
OpenAI hat am Donnerstag seine neuen o1-Modelle veröffentlicht und ChatGPT-Benutzern damit erstmals die Möglichkeit gegeben, KI-Modelle auszuprobieren, die innehalten, um „nachzudenken“, bevor sie antworten. Um diese Modelle, die bei OpenAI den Codenamen „Strawberry“ tragen, hat sich viel Hype aufgebaut. Aber wird Strawberry dem Hype gerecht?
Irgendwie schon.
Im Vergleich zu GPT-4o fühlen sich die o1-Modelle wie ein Schritt vorwärts und zwei Schritte zurück an. OpenAI o1 zeichnet sich durch hervorragende Argumentation und Beantwortung komplexer Fragen aus, aber die Nutzung des Modells ist etwa viermal teurer als die von GPT-4o. Dem neuesten Modell von OpenAI fehlen die Tools, multimodalen Fähigkeiten und die Geschwindigkeit, die GPT-4o so beeindruckend gemacht haben. Tatsächlich gibt OpenAI sogar zu, dass „GPT-4o ist immer noch die beste Option für die meisten Eingabeaufforderungen“ auf seiner Hilfeseite und weist an anderer Stelle darauf hin, dass o1 bei einfacheren Aufgaben Probleme hat.
„Es ist beeindruckend, aber ich denke, die Verbesserung ist nicht sehr signifikant“, sagte Ravid Shwartz Ziv, ein NYU-Professor, der KI-Modelle untersucht. „Bei bestimmten Problemen ist es besser, aber es gibt keine Verbesserung auf der ganzen Linie.“
Aus all diesen Gründen ist es wichtig, o1 nur für die Fragen zu verwenden, bei denen es wirklich helfen soll: große Fragen. Um es klar zu sagen: Die meisten Menschen verwenden heute keine generative KI, um diese Art von Fragen zu beantworten, hauptsächlich, weil die heutigen KI-Modelle dafür nicht sehr gut sind. o1 ist jedoch ein vorsichtiger Schritt in diese Richtung.
Große Ideen durchdenken
OpenAI o1 ist einzigartig, weil es „nachdenkt“, bevor es antwortet. Es zerlegt große Probleme in kleine Schritte und versucht zu erkennen, wann es einen dieser Schritte richtig oder falsch macht. Dieses „mehrstufige Denken“ ist nicht ganz neu (Forscher haben es schon seit Jahren vorgeschlagen und You.com verwendet es für komplexe Abfragen), aber es war bis vor kurzem nicht praktisch.
„Es gibt eine Menge Aufregung in der KI-Community“, sagte Workera-CEO und Stanford-Dozent Kian Katanforoosh, der Kurse zum maschinellen Lernen gibt, in einem Interview. „Wenn Sie einen Reinforcement-Learning-Algorithmus in Kombination mit einigen der Sprachmodelltechniken trainieren können, die OpenAI bietet, können Sie technisch gesehen schrittweises Denken schaffen und dem KI-Modell ermöglichen, von den großen Ideen, die Sie gerade durcharbeiten, rückwärts zu gehen.“
OpenAI o1 ist außerdem einzigartig teuer. In den meisten Modellen zahlen Sie für Eingabe- und Ausgabetoken. Allerdings fügt o1 einen versteckten Prozess hinzu (die kleinen Schritte, in die das Modell große Probleme zerlegt), der eine große Menge an Rechenleistung hinzufügt, die Sie nie vollständig sehen. OpenAI verbirgt einige Details dieses Prozesses, um seinen Wettbewerbsvorteil aufrechtzuerhalten. Trotzdem werden Ihnen diese in Form von „Argumentation-Token“ in Rechnung gestellt. Dies unterstreicht noch einmal, warum Sie bei der Verwendung von OpenAI o1 vorsichtig sein müssen, damit Ihnen nicht eine Menge Token berechnet werden, wenn Sie fragen, wo die Hauptstadt von Nevada liegt.
Die Idee eines KI-Modells, das Ihnen hilft, „von großen Ideen zurückzugehen“, ist jedoch wirkungsvoll. In der Praxis ist das Modell dafür ziemlich gut.
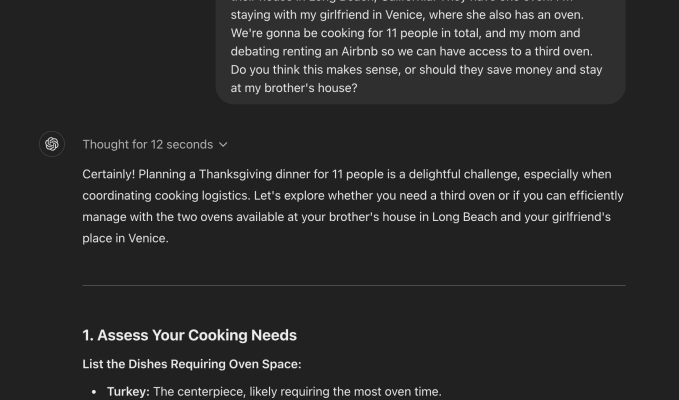
In einem Beispiel bat ich ChatGPT o1 preview, meiner Familie bei der Planung von Thanksgiving zu helfen, eine Aufgabe, die von ein wenig unvoreingenommener Logik und Argumentation profitieren könnte. Konkret wollte ich Hilfe dabei, herauszufinden, ob zwei Öfen ausreichen würden, um ein Thanksgiving-Dinner für 11 Personen zu kochen, und wollte besprechen, ob wir in Betracht ziehen sollten, ein Airbnb zu mieten, um Zugang zu einem dritten Ofen zu erhalten.

Nach 12 Sekunden „Nachdenken“ schrieb mir ChatGPT eine über 750 Wörter lange Antwort, in der es mir letztendlich mitteilte, dass zwei Öfen mit etwas sorgfältiger Strategie ausreichen sollten und es meiner Familie ermöglichen würde, Kosten zu sparen und mehr Zeit miteinander zu verbringen. Aber es schlüsselte seine Überlegungen bei jedem Schritt für mich auf und erklärte, wie es all diese externen Faktoren berücksichtigte, einschließlich Kosten, Familienzeit und Ofenmanagement.
Die Vorschau von ChatGPT o1 hat mir gezeigt, wie ich den Platz im Ofen des Hauses, in dem die Veranstaltung stattfindet, optimal nutzen kann. Das war eine kluge Idee. Seltsamerweise wurde mir vorgeschlagen, für den Tag einen tragbaren Ofen zu mieten. Allerdings hat das Modell viel besser abgeschnitten als GPT-4o, das mehrere Nachfragen dazu verlangte, welche Gerichte ich genau mitbringen würde, und mir dann nur dürftige Ratschläge gab, die ich weniger nützlich fand.
Es mag albern erscheinen, nach dem Thanksgiving-Dinner zu fragen, aber Sie werden erkennen, wie hilfreich dieses Tool beim Aufteilen komplizierter Aufgaben sein kann.
Ich habe o1 auch gebeten, mir bei der Planung eines arbeitsreichen Tages zu helfen, an dem ich zwischen dem Flughafen, mehreren persönlichen Treffen an verschiedenen Orten und meinem Büro hin- und herfahren musste. Ich habe einen sehr detaillierten Plan erhalten, aber das war vielleicht ein bisschen viel. Manchmal können all die zusätzlichen Schritte etwas überwältigend sein.
Bei einer einfacheren Frage macht o1 viel zu viel – es weiß nicht, wann es aufhören soll, zu viel nachzudenken. Ich fragte, wo man in Amerika Zedern finden kann, und es lieferte eine über 800 Wörter lange Antwort, in der jede Zedernart im Land beschrieben wurde, einschließlich ihres wissenschaftlichen Namens. Aus irgendeinem Grund musste es irgendwann sogar die Richtlinien von OpenAI konsultieren. GPT-4o beantwortete diese Frage viel besser und lieferte mir etwa drei Sätze, in denen erklärt wurde, dass man die Bäume im ganzen Land finden kann.
Gedämpfte Erwartungen
In gewisser Weise konnte Strawberry dem Hype nie gerecht werden. Berichte über die Argumentationsmodelle von OpenAI stammen aus dem November 2023, also ungefähr zu der Zeit, als alle nach einer Antwort auf die Frage suchten, warum der Vorstand von OpenAI Sam Altman entlassen hatte. Das brachte die Gerüchteküche in der KI-Welt zum Brodeln und einige spekulierten, dass Strawberry eine Form von AGI sei, die aufgeklärte Version von KI, die OpenAI letztendlich schaffen möchte.
Altman bestätigt o1 ist nicht AGI, um alle Zweifel auszuräumen, nicht, dass Sie nach der Verwendung des Dings verwirrt wären. Der CEO hat auch die Erwartungen an diesen Start zurückgeschraubt, twittern dass „o1 immer noch fehlerhaft und eingeschränkt ist und beim ersten Gebrauch immer noch beeindruckender wirkt als später, wenn man mehr Zeit damit verbringt.“
Der Rest der KI-Welt muss sich mit einem weniger aufregenden Start abfinden als erwartet.
„Der Hype geriet für OpenAI gewissermaßen außer Kontrolle“, sagt Rohan Pandey, ein Forschungsingenieur beim KI-Startup ReWorkd, das Web Scraper mit den Modellen von OpenAI baut.
Er hofft, dass die Denkfähigkeit von o1 gut genug ist, um eine Reihe komplizierter Nischenprobleme zu lösen, bei denen GPT-4 versagt. So sehen wahrscheinlich die meisten Leute in der Branche o1, aber nicht ganz als den revolutionären Schritt nach vorne, den GPT-4 für die Branche darstellte.
„Alle warten auf eine sprunghafte Änderung der Fähigkeiten, und es ist nicht klar, ob dies dies darstellt. Ich denke, so einfach ist es“, sagte Mike Conover, CEO von Brightwave, der zuvor das KI-Modell Dolly von Databricks mitentwickelt hat, in einem Interview.
Was ist hier der Wert?
Die zugrunde liegenden Prinzipien, die zur Entwicklung von o1 verwendet wurden, reichen Jahre zurück. Google verwendete 2016 ähnliche Techniken, um AlphaGo zu entwickeln, das erste KI-System, das einen Weltmeister im Brettspiel Go besiegte, wie der ehemalige Google-Mitarbeiter und CEO des Risikokapitalunternehmens S32, Andy Harrison, betont. AlphaGo trainierte, indem es unzählige Male gegen sich selbst spielte und sich im Wesentlichen selbst beibrachte, bis es übermenschliche Fähigkeiten erreichte.
Er weist darauf hin, dass dies eine uralte Debatte in der KI-Welt aufwirft.
„Lager eins glaubt, dass man Arbeitsabläufe durch diesen agentenbasierten Prozess automatisieren kann. Lager zwei glaubt, dass man den Arbeitsablauf nicht bräuchte, wenn man über allgemeine Intelligenz und Urteilsvermögen verfügte und die KI wie ein Mensch einfach ein Urteil fällen würde“, sagte Harrison in einem Interview.
Harrison sagt, er sei in Lager eins und Lager zwei erfordere, dass man darauf vertrauen müsse, dass KI die richtigen Entscheidungen trifft. Er glaubt nicht, dass wir schon so weit sind.
Andere wiederum betrachten o1 weniger als Entscheidungshilfe, sondern eher als ein Werkzeug, um Ihr Denken bei wichtigen Entscheidungen zu hinterfragen.
Katanforoosh, der CEO von Workera, beschrieb ein Beispiel, bei dem er ein Vorstellungsgespräch mit einem Datenwissenschaftler für seine Firma führen wollte. Er teilt OpenAI o1 mit, dass er nur 30 Minuten Zeit habe und eine bestimmte Anzahl an Fähigkeiten beurteilen wolle. Er kann mit dem KI-Modell rückwärts arbeiten, um zu verstehen, ob er richtig darüber nachdenkt, und o1 wird Zeitbeschränkungen und so weiter verstehen.
Die Frage ist, ob dieses hilfreiche Tool den hohen Preis wert ist. Da KI-Modelle immer günstiger werden, ist o1 eines der ersten KI-Modelle seit langem, das teurer geworden ist.