
Die ARC Prize Foundation, eine gemeinnützige Organisation, die von einem prominenten KI-Forscher François Chollet mitbegründet wurde, kündigte in a Blog -Beitrag Am Montag hat es einen neuen, herausfordernden Test zur Messung der allgemeinen Intelligenz führender KI -Modelle geschaffen.
Bisher hat der neue Test, ARC-Agi-2 genannt, die meisten Modelle übertroffen.
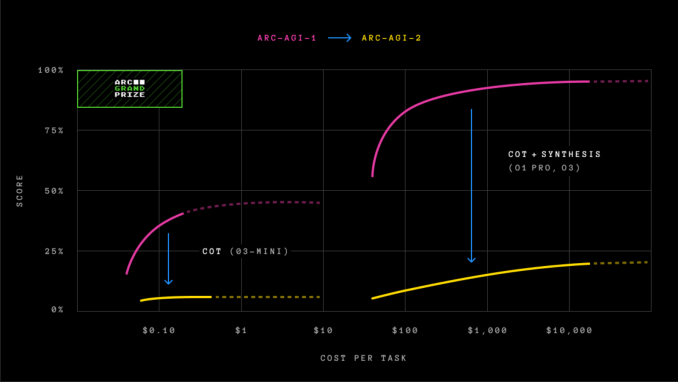
AI-Modelle „Argumenting“ wie Openai’s O1-Pro und Deepseeks R1-Score zwischen 1% und 1,3% für ARC-Agi-2, so die Bogenpreis -Rangliste. Leistungsstarke Nicht-Reasoning-Modelle wie GPT-4,5, Claude 3.7 Sonett und Gemini 2.0 Flash-Flash-Flash-Punkte erzielen rund 1%.
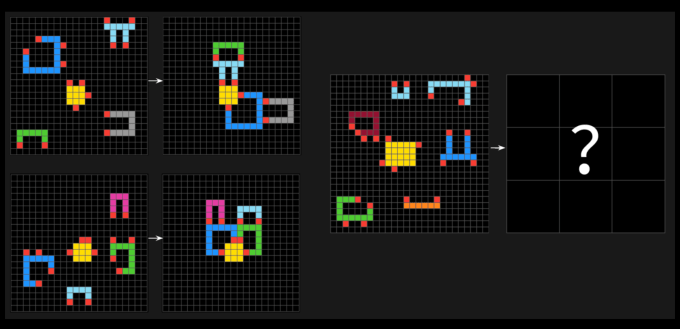
Die ARC-Agi-Tests bestehen aus puzzleähnlichen Problemen, bei denen eine KI visuelle Muster aus einer Sammlung verschiedener farbiger Quadrate identifizieren und das richtige „Antwort“ -Rtier erzeugen muss. Die Probleme sollten eine KI dazu zwingen, sich an neue Probleme anzupassen, die es zuvor noch nicht gesehen hat.
Die Arc Prize Foundation hatte über 400 Menschen, die Arc-Agi-2 einnehmen, um eine menschliche Grundlinie zu errichten. Im Durchschnitt haben „Panels“ dieser Leute 60% der Fragen des Tests richtig – viel besser als die Ergebnisse der Modelle.
In a Post auf xChollet behauptete, Arc-Agi-2 sei ein besseres Maß für die tatsächliche Intelligenz eines KI-Modells als die erste Iteration des Tests, Arc-Agi-1. Die Tests der Arc Prize Foundation zielen darauf ab, zu bewerten, ob ein KI -System außerhalb der Daten, auf die es geschult wurde, effizient neue Fähigkeiten erwerben kann.
Chollet sagte, dass der neue Test im Gegensatz zu ARC-Agi-1 verhindert, dass KI-Modelle sich auf „brutale Kraft“-umfangreiche Rechenleistung-verlassen, um Lösungen zu finden. Chollet erkannte zuvor an, dass dies ein großer Fehler bei ARC-Agi-1 war.
Um die Fehler des ersten Tests zu beheben, führt ARC-Agi-2 eine neue Metrik vor: Effizienz. Es erfordert auch Modelle, Muster im laufenden Fliegen zu interpretieren, anstatt sich auf das Auswendiglernen zu verlassen.
„Intelligenz wird nicht ausschließlich durch die Fähigkeit definiert, Probleme zu lösen oder hohe Punktzahlen zu erzielen“ Blog -Beitrag. „Die Effizienz, mit der diese Fähigkeiten erworben und eingesetzt werden [the] Fähigkeit, eine Aufgabe zu lösen? ‚ aber auch: „Welche Effizienz oder Kosten?“
ARC-Agi-1 war bis Dezember 2024 ungefähr fünf Jahre ungeschlagen, als Openai sein fortschrittliches Argumentationsmodell O3 veröffentlichte, das alle anderen KI-Modelle übertraf und die menschliche Leistung bei der Bewertung übertraf. Wie wir damals feststellten, erhöhte sich die Leistung von O3 bei ARC-Agi-1 mit einem kräftigen Preis.
Die Version des O3-Modells von OpenAI-O3 (niedrig)-, das zuerst neue Höhen für ARC-AGI-1 erreichte und bei dem Test 75,7% erzielte, erhielt massiv 4% für ARC-AGI-2 unter Verwendung von Rechenleistung im Wert von 200 US-Dollar pro Aufgabe.
Die Ankunft von ARC-Agi-2 kommt, so viele in der Tech-Branche fordern neue, ungesättigte Benchmarks, um den KI-Fortschritt zu messen. Der Mitbegründer von Face, Thomas Wolf, sagte kürzlich mit Tech, dass der KI-Industrie ausreichende Tests fehlen, um die wichtigsten Merkmale der sogenannten künstlichen allgemeinen Intelligenz, einschließlich Kreativität, zu messen.
Neben dem neuen Benchmark gab die ARC -Preisstiftung bekannt Ein neuer ARC -Preis 2025 Wettbewerbfordern Entwickler heraus, 85% Genauigkeit des ARC-Agi-2-Tests zu erreichen und gleichzeitig 0,42 USD pro Aufgabe auszugeben.