren. Diese API kann Aggregationen für den gesamten Datensatz durchführen, von einfachen SQL-Abfragen bis hin zu komplexen Schulungsaufgaben für maschinelles Lernen.
Ein typisches Setup zur Nutzung personenbezogener Daten mit unterschiedlichen Datenschutzgarantien. Bildnachweis: Sarus
Einer der Nachteile dieses Setups besteht darin, dass Analysten im Gegensatz zu Datenmaskierungstechniken keine einzelnen Datensätze mehr sehen, um „ein Gefühl für die Daten zu bekommen“. Eine Möglichkeit, diese Einschränkung zu mildern, besteht darin, differenziell private synthetische Daten bereitzustellen, bei denen der Dateneigentümer gefälschte Daten erstellt, die die statistischen Eigenschaften des ursprünglichen Datensatzes nachahmen.