
KI-Modelle, die Spiele spielen, gibt es seit Jahrzehnten, aber sie sind im Allgemeinen auf ein Spiel spezialisiert und spielen immer, um zu gewinnen. Google Deepmind-Forscher haben mit ihrer neuesten Kreation ein anderes Ziel: ein Modell, das gelernt hat, mehrere 3D-Spiele wie ein Mensch zu spielen, aber auch sein Bestes tut, um Ihre verbalen Anweisungen zu verstehen und entsprechend zu handeln.
Es gibt natürlich „KI“- oder Computercharaktere, die so etwas tun können, aber es handelt sich eher um Features eines Spiels: NPCs, die man über formale In-Game-Befehle indirekt steuern kann.
Der SIMA (Scalable Instructable Multiworld Agent) von Deepmind hat keinerlei Zugriff auf den internen Code oder die Regeln des Spiels. Stattdessen wurde es an vielen, vielen Stunden an Videos trainiert, die das Gameplay von Menschen zeigten. Anhand dieser Daten – und der von Datenbeschriftern bereitgestellten Anmerkungen – lernt das Modell, bestimmte visuelle Darstellungen von Aktionen, Objekten und Interaktionen zuzuordnen. Sie haben auch Videos von Spielern aufgenommen, die sich gegenseitig Anweisungen geben, Dinge im Spiel zu tun.
Aus der Art und Weise, wie sich die Pixel auf dem Bildschirm in einem bestimmten Muster bewegen, könnte es beispielsweise lernen, dass dies eine Aktion ist, die man „Vorwärtsbewegen“ nennt, oder wenn die Figur sich einem türähnlichen Objekt nähert und das Objekt benutzt, das wie ein Türknauf aussieht, ist das „Öffnen“. eine Tür.“ Einfache Dinge wie diese, Aufgaben oder Ereignisse, die ein paar Sekunden dauern, aber mehr sind als nur das Drücken einer Taste oder das Identifizieren von etwas.
Die Trainingsvideos wurden in mehreren Spielen aufgenommen, von Valheim bis Goat Simulator 3, deren Entwickler an dieser Verwendung ihrer Software beteiligt waren und dieser zustimmten. Eines der Hauptziele, sagten die Forscher in einem Gespräch mit der Presse, sei herauszufinden, ob das Training einer KI für das Spielen einer Reihe von Spielen sie dazu befähigt, andere Spiele zu spielen, die sie noch nicht gesehen hat, ein Prozess, der als Generalisierung bezeichnet wird.
Die Antwort lautet: Ja, mit Vorbehalten. KI-Agenten, die auf mehrere Spiele trainiert wurden, schnitten bei Spielen, denen sie noch nicht ausgesetzt waren, besser ab. Aber natürlich beinhalten viele Spiele spezifische und einzigartige Mechanismen oder Begriffe, die die am besten vorbereitete KI behindern. Aber nichts hindert das Modell daran, diese zu lernen, außer dem Mangel an Trainingsdaten.
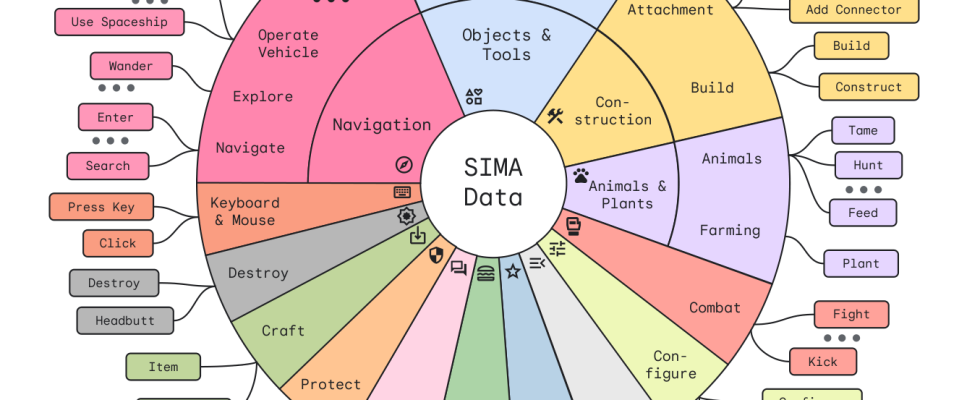
Das liegt zum Teil daran, dass es zwar viel Fachjargon im Spiel gibt, die Spieler jedoch nur eine begrenzte Anzahl von „Verben“ haben, die sich wirklich auf die Spielwelt auswirken. Ganz gleich, ob Sie einen Unterstand aufbauen, ein Zelt aufschlagen oder einen magischen Unterschlupf herbeirufen, Sie bauen tatsächlich „ein Haus“, oder? Daher ist es wirklich interessant, sich diese Karte mit mehreren Dutzend Grundelementen anzusehen, die der Agent derzeit erkennt:
Eine Karte mit mehreren Dutzend Aktionen, die SIMA erkennt und ausführen oder kombinieren kann.
Das Ziel der Forscher besteht nicht nur darin, die agentenbasierte KI grundlegend voranzutreiben, sondern auch darin, einen natürlicheren Spielbegleiter zu schaffen als die starren, hartcodierten, die wir heute haben.
„Anstatt einen übermenschlichen Agenten zu haben, gegen den Sie spielen, können Sie SIMA-Spieler an Ihrer Seite haben, die kooperativ sind und denen Sie Anweisungen geben können“, sagte Tim Harley, einer der Projektleiter.
Da sie beim Spielen nur die Pixel des Spielbildschirms sehen, müssen sie lernen, Dinge auf die gleiche Weise zu tun wie wir – aber das bedeutet auch, dass sie sich anpassen und neue Verhaltensweisen entwickeln können.
Sie sind vielleicht neugierig, wie sich dies im Vergleich zu einer gängigen Methode zur Herstellung agentenartiger KIs schlägt, dem Simulator-Ansatz, bei dem ein größtenteils unbeaufsichtigtes Modell wild in einer 3D-simulierten Welt experimentiert, die viel schneller als in Echtzeit läuft und es ihm ermöglicht, die Regeln intuitiv zu lernen und Designverhalten um sie herum ohne annähernd so viel Anmerkungsarbeit.
„Traditionelles, simulatorbasiertes Agententraining nutzt verstärkendes Lernen für das Training, was erfordert, dass das Spiel oder die Umgebung ein „Belohnungssignal“ liefert, aus dem der Agent lernen kann – zum Beispiel Sieg/Niederlage im Fall von Go oder Starcraft oder „Punktzahl“. für Atari“, sagte Harley gegenüber Tech und stellte fest, dass dieser Ansatz für diese Spiele verwendet wurde und phänomenale Ergebnisse lieferte.
„Bei den Spielen, die wir nutzen, etwa den kommerziellen Spielen unserer Partner“, fuhr er fort, „haben wir keinen Zugriff auf ein solches Belohnungssignal.“ Darüber hinaus sind wir an Agenten interessiert, die eine Vielzahl von Aufgaben erledigen können, die in einem offenen Text beschrieben werden – es ist nicht möglich, für jedes Spiel ein „Belohnungs“-Signal für jedes mögliche Ziel auszuwerten. Stattdessen schulen wir Agenten, indem wir nachahmendes Lernen aus menschlichem Verhalten nutzen und vorgegebene Ziele im Text festlegen.“
Mit anderen Worten: Eine strikte Belohnungsstruktur kann den Agenten in seinen Zielen einschränken, denn wenn er sich an der Punktzahl orientiert, wird er niemals etwas unternehmen, das diesen Wert nicht maximiert. Wenn es jedoch Wert auf etwas Abstrakteres legt, beispielsweise darauf, wie nah seine Aktion an einer Aktion ist, die es zuvor beobachtet hat, kann es darauf trainiert werden, fast alles tun zu „wollen“, solange die Trainingsdaten dies irgendwie widerspiegeln.
Andere Unternehmen prüfen diese Art von ergebnisoffene Zusammenarbeit und Kreation sowie; Gespräche mit NPCs werden derzeit intensiv als Gelegenheit betrachtet, beispielsweise einen LLM-artigen Chatbot zum Einsatz zu bringen. Und auch einfache improvisierte Aktionen oder Interaktionen werden in einigen wirklich interessanten Forschungen zu Agenten von KI simuliert und verfolgt.
Natürlich gibt es auch Experimente mit unendlichen Spielen wie MarioGPT, aber das ist eine ganz andere Sache.