
Da sich konventionelle KI -Benchmarking -Techniken als unzureichend erweisen, wenden sich KI -Bauherren kreativere Möglichkeiten, um die Fähigkeiten generativer KI -Modelle zu bewerten. Für eine Gruppe von Entwicklern ist das Minecraft, das in Microsoft befindliche Sandbox-Building-Spiel.
Die Website Minecraft Benchmark (oder MC-Bench) wurde gemeinsam in Kopf-an-Kopf-Herausforderungen, um auf Eingabeaufforderungen mit Minecraft-Kreationen zu reagieren, zusammengearbeitet, um KI-Modelle gegeneinander zu reagieren. Benutzer können abstimmen, welches Modell einen besseren Job gemacht hat, und erst nach der Abstimmung können sie sehen, welche KI jeden Minecraft -Aufbau gemacht hat.

Für Adi Singh, den 12. Klasse, der MC-Bench begann, ist der Wert von Minecraft nicht so sehr das Spiel selbst, sondern die Vertrautheit, die die Leute damit haben-schließlich ist es das Bestseller Videospiel aller Zeiten. Selbst für Leute, die das Spiel nicht gespielt haben, ist es immer noch möglich zu bewerten, welche blockige Darstellung einer Ananas besser realisiert wird.
„Minecraft ermöglicht es den Menschen, den Fortschritt zu erkennen [of AI development] viel leichter „, sagte Singh zu Tech.
MC-Bench listet derzeit acht Personen als freiwillige Mitwirkende auf. Anthropic, Google, OpenAI und Alibaba haben die Verwendung ihrer Produkte durch das Projekt für Benchmark-Eingaben pro MC-Bench-Website subventioniert, die Unternehmen sind jedoch nicht angehängt.
„Derzeit machen wir einfach einfache Builds, um darüber nachzudenken, wie weit wir aus der GPT-3-Ära gekommen sind, aber [we] Könnte uns zu diesen längeren Plänen und zielorientierten Aufgaben skalieren „, sagte Singh.
Andere Spiele wie Pokémon Red, Straßenkämpferund Pictionary wurden als experimentelle Benchmarks für KI verwendet, zum Teil, weil die Kunst des Benchmarking -KI notorisch schwierig ist.
Forscher testen häufig KI -Modelle auf standardisierte BewertungenAber viele dieser Tests geben AI einen Heimatvorteil. Aufgrund der Art und Weise, wie sie trainiert sind, werden Modelle natürlich bei bestimmten, engen Arten von Problemlösungen geschenkt, insbesondere bei Problemlösungen, die eine Auswendiglerin oder grundlegende Extrapolation erfordert.
Einfach ausgedrückt ist es schwer zu erlangen, was es bedeutet, dass Openai’s GPT-4 im 88. Perzentil auf der LSAT punkten kann, kann aber nicht erkennen, wie viele Rs im Wort „Erdbeere“ sind. Anthropics Claude 3.7 Sonett Er erreichte eine Genauigkeit von 62,3% bei einem standardisierten Benchmark für Software-Engineering, aber es ist schlechter, Pokémon zu spielen als die meisten fünfjährigen.
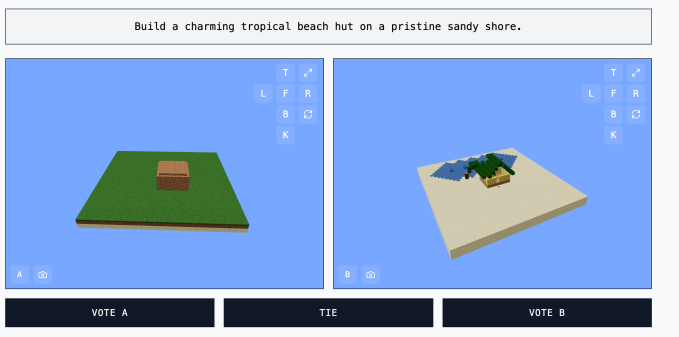
MC-Bench ist technisch gesehen ein Programmier-Benchmark, da die Modelle aufgefordert werden, Code zu schreiben, um den aufgelösten Build wie „Frosty the Snowman“ oder „eine charmante tropische Strandhütte an einer unberührten sandigen Küste“ zu erstellen.
Für die meisten MC-Bench-Nutzer ist es jedoch einfacher zu bewerten, ob ein Schneemann besser aussieht, als sich in Code zu befassen, was dem Projekt ein breiterer Reiz gibt-und damit das Potenzial, mehr Daten darüber zu sammeln, welche Modelle konsequent besser punkten.
Ob diese Ergebnisse in Bezug auf die Nützlichkeit von KI zu viel sind, steht natürlich zur Debatte. Singh behauptet jedoch, dass sie ein starkes Signal sind.
„Die aktuelle Rangliste reflektiert meine eigene Erfahrung, diese Modelle zu verwenden, ganz eng, was anders ist als viele reine Text -Benchmarks“, sagte Singh. „Vielleicht [MC-Bench] könnte für Unternehmen nützlich sein, um zu wissen, ob sie in die richtige Richtung gehen. “