
Unternehmen mögen OpenAI, Microsoft und Adobe sind gestartet KI-Chatbots die von bestimmten Arten von angetrieben werden große Sprachmodelle (LLMs), die eine Texteingabe in ein Bild umwandeln. Auch Google war mit von der Partie und hat nun mit der Veröffentlichung eines LLM namens „ VideoPoetdas kann sich drehen Text zu Videos.
Um die Fähigkeiten von VideoPoet zu demonstrieren, hat Google Research einen Kurzfilm produziert, der aus mehreren vom Modell generierten kurzen Clips besteht.
So funktioniert das VideoPoet-Modell
Google erklärt beispielsweise, dass Bard für das Drehbuch gebeten wurde, eine Reihe von Aufforderungen zu schreiben, um eine Kurzgeschichte über einen reisenden Waschbären detailliert darzustellen. Anschließend wurden für jede Eingabeaufforderung Videoclips erstellt, und nachdem das Modell alle resultierenden Clips zusammengefügt hatte, erstellte es einen endgültigen YouTube-Kurzfilm.
„VideoPoet ist eine einfache Modellierungsmethode, die jedes autoregressive Sprachmodell oder Large Language Model (LLM) in einen hochwertigen Videogenerator umwandeln kann“, sagte Google.
Es gibt einen vortrainierten MAGVIT V2-Video-Tokenizer und einen SoundStream-Audio-Tokenizer, die Bilder, Video- und Audioclips mit variabler Länge in eine Folge diskreter Codes in einem einheitlichen Vokabular umwandeln.
Diese Codes sind mit textbasierten Sprachmodellen kompatibel und erleichtern die Integration mit anderen Modalitäten, beispielsweise Text. Der LLM lernt Modalitäten, um das nächste Video- oder Audio-Token in der Sequenz vorherzusagen.
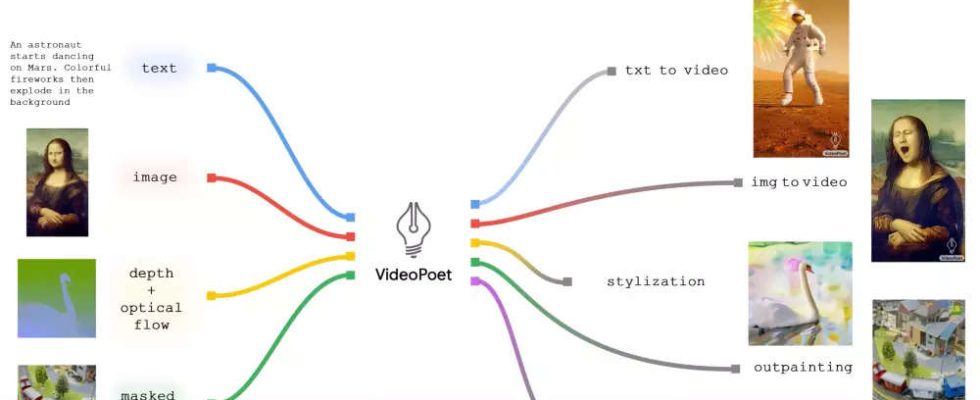
„In den LLM-Schulungsrahmen wird eine Mischung multimodaler generativer Lernziele eingeführt, darunter Text-zu-Video, Text-zu-Bild, Bild-zu-Video, Video-Frame-Fortsetzung, Video-Inpainting und -Outpainting, Videostilisierung und Video- to-audio“, sagte das Unternehmen und stellte fest, dass das Ergebnis ein KI-generiertes Video sei.
Laienhaft ausgedrückt verfügt VideoPoet über mehrere separat trainierte Komponenten für unterschiedliche Aufgaben, die in einem einzigen LLM integriert sind.
Um die Fähigkeiten von VideoPoet zu demonstrieren, hat Google Research einen Kurzfilm produziert, der aus mehreren vom Modell generierten kurzen Clips besteht.
So funktioniert das VideoPoet-Modell
Google erklärt beispielsweise, dass Bard für das Drehbuch gebeten wurde, eine Reihe von Aufforderungen zu schreiben, um eine Kurzgeschichte über einen reisenden Waschbären detailliert darzustellen. Anschließend wurden für jede Eingabeaufforderung Videoclips erstellt, und nachdem das Modell alle resultierenden Clips zusammengefügt hatte, erstellte es einen endgültigen YouTube-Kurzfilm.
„VideoPoet ist eine einfache Modellierungsmethode, die jedes autoregressive Sprachmodell oder Large Language Model (LLM) in einen hochwertigen Videogenerator umwandeln kann“, sagte Google.
Es gibt einen vortrainierten MAGVIT V2-Video-Tokenizer und einen SoundStream-Audio-Tokenizer, die Bilder, Video- und Audioclips mit variabler Länge in eine Folge diskreter Codes in einem einheitlichen Vokabular umwandeln.
Diese Codes sind mit textbasierten Sprachmodellen kompatibel und erleichtern die Integration mit anderen Modalitäten, beispielsweise Text. Der LLM lernt Modalitäten, um das nächste Video- oder Audio-Token in der Sequenz vorherzusagen.
„In den LLM-Schulungsrahmen wird eine Mischung multimodaler generativer Lernziele eingeführt, darunter Text-zu-Video, Text-zu-Bild, Bild-zu-Video, Video-Frame-Fortsetzung, Video-Inpainting und -Outpainting, Videostilisierung und Video- to-audio“, sagte das Unternehmen und stellte fest, dass das Ergebnis ein KI-generiertes Video sei.
Laienhaft ausgedrückt verfügt VideoPoet über mehrere separat trainierte Komponenten für unterschiedliche Aufgaben, die in einem einzigen LLM integriert sind.