
Google DeepMind, Googles Flaggschiff-KI-Forschungslabor, möchte OpenAI bei der Videogenerierung schlagen – und das könnte zumindest für eine kurze Zeit der Fall sein.
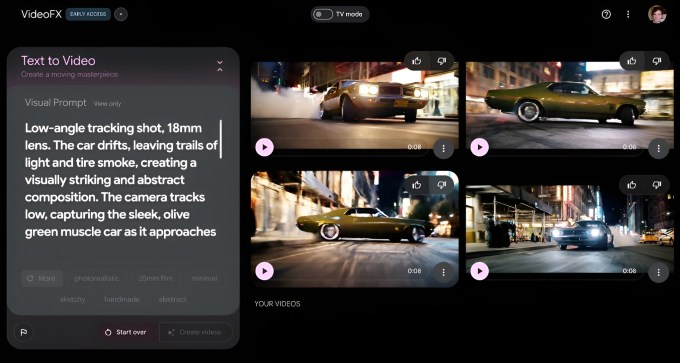
Am Montag kündigte DeepMind Veo 2 an, eine videogenerierende KI der nächsten Generation und Nachfolger von Veo, die eine wachsende Anzahl von Produkten im gesamten Google-Portfolio antreibt. Veo 2 kann Clips von mehr als zwei Minuten Länge in Auflösungen von bis zu 4K (4096 x 2160 Pixel) erstellen.
Bemerkenswert ist, dass das die vierfache Auflösung – und mehr als die sechsfache Dauer – ist, die Sora von OpenAI erreichen kann.
Zugegebenermaßen ist es vorerst ein theoretischer Vorteil. In Googles experimentellem Videoerstellungstool VideoFX, in dem Veo 2 jetzt exklusiv verfügbar ist, sind Videos auf 720p und eine Länge von acht Sekunden begrenzt. (Sora kann bis zu 1080p, 20 Sekunden lange Clips produzieren.)
VideoFX steht auf einer Warteliste, aber Google gibt an, dass es diese Woche die Zahl der Nutzer erhöht, die darauf zugreifen können.
Eli Collins, VP of Product bei DeepMind, sagte gegenüber Tech außerdem, dass Google Veo 2 über seine Vertex AI-Entwicklerplattform verfügbar machen werde, „sobald das Modell einsatzbereit in großem Maßstab ist“.
„In den kommenden Monaten werden wir basierend auf dem Feedback der Benutzer weitere Iterationen durchführen“, sagte Collins, „und [we’ll] Versuchen Sie, die aktualisierten Funktionen von Veo 2 in überzeugende Anwendungsfälle im gesamten Google-Ökosystem zu integrieren … [W]Wir gehen davon aus, dass wir nächstes Jahr weitere Updates veröffentlichen werden.“
Kontrollierbarer
Wie Veo kann Veo 2 Videos anhand einer Textaufforderung (z. B. „Ein Auto rast eine Autobahn entlang“) oder eines Textes und eines Referenzbilds generieren.
Was ist also neu in Veo 2? Laut DeepMind verfügt das Modell, das Clips in verschiedenen Stilen generieren kann, über ein verbessertes „Verständnis“ für Physik und Kamerasteuerung und produziert „klareres“ Filmmaterial.
Mit klarer meint DeepMind, dass Texturen und Bilder in Clips schärfer sind – insbesondere in Szenen mit viel Bewegung. Die verbesserten Kamerasteuerungen ermöglichen es Veo 2, die virtuelle „Kamera“ in den von ihm generierten Videos präziser zu positionieren und diese Kamera zu bewegen, um Objekte und Personen aus verschiedenen Winkeln aufzunehmen.
DeepMind behauptet außerdem, dass Veo 2 Bewegungen, Fluiddynamiken (z. B. das Eingießen von Kaffee in eine Tasse) und Lichteigenschaften (z. B. Schatten und Reflexionen) realistischer modellieren kann. Dazu gehören laut DeepMind verschiedene Objektive und filmische Effekte sowie ein „nuancierter“ menschlicher Ausdruck.

DeepMind hat letzte Woche ein paar ausgewählte Beispiele von Veo 2 mit Tech geteilt. Für KI-generierte Videos sahen sie ziemlich gut aus – sogar außergewöhnlich gut. Veo 2 scheint ein ausgeprägtes Gespür für Lichtbrechung und schwierige Flüssigkeiten wie Ahornsirup zu haben und ein Händchen für die Emulation von Animationen im Pixar-Stil zu haben.
Aber trotz DeepMinds Beharren darauf, dass das Modell weniger wahrscheinlich Elemente wie zusätzliche Finger oder „unerwartete Objekte“ halluziniert, kann Veo 2 das unheimliche Tal nicht ganz überwinden.
Beachten Sie die leblosen Augen dieser hundeähnlichen Comic-Kreatur:

Und die seltsam rutschige Straße in diesem Filmmaterial – plus die Fußgänger im Hintergrund, die ineinander übergehen, und die Gebäude mit physisch unmöglichen Fassaden:

Collins gab zu, dass noch viel zu tun ist.
„Kohärenz und Konsistenz sind Bereiche für Wachstum“, sagte er. „Veo kann sich ein paar Minuten lang immer an eine Aufforderung halten, aber [it can’t] Befolgen Sie komplexe Anweisungen über lange Zeiträume hinweg. Ebenso kann die Konsistenz der Charaktere eine Herausforderung sein. Es gibt auch Raum für Verbesserungen bei der Erzeugung komplizierter Details, schneller und komplexer Bewegungen und bei der weiteren Erweiterung der Grenzen des Realismus.“
„DeepMind arbeitet weiterhin mit Künstlern und Produzenten zusammen, um seine Modelle und Tools zur Videogenerierung zu verfeinern“, fügte Collins hinzu.
„Wir haben seit Beginn unserer Veo-Entwicklung begonnen, mit Kreativen wie Donald Glover, The Weeknd, d4vd und anderen zusammenzuarbeiten, um ihren kreativen Prozess wirklich zu verstehen und zu erfahren, wie Technologie dabei helfen kann, ihre Vision zum Leben zu erwecken“, sagte Collins. „Unsere Arbeit mit den Entwicklern von Veo 1 hat die Entwicklung von Veo 2 beeinflusst und wir freuen uns darauf, mit vertrauenswürdigen Testern und Entwicklern zusammenzuarbeiten, um Feedback zu diesem neuen Modell zu erhalten.“
Sicherheit und Ausbildung
Veo 2 wurde anhand vieler Videos geschult. Im Allgemeinen funktionieren KI-Modelle so: Wenn ihnen ein Beispiel nach dem anderen einer Datenform zur Verfügung gestellt wird, erkennen die Modelle Muster in den Daten, die es ihnen ermöglichen, neue Daten zu generieren.
DeepMind wird nicht genau sagen, wo die Videos zum Trainieren von Veo 2 gescraped wurden, aber YouTube ist eine mögliche Quelle; Google besitzt YouTube, und DeepMind teilte Tech zuvor mit, dass Google-Modelle wie Veo „möglicherweise“ auf einige YouTube-Inhalte trainiert werden.
„Veo wurde in der Kombination hochwertiger Videobeschreibungen geschult“, sagte Collins. „Videobeschreibungspaare sind ein Video und eine zugehörige Beschreibung dessen, was in diesem Video passiert.“

Während DeepMind über Google Tools bereitstellt, mit denen Webmaster die Bots des Labors daran hindern können, Trainingsdaten von ihren Websites zu extrahieren, bietet DeepMind keinen Mechanismus, mit dem Ersteller Werke aus seinen vorhandenen Trainingssätzen entfernen können. Das Labor und seine Muttergesellschaft behaupten, dass Trainingsmodelle auf öffentlichen Daten basieren faire NutzungDies bedeutet, dass DeepMind davon ausgeht, dass es nicht verpflichtet ist, die Erlaubnis der Dateneigentümer einzuholen.
Nicht alle Kreativen sind sich einig – insbesondere im Hinblick auf Studien Schätzungen zufolge könnten in den kommenden Jahren Zehntausende Film- und Fernsehjobs durch KI zerstört werden. Mehrere KI-Unternehmen, darunter das gleichnamige Startup hinter der beliebten KI-Kunst-App Midjourney, stehen im Fadenkreuz von Klagen, in denen ihnen vorgeworfen wird, die Rechte von Künstlern durch Schulungen zu Inhalten ohne Zustimmung verletzt zu haben.
„Wir sind bestrebt, mit den Schöpfern und unseren Partnern zusammenzuarbeiten, um gemeinsame Ziele zu erreichen“, sagte Collins. „Wir arbeiten weiterhin mit der kreativen Community und Menschen in der gesamten Branche zusammen, sammeln Erkenntnisse und hören auf Feedback, auch mit denen, die VideoFX verwenden.“
Aufgrund der Art und Weise, wie sich heutige generative Modelle beim Training verhalten, bergen sie bestimmte Risiken, wie z. B. Aufstoßen, wenn ein Modell eine Spiegelkopie der Trainingsdaten generiert. Die Lösung von DeepMind sind Filter auf Eingabeaufforderungsebene, auch für gewalttätige, grafische und explizite Inhalte.
Googles Entschädigungspolitikdas bestimmten Kunden eine Verteidigung gegen Vorwürfe von Urheberrechtsverletzungen bietet, die sich aus der Nutzung seiner Produkte ergeben, gilt erst dann für Veo 2, wenn es allgemein verfügbar ist, sagte Collins.

Um das Risiko von Deepfakes zu verringern, verwendet DeepMind nach eigenen Angaben seine proprietäre Wasserzeichentechnologie SynthID, um unsichtbare Markierungen in die von Veo 2 generierten Frames einzubetten. Wie alle Wasserzeichentechnologien bietet SynthID jedoch ist nicht narrensicher.
Bild-Upgrades
Zusätzlich zu Veo 2 kündigte Google DeepMind heute Morgen Upgrades für Imagen 3 an, sein kommerzielles Bildgenerierungsmodell.
Ab heute wird eine neue Version von Imagen 3 für Benutzer von ImageFX, dem Bildgenerierungstool von Google, bereitgestellt. Laut DeepMind können damit „hellere, besser komponierte“ Bilder und Fotos in Stilen wie Fotorealismus, Impressionismus und Anime erstellt werden.
„Dieses Upgrade [to Imagen 3] Außerdem folgt es den Eingabeaufforderungen genauer und stellt detailliertere Details und Texturen dar“, schrieb DeepMind in einem Blogbeitrag, der Tech zur Verfügung gestellt wurde.
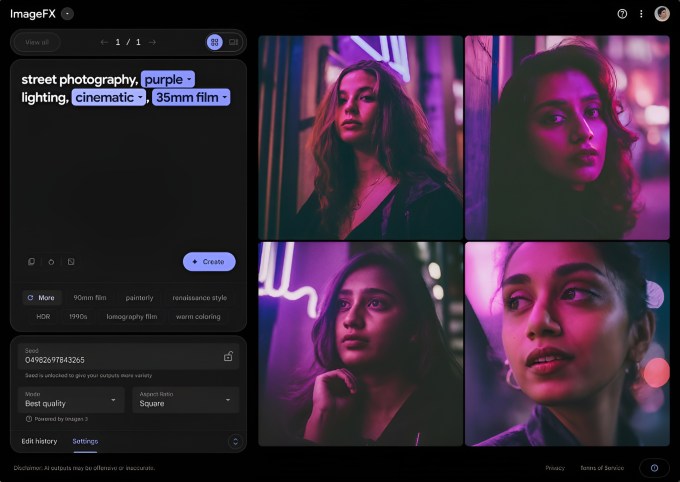
Parallel zum Modell werden UI-Updates für ImageFX eingeführt. Wenn Benutzer jetzt Eingabeaufforderungen eingeben, werden Schlüsselbegriffe in diesen Eingabeaufforderungen zu „Chiplets“ mit einem Dropdown-Menü mit vorgeschlagenen, verwandten Wörtern. Benutzer können die Chips verwenden, um zu wiederholen, was sie geschrieben haben, oder aus einer Reihe automatisch generierter Deskriptoren unter der Eingabeaufforderung auswählen.