

Mit einer so schnelllebigen Branche wie der KI Schritt zu halten, ist eine große Herausforderung. Bis eine KI dies für Sie erledigen kann, finden Sie hier eine praktische Zusammenfassung der neuesten Geschichten aus der Welt des maschinellen Lernens sowie bemerkenswerte Forschungsergebnisse und Experimente, die wir nicht alleine behandelt haben.
Letzte Woche, Midjourney, baute das KI-Startup Image auf (und bald Video) Generators, hat eine kleine, überraschende Änderung an seinen Nutzungsbedingungen vorgenommen, die sich auf die Richtlinien des Unternehmens zu IP-Streitigkeiten bezieht. Es diente vor allem dazu, scherzhafte Formulierungen durch eher juristische, zweifellos auf der Rechtsprechung beruhende Klauseln zu ersetzen. Die Änderung kann aber auch als Zeichen der Überzeugung von Midjourney gewertet werden, dass KI-Anbieter wie sie selbst aus den Gerichtsstreitigkeiten mit Entwicklern, deren Werke Trainingsdaten von Anbietern umfassen, als Sieger hervorgehen werden.
Die Änderung der Nutzungsbedingungen von Midjourney.
Generative KI-Modelle wie das von Midjourney werden anhand einer enormen Anzahl von Beispielen trainiert – z. B. Bilder und Text –, die normalerweise von öffentlichen Websites und Repositories im Internet stammen. Anbieter behaupten Diese faire Nutzung, die Rechtsdoktrin, die die Verwendung urheberrechtlich geschützter Werke zur Herstellung einer sekundären Schöpfung zulässt, solange diese transformativ ist, schützt sie, wenn es um die Ausbildung von Modellen geht. Aber nicht alle Entwickler sind dieser Meinung – insbesondere angesichts einer wachsenden Zahl von Studien, die zeigen, dass Modelle Trainingsdaten „herausgeben“ können – und dies auch tun.
Einige Anbieter haben einen proaktiven Ansatz gewählt, indem sie Lizenzvereinbarungen mit den Erstellern von Inhalten abgeschlossen und „Opt-out“-Regelungen für Trainingsdatensätze eingeführt haben. Andere haben versprochen, dass Kunden, die wegen der Nutzung der GenAI-Tools eines Anbieters in einen Urheberrechtsstreit verwickelt werden, keine Anwaltskosten zahlen müssen.
Midjourney gehört nicht zu den proaktiven.
Im Gegenteil, Midjourney war an einer Stelle etwas dreist bei der Verwendung urheberrechtlich geschützter Werke Aufrechterhaltung eine Liste Tausender Künstler – darunter Illustratoren und Designer großer Marken wie Hasbro und Nintendo –, deren Werke zum Trainieren von Midjourneys Modellen verwendet wurden oder werden würden. A Studie zeigt überzeugende Beweise dafür, dass Midjourney in seinen Trainingsdaten auch Fernsehsendungen und Film-Franchises verwendet hat, von „Toy Story“ über „Star Wars“ über „Dune“ bis hin zu „Avengers“.
Nun gibt es ein Szenario, in dem Gerichtsentscheidungen am Ende im Sinne von Midjourney ausfallen. Sollte das Justizsystem entscheiden, dass eine faire Nutzung gilt, hindert nichts das Startup daran, so weiterzumachen, wie bisher, alte und neue urheberrechtlich geschützte Daten zu scrapen und zu trainieren.
Aber es scheint eine riskante Wette zu sein.
Midjourney ist im Moment auf Hochtouren angeblich erzielte einen Umsatz von rund 200 Millionen US-Dollar ohne einen Cent externer Investitionen. Anwälte sind jedoch teuer. Und wenn entschieden wird, dass „Fair Use“ im Fall von Midjourney nicht gilt, würde das das Unternehmen über Nacht dezimieren.
Keine Belohnung ohne Risiko, oder?
Hier sind einige andere bemerkenswerte KI-Geschichten der letzten Tage:
KI-gestützte Werbung erregt die falsche Aufmerksamkeit: YouTuber haben auf Instagram einen Regisseur attackiert, dessen Werbespot die Arbeit eines anderen (viel schwierigeren und beeindruckenderen) ohne Quellenangabe wiederverwendet hat.
EU-Behörden machen vor Wahlen auf KI-Plattformen aufmerksam: Sie bitten die größten Technologieunternehmen, ihren Ansatz zur Verhinderung von Wahlbetrug zu erläutern.
Google Deepmind möchte, dass Ihr Koop-Gaming-Partner seine KI ist: Durch die Schulung eines Agenten in stundenlangem 3D-Spielen ist er in der Lage, einfache Aufgaben in natürlicher Sprache auszuführen.
Das Problem mit Benchmarks: Viele, viele KI-Anbieter behaupten, dass ihre Modelle die Konkurrenz durch eine objektive Metrik übertroffen oder übertroffen haben. Aber die von ihnen verwendeten Metriken sind oft fehlerhaft.
AI2 erhält 200 Millionen US-Dollar: AI2 Incubator, ein Spin-off des gemeinnützigen Allen Institute for AI, hat sich eine unerwartete Summe von 200 Millionen US-Dollar an Rechenleistung gesichert, die Startups, die sein Programm durchlaufen, nutzen können, um die frühe Entwicklung zu beschleunigen.
Indien verlangt Regierungsgenehmigung für KI und setzt diese dann zurück: Die indische Regierung kann offenbar nicht entscheiden, welches Maß an Regulierung für die KI-Industrie angemessen ist.
Anthropic bringt neue Modelle auf den Markt: Das KI-Startup Anthropic hat mit Claude 3 eine neue Modellfamilie auf den Markt gebracht, die angeblich mit dem GPT-4 von OpenAI konkurriert. Wir haben das Flaggschiffmodell (Claude 3 Opus) auf die Probe gestellt und fanden es beeindruckend – aber auch in Bereichen wie aktuellen Ereignissen mangelhaft.
Politische Deepfakes: Eine Studie des Centre for Countering Digital Hate (CCDH), einer britischen gemeinnützigen Organisation, untersucht die wachsende Menge an KI-generierter Desinformation – insbesondere Deepfake-Bilder im Zusammenhang mit Wahlen – auf X (ehemals Twitter) im vergangenen Jahr.
OpenAI gegen Musk: OpenAI sagt, dass es beabsichtige, alle Ansprüche von Elon Musk, CEO von und Erfolg.
Rezension zu Rufus: Letzten Monat gab Amazon bekannt, dass es einen neuen KI-gestützten Chatbot, Rufus, in der Amazon Shopping-App für Android und iOS einführen wird. Wir erhielten frühen Zugang – und waren schnell enttäuscht über den Mangel an Dingen, die Rufus kann (und die er gut kann).
Mehr maschinelles Lernen
Moleküle! Wie arbeiten Sie? KI-Modelle haben uns dabei geholfen, die Moleküldynamik, die Konformation und andere Aspekte der nanoskopischen Welt zu verstehen und vorherzusagen, für deren Test sonst möglicherweise teure und komplexe Methoden erforderlich wären. Natürlich muss man das noch verifizieren, aber Dinge wie AlphaFold verändern das Feld rasant.
Microsoft hat ein neues Modell namens ViSNet, mit dem Ziel, sogenannte Struktur-Aktivitäts-Beziehungen, komplexe Beziehungen zwischen Molekülen und biologischer Aktivität, vorherzusagen. Es ist noch ziemlich experimentell und definitiv nur für Forscher, aber es ist immer toll zu sehen, wie schwierige wissenschaftliche Probleme mit modernsten technischen Mitteln gelöst werden.
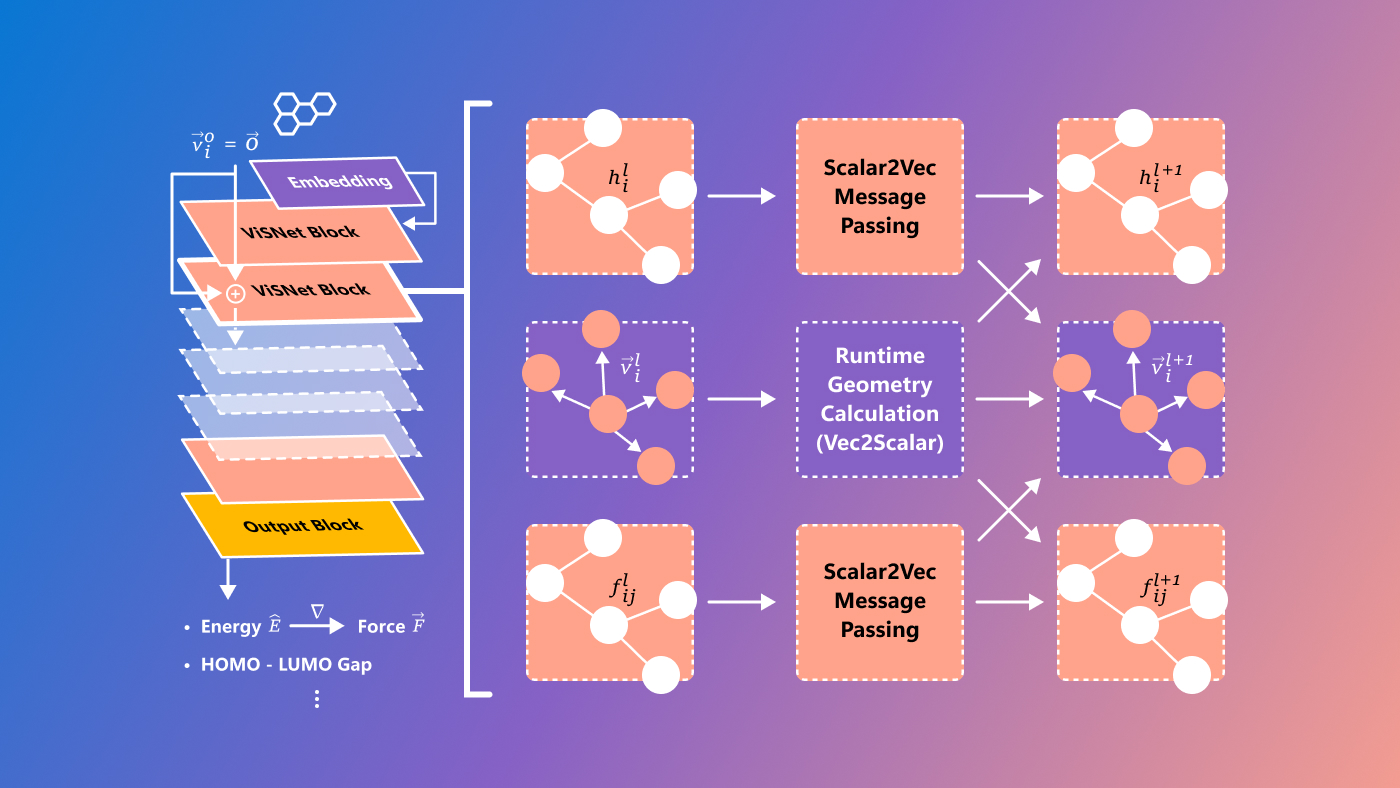
Bildnachweis: Microsoft
Forscher der Universität Manchester untersuchen dies konkret Identifizierung und Vorhersage von COVID-19-Variantenweniger anhand reiner Strukturen wie ViSNet als vielmehr durch Analyse der sehr großen genetischen Datensätze im Zusammenhang mit der Coronavirus-Evolution.
„Die beispiellose Menge an genetischen Daten, die während der Pandemie generiert wurden, erfordert Verbesserungen unserer Methoden, um sie gründlich zu analysieren“, sagte der leitende Forscher Thomas House. Sein Kollege Roberto Cahuantzi fügte hinzu: „Unsere Analyse dient als Machbarkeitsnachweis und zeigt den potenziellen Einsatz maschineller Lernmethoden als Warntool für die frühzeitige Entdeckung neu auftretender Hauptvarianten.“
KI kann auch Moleküle entwerfen, und eine Reihe von Forschern haben dies getan eine Initiative unterzeichnet Wir fordern Sicherheit und Ethik in diesem Bereich. Allerdings wie David Baker (einer der führenden Computerbiophysiker der Welt) feststellt: „Die potenziellen Vorteile des Proteindesigns übertreffen derzeit die Gefahren bei weitem.“ Nun, als Designer von KI-Proteindesignern ist er würde Sag das. Dennoch müssen wir uns vor Regulierungen hüten, die am Kern der Sache vorbeigehen und legitime Forschung behindern, während sie schlechten Akteuren Freiheit lassen.
Atmosphärenforscher der University of Washington haben eine interessante Behauptung aufgestellt, die auf einer KI-Analyse von Satellitenbildern über Turkmenistan aus 25 Jahren basiert. Im Wesentlichen ist die allgemein anerkannte Auffassung, dass die wirtschaftlichen Turbulenzen nach dem Fall der Sowjetunion zu geringeren Emissionen führten, möglicherweise nicht wahr – Tatsächlich könnte das Gegenteil eingetreten sein.
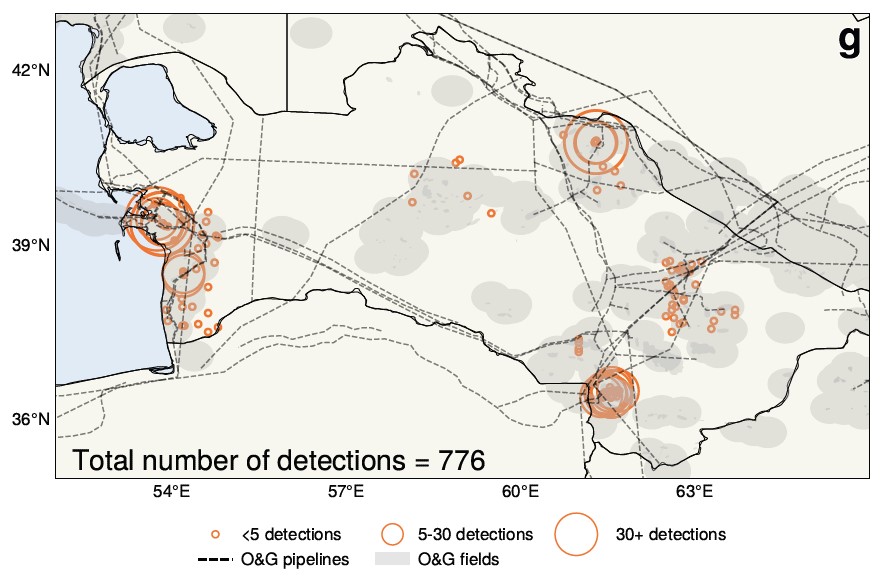
KI half dabei, die hier gezeigten Methanlecks zu finden und zu messen.
„Wir stellen fest, dass der Zusammenbruch der Sowjetunion überraschenderweise zu einem Anstieg der Methanemissionen zu führen scheint“, sagte UW-Professor Alex Turner. Die großen Datensätze und der Mangel an Zeit, sie zu sichten, machten das Thema zu einem natürlichen Ziel für die KI, was zu dieser unerwarteten Umkehrung führte.
Große Sprachmodelle werden größtenteils anhand englischer Quelldaten trainiert, dies kann jedoch mehr als nur ihre Fähigkeit zur Verwendung anderer Sprachen beeinträchtigen. EPFL-Forscher untersuchten die „latente Sprache“ von LlaMa-2 und stellten fest, dass das Modell scheinbar intern auf Englisch zurückgreift, selbst wenn es zwischen Französisch und Chinesisch übersetzt. Die Forscher vermuten jedoch, dass es sich hierbei um mehr als einen verzögerten Übersetzungsprozess handelt, und das Modell hat dies tatsächlich auch getan strukturierte seinen gesamten konzeptionellen latenten Raum um englische Begriffe und Darstellungen herum. Ist es wichtig? Wahrscheinlich. Wir sollten ihre Datensätze sowieso diversifizieren.