
Mit einer so schnelllebigen Branche wie der KI Schritt zu halten, ist eine große Herausforderung. Bis eine KI dies für Sie erledigen kann, finden Sie hier eine praktische Zusammenfassung der neuesten Geschichten aus der Welt des maschinellen Lernens sowie bemerkenswerte Forschungsergebnisse und Experimente, die wir nicht alleine behandelt haben.
Diese Woche möchte ich im Bereich KI den Fokus auf Label- und Annotations-Startups richten – Startups wie Scale AI angeblich in Gesprächen zur Beschaffung neuer Mittel im Wert von 13 Milliarden US-Dollar. Beschriftungs- und Annotationsplattformen erhalten möglicherweise nicht die Aufmerksamkeit, die auffällige neue generative KI-Modelle wie Sora von OpenAI erhalten. Aber sie sind unerlässlich. Ohne sie gäbe es moderne KI-Modelle wohl nicht.
Die Daten, auf denen viele Modelle trainieren, müssen gekennzeichnet werden. Warum? Beschriftungen oder Tags helfen den Modellen, Daten während des Trainingsprozesses zu verstehen und zu interpretieren. Etiketten zum Trainieren eines Bilderkennungsmodells könnten beispielsweise die Form von Markierungen um Objekte annehmen: „Begrenzungsrahmen” oder Bildunterschriften, die sich auf jede Person, jeden Ort oder jedes Objekt beziehen, die in einem Bild abgebildet sind.
Die Genauigkeit und Qualität der Beschriftungen wirken sich erheblich auf die Leistung – und Zuverlässigkeit – der trainierten Modelle aus. Und Annotation ist ein gewaltiges Unterfangen, das Tausende bis Millionen von Beschriftungen für die größeren und komplexeren Datensätze erfordert, die verwendet werden.
Man könnte also annehmen, dass Datenannotatoren gut behandelt werden, existenzsichernde Löhne erhalten und die gleichen Vorteile erhalten, die auch die Ingenieure genießen, die die Modelle selbst erstellen. Aber oft ist das Gegenteil der Fall – ein Ergebnis der brutalen Arbeitsbedingungen, die viele Annotations- und Label-Startups fördern.
Unternehmen mit Milliardenbeträgen wie OpenAI haben sich darauf verlassen Kommentatoren in Ländern der Dritten Welt zahlten nur ein paar Dollar pro Stunde. Einige dieser Annotatoren sind mit äußerst verstörenden Inhalten wie grafischen Bildern konfrontiert, erhalten jedoch keine Freistellung (da es sich in der Regel um Auftragnehmer handelt) oder Zugang zu Ressourcen für die psychische Gesundheit.
Ein exzellentes Stück in NY Mag enthüllt insbesondere Scale AI, das Kommentatoren in so weit entfernten Ländern wie Nairobi und Kenia rekrutiert. Einige der Aufgaben auf Scale AI nehmen Etikettierer mehrere Arbeitstage von acht Stunden in Anspruch – ohne Pausen – und kosten nur 10 US-Dollar. Und diese Arbeiter sind den Launen der Plattform verpflichtet. Annotatoren bleiben manchmal lange Zeit ohne Arbeit, oder sie werden kurzerhand von Scale AI ausgeschlossen – wie es bei Auftragnehmern in Thailand, Vietnam, Polen und Pakistan der Fall war kürzlich.
Einige Annotations- und Kennzeichnungsplattformen behaupten, „fair gehandelte“ Arbeit anzubieten. Sie haben es tatsächlich zu einem zentralen Bestandteil ihres Brandings gemacht. Aber als Kate Kaye von MIT Tech Review Anmerkungenes gibt keine Vorschriften, nur schwache Industriestandards dafür, was ethische Kennzeichnungsarbeit bedeutet – und die Definitionen der Unternehmen selbst variieren stark.
Was also tun? Sofern es keinen großen technologischen Durchbruch gibt, wird die Notwendigkeit, Daten für das KI-Training zu kommentieren und zu kennzeichnen, nicht verschwinden. Wir können hoffen, dass sich die Plattformen selbst regulieren, aber die realistischere Lösung scheint die Politikgestaltung zu sein. Das ist an sich schon eine heikle Angelegenheit – aber meiner Meinung nach ist es die beste Chance, die wir haben, um die Dinge zum Besseren zu verändern. Oder zumindest damit beginnen.
Hier sind einige andere bemerkenswerte KI-Geschichten der letzten Tage:
-
- OpenAI baut einen Voice Cloner: OpenAI stellt eine Vorschau auf ein neues KI-gestütztes Tool namens Voice Engine vor, das es Benutzern ermöglicht, eine Stimme aus einer 15-sekündigen Aufnahme einer sprechenden Person zu klonen. Das Unternehmen entscheidet sich jedoch dafür, es (noch) nicht allgemein zu veröffentlichen, da die Gefahr von Missbrauch und Missbrauch besteht.
- Amazon verdoppelt sein Engagement bei Anthropic: Amazon hat weitere 2,75 Milliarden US-Dollar in das wachsende KI-Unternehmen Anthropic investiert und damit die im September letzten Jahres offen gelassene Option wahr gemacht.
- Google.org startet einen Beschleuniger: Google.org, der gemeinnützige Flügel von Google, startet ein neues, sechsmonatiges Programm im Wert von 20 Millionen US-Dollar, um gemeinnützige Organisationen bei der Entwicklung von Technologien zu unterstützen, die generative KI nutzen.
- Eine neue Modellarchitektur: Das KI-Startup AI21 Labs hat mit Jamba ein generatives KI-Modell veröffentlicht, das eine neuartige, neue Modellarchitektur – Zustandsraummodelle oder SSMs – verwendet, um die Effizienz zu verbessern.
- Databricks führt DBRX ein: Als weitere Modellneuigkeit veröffentlichte Databricks diese Woche DBRX, ein generatives KI-Modell, das der GPT-Serie von OpenAI und Gemini von Google ähnelt. Das Unternehmen gibt an, bei einer Reihe beliebter KI-Benchmarks, darunter auch bei mehreren Messbegründungen, hochmoderne Ergebnisse zu erzielen.
- Uber Eats und britische KI-Regulierung: Natasha schreibt darüber, wie der Kampf eines Uber Eats-Kuriers gegen KI-Voreingenommenheit zeigt, dass Gerechtigkeit im Rahmen der britischen KI-Vorschriften hart erkämpft ist.
- EU-Leitfaden zur Wahlsicherheit: Die Europäische Union hat am Dienstag einen Entwurf für Wahlsicherheitsrichtlinien veröffentlicht, der sich an die Bevölkerung richtet zwei Dutzend Plattformen, die im Rahmen des reguliert werden Gesetz über digitale Dienste, einschließlich Richtlinien zur Verhinderung der Verbreitung generativer KI-basierter Desinformation (auch bekannt als politische Deepfakes) durch Inhaltsempfehlungsalgorithmen.
- Grok wird aktualisiert: Der Grok-Chatbot von X wird bald ein aktualisiertes Basismodell erhalten, Grok-1.5 – gleichzeitig erhalten alle Premium-Abonnenten von (Grok war bisher exklusiv für X Premium+-Kunden.)
- Adobe erweitert Firefly: Diese Woche stellte Adobe Firefly Services vor, eine Reihe von mehr als 20 neuen generativen und kreativen APIs, Tools und Diensten. Außerdem wurden benutzerdefinierte Modelle eingeführt, die es Unternehmen ermöglichen, Firefly-Modelle basierend auf ihren Assets zu optimieren – ein Teil der neuen GenStudio-Suite von Adobe.
Mehr maschinelles Lernen
Wie ist das Wetter? Die KI ist zunehmend in der Lage, Ihnen dies zu sagen. Ich habe vor ein paar Monaten einige Anstrengungen bei der stündlichen, wöchentlichen und Jahrhundert-Prognose bemerkt, aber wie alles, was mit KI zu tun hat, entwickelt sich auch auf diesem Gebiet schnell. Die Teams hinter MetNet-3 und GraphCast haben einen Artikel veröffentlicht, der ein neues System namens beschreibt SAMENfür Scalable Ensemble Envelope Diffusion Sampler.
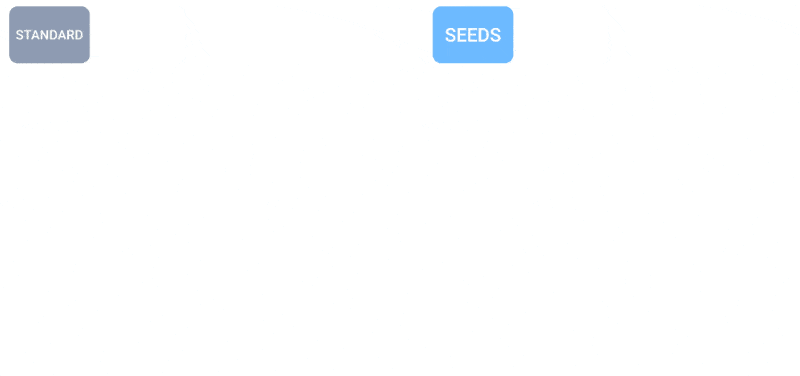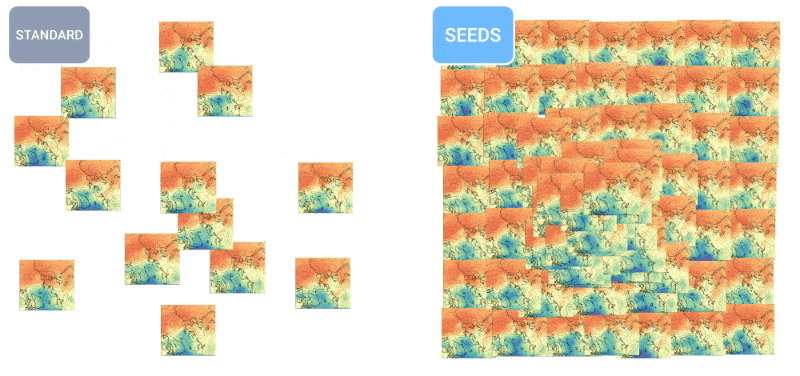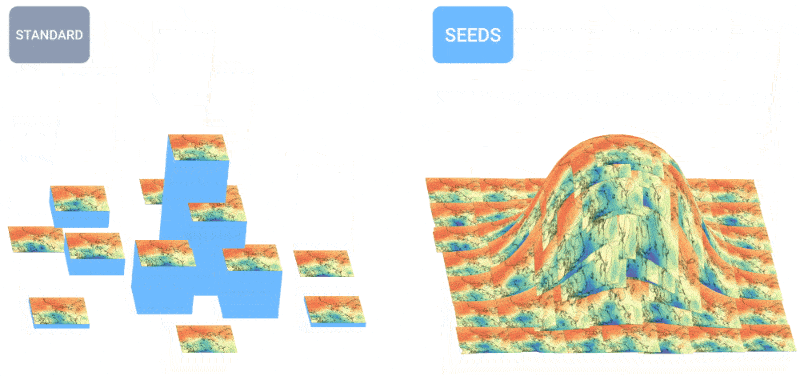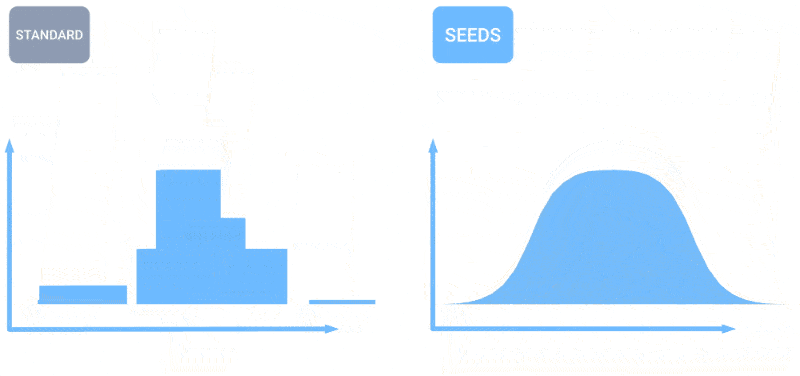
Animation, die zeigt, wie mehr Vorhersagen zu einer gleichmäßigeren Verteilung der Wettervorhersagen führen.
SEEDS nutzt Diffusion, um „Ensembles“ plausibler Wetterergebnisse für ein Gebiet basierend auf den Eingaben (Radarmesswerte oder Orbitalbilder vielleicht) viel schneller als physikbasierte Modelle zu generieren. Mit einer größeren Ensembleanzahl können sie mehr Grenzfälle abdecken (z. B. ein Ereignis, das nur in einem von 100 möglichen Szenarien auftritt) und sich bei wahrscheinlicheren Situationen sicherer verhalten.
Fujitsu hofft auch, die Natur besser zu verstehen Anwendung von KI-Bildverarbeitungstechniken auf Unterwasserbilder und Lidar-Daten, die von autonomen Unterwasserfahrzeugen gesammelt werden. Durch die Verbesserung der Bildqualität können andere, weniger anspruchsvolle Prozesse (wie die 3D-Konvertierung) besser mit den Zieldaten arbeiten.
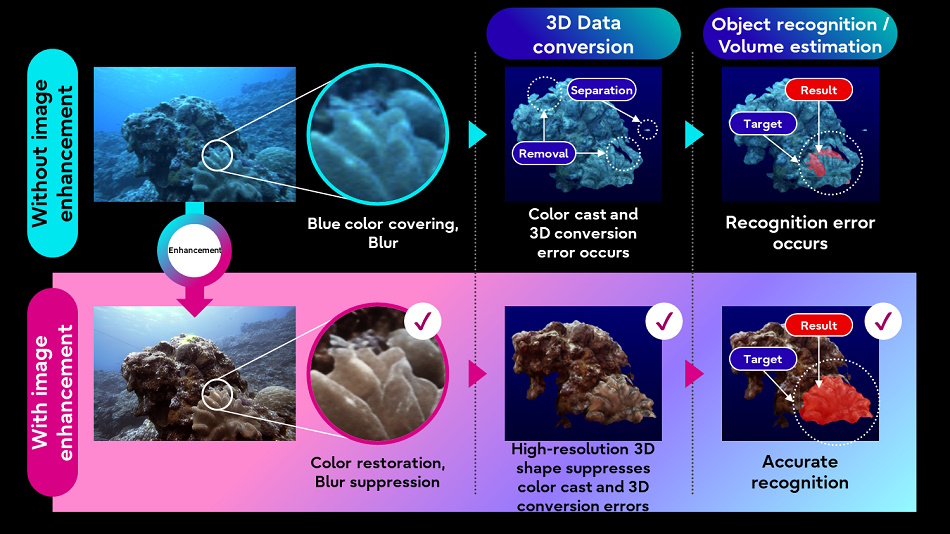
Bildnachweis: Fujitsu
Die Idee besteht darin, einen „digitalen Zwilling“ von Gewässern zu erstellen, der dabei helfen kann, neue Entwicklungen zu simulieren und vorherzusagen. Davon sind wir noch weit entfernt, aber irgendwo muss man anfangen.
Bei den LLMs haben Forscher herausgefunden, dass sie Intelligenz durch eine noch einfachere Methode als erwartet nachahmen: lineare Funktionen. Ehrlich gesagt ist mir die Mathematik ein Rätsel (Vektormaterial in vielen Dimensionen), aber dieser Artikel am MIT macht ziemlich deutlich, dass der Rückrufmechanismus dieser Modelle ziemlich … einfach ist.
Obwohl es sich bei diesen Modellen um wirklich komplizierte, nichtlineare Funktionen handelt, die auf vielen Daten trainiert werden und sehr schwer zu verstehen sind, funktionieren in ihnen manchmal wirklich einfache Mechanismen. Dies ist ein Beispiel dafür“, sagte Co-Hauptautor Evan Hernandez. Wenn Sie eher technisch versiert sind, Schauen Sie sich das Papier hier an.
Eine Möglichkeit, warum diese Modelle scheitern können, besteht darin, dass sie den Kontext oder das Feedback nicht verstehen. Selbst ein wirklich fähiger LLM versteht es möglicherweise nicht, wenn Sie ihm sagen, dass Ihr Name auf eine bestimmte Art und Weise ausgesprochen wird, da er eigentlich nichts weiß oder versteht. In Fällen, in denen dies wichtig sein könnte, wie etwa bei Mensch-Roboter-Interaktionen, könnte es Menschen abschrecken, wenn der Roboter so handelt.
Disney Research beschäftigt sich seit langem mit automatisierten Charakterinteraktionen Aussprache dieses Namens und Wiederverwendung von Papier ist erst vor einiger Zeit aufgetaucht. Es scheint offensichtlich, aber das Extrahieren der Phoneme, wenn sich jemand vorstellt, und das Kodieren dieser statt nur des geschriebenen Namens ist ein kluger Ansatz.

Bildnachweis: Disney-Forschung
Da sich KI und Suche schließlich immer mehr überschneiden, lohnt es sich, neu zu bewerten, wie diese Tools verwendet werden und ob diese unheilige Verbindung neue Risiken mit sich bringt. Safiya Umoja Noble ist seit Jahren eine wichtige Stimme in den Bereichen KI und Suchethik und ihre Meinung ist immer aufschlussreich. Sie hat ein nettes Interview mit dem UCLA-Nachrichtenteam geführt darüber, wie sich ihre Arbeit entwickelt hat und warum wir in Bezug auf Voreingenommenheit und schlechte Angewohnheiten bei der Suche eiskalt bleiben müssen.