
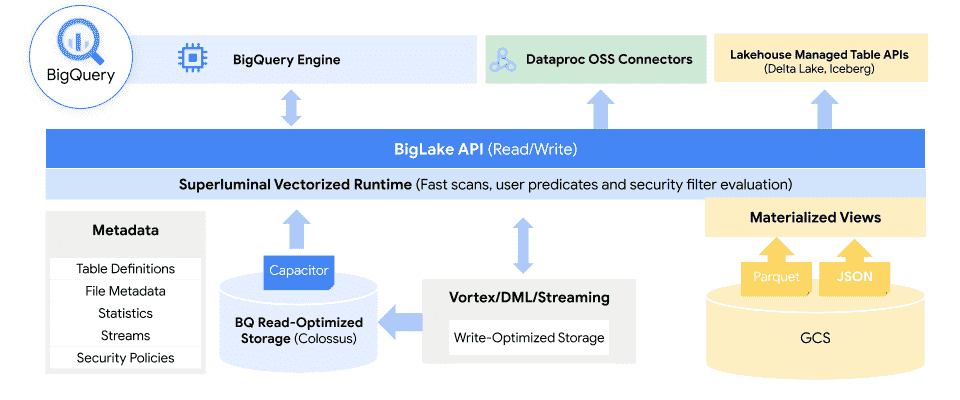
Auf seinem Cloud Data Summit hat Google heute den Preview-Launch von BigLake, einem neuen, angekündigt Data Lake-Speicher-Engine Das erleichtert Unternehmen die Analyse der Daten in ihren Data Warehouses und Data Lakes.
Die Kernidee hier ist, die Erfahrung von Google mit dem Betrieb und der Verwaltung seines BigQuery Data Warehouse zu nutzen und es auf Data Lakes in Google Cloud Storage zu erweitern, indem das Beste aus Data Lakes und Warehouses in einem einzigen Dienst kombiniert wird, der den zugrunde liegenden Speicher abstrahiert Formate und Systeme.
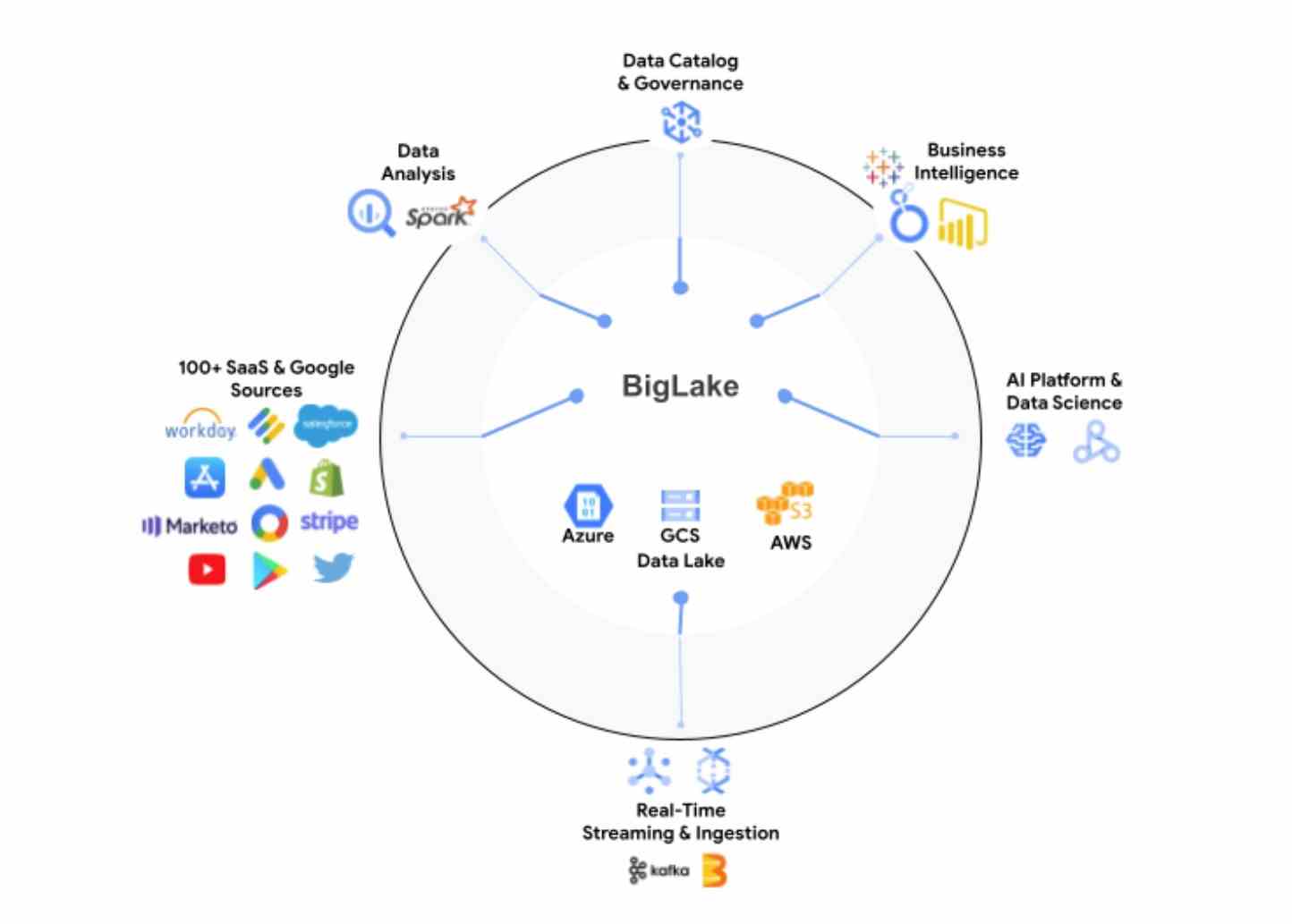
Es ist erwähnenswert, dass sich diese Daten in BigQuery befinden oder auf AWS S3 und Azure leben können Data Lake Storage Gen2, zu. Durch BigLake erhalten Entwickler Zugriff auf eine einheitliche Speicher-Engine und die Möglichkeit, die zugrunde liegenden Datenspeicher über ein einziges System abzufragen, ohne Daten verschieben oder duplizieren zu müssen.
„Die Verwaltung von Daten über unterschiedliche Seen und Warenhäuser hinweg schafft Silos und erhöht Risiken und Kosten, insbesondere wenn Daten verschoben werden müssen“, erklärt Gerrit Kazmaier, VP und GM für Datenbanken, Datenanalyse und Business Intelligence bei Google Cloud, stellt er in der heutigen Ankündigung fest. „Mit BigLake können Unternehmen ihre Data Warehouses und Lakes vereinheitlichen, um Daten zu analysieren, ohne sich Gedanken über das zugrunde liegende Speicherformat oder -system machen zu müssen, wodurch die Notwendigkeit entfällt, Daten aus einer Quelle zu duplizieren oder zu verschieben, und Kosten und Ineffizienzen reduziert werden.“
Bildnachweis: Google
Mithilfe von Richtlinien-Tags ermöglicht BigLake Administratoren, ihre Sicherheitsrichtlinien auf Tabellen-, Zeilen- und Spaltenebene zu konfigurieren. Dazu gehören Daten, die in Google Cloud Storage gespeichert sind, sowie die beiden unterstützten Drittsysteme, wo BigQuery Omni, der Multi-Cloud-Analysedienst von Google, ermöglicht diese Sicherheitskontrollen. Diese Sicherheitskontrollen stellen dann auch sicher, dass nur die richtigen Daten in Tools wie Spark, Presto, Trino und TensorFlow fließen. Der Dienst lässt sich auch in den von Google integrieren Dataplex Tool, um zusätzliche Datenverwaltungsfunktionen bereitzustellen.
Google merkt an, dass BigLake feinkörnige Zugriffskontrollen bereitstellen wird und dass seine API Google Cloud sowie Dateiformate wie den offenen spaltenorientierten Apache umfassen wird Parkett und Open-Source-Verarbeitungsmaschinen wie Apache Spark.
Bildnachweis: Google
„Die Menge an wertvollen Daten, die Unternehmen verwalten und analysieren müssen, wächst mit einer unglaublichen Geschwindigkeit“, erklären Google Cloud-Softwareentwickler Justin Levandoski und Produktmanager Gaurav Saxena in der heutigen Ankündigung. „Diese Daten sind zunehmend über viele Standorte verteilt, darunter Data Warehouses, Data Lakes und NoSQL-Speicher. Da die Daten eines Unternehmens komplexer werden und sich über unterschiedliche Datenumgebungen ausbreiten, entstehen Silos, die erhöhte Risiken und Kosten verursachen, insbesondere wenn diese Daten verschoben werden müssen. Unsere Kunden haben es deutlich gemacht; Sie brauchen Hilfe.“
Das gab neben BigLake heute auch Google bekannt Schlüssel, seine global verteilte SQL-Datenbank, wird bald eine neue Funktion namens „Change Streams“ erhalten. Mit diesen können Benutzer alle Änderungen an einer Datenbank in Echtzeit verfolgen, seien es Einfügungen, Aktualisierungen oder Löschungen. „Dies stellt sicher, dass Kunden immer Zugriff auf die aktuellsten Daten haben, da sie Änderungen von Spanner zu BigQuery für Echtzeitanalysen einfach replizieren, nachgelagertes Anwendungsverhalten mit Pub/Sub auslösen oder Änderungen in Google Cloud Storage (GCS) zur Einhaltung von Vorschriften speichern können.“ erklärt Kazmaier.
Google Cloud auch heute gebracht Vertex AI-Workbenchein Tool zur Verwaltung des gesamten Lebenszyklus eines Data-Science-Projekts, aus der Beta-Phase heraus und in die allgemeine Verfügbarkeit, und startete Connected Sheets für Looker sowie die Möglichkeit, in seinem BI-Tool Data Studio auf Looker-Datenmodelle zuzugreifen.