
Mit einer so schnelllebigen Branche wie der KI Schritt zu halten, ist eine große Herausforderung. Bis eine KI dies für Sie erledigen kann, finden Sie hier eine praktische Zusammenfassung der neuesten Geschichten aus der Welt des maschinellen Lernens sowie bemerkenswerte Forschungsergebnisse und Experimente, die wir nicht alleine behandelt haben.
Diese Woche veröffentlichte DeepMind, das zu Google gehörende KI-Forschungs- und Entwicklungslabor, im Bereich KI eine Papier Vorschlag eines Rahmens zur Bewertung der gesellschaftlichen und ethischen Risiken von KI-Systemen.
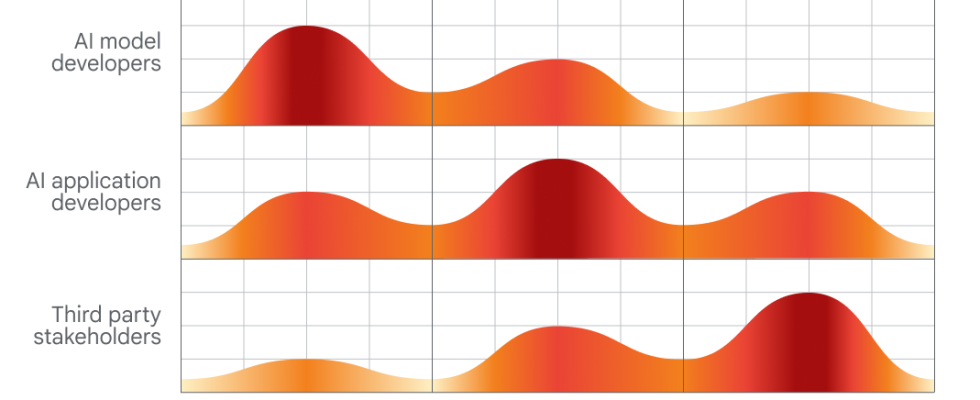
Der Zeitpunkt des Papiers – das eine unterschiedliche Beteiligung von KI-Entwicklern, App-Entwicklern und „breiteren öffentlichen Interessengruppen“ an der Bewertung und Prüfung von KI fordert – ist kein Zufall.
Nächste Woche findet der AI Safety Summit statt, eine von der britischen Regierung gesponserte Veranstaltung, bei der internationale Regierungen, führende KI-Unternehmen, zivilgesellschaftliche Gruppen und Forschungsexperten zusammenkommen, um sich darauf zu konzentrieren, wie die Risiken der neuesten Fortschritte in der KI am besten bewältigt werden können. einschließlich generativer KI (z. B. ChatGPT, Stable Diffusion usw.). Da ist das Vereinigte Königreich Planung eine globale Beratungsgruppe für KI einzurichten, die sich lose am Zwischenstaatlichen Ausschuss für Klimaänderungen der Vereinten Nationen orientiert und aus einer rotierenden Gruppe von Akademikern besteht, die regelmäßig Berichte über die neuesten Entwicklungen in der KI – und die damit verbundenen Gefahren – verfassen.
DeepMind bringt seine Sichtweise vor den politischen Gesprächen vor Ort auf dem zweitägigen Gipfel sehr deutlich zum Ausdruck. Und um die Anerkennung zu würdigen, bringt das Forschungslabor ein paar vernünftige (wenn auch offensichtliche) Punkte vor, wie zum Beispiel die Forderung nach Ansätzen zur Untersuchung von KI-Systemen am „Punkt der menschlichen Interaktion“ und den Möglichkeiten, wie diese Systeme genutzt werden könnten in die Gesellschaft eingebettet.
Diagramm, das zeigt, welche Personen welche Aspekte der KI am besten bewerten können.
Bei der Abwägung der Vorschläge von DeepMind ist es jedoch aufschlussreich, einen Blick darauf zu werfen, wie die Muttergesellschaft des Labors, Google, in einer aktuellen Studie abschneidet Studie veröffentlicht von Stanford-Forschern, in dem zehn wichtige KI-Modelle danach bewertet werden, wie offen sie agieren.
Bewertet nach 100 Kriterien, darunter ob der Hersteller die Quellen seiner Trainingsdaten offengelegt hat, Informationen über die verwendete Hardware, den Arbeitsaufwand für das Training und andere Details, erreicht PaLM 2, eines der Flaggschiff-KI-Modelle von Google zur Textanalyse, eine magere Punktzahl von 40 %.
Nun hat DeepMind PaLM 2 nicht entwickelt – zumindest nicht direkt. Aber das Labor war in der Vergangenheit nicht durchgehend transparent in Bezug auf seine eigenen Modelle, und die Tatsache, dass die Muttergesellschaft wichtige Transparenzmaßnahmen nicht erfüllt, deutet darauf hin, dass von oben nach unten kein großer Druck auf DeepMind ausgeübt wird, es besser zu machen.
Andererseits scheint DeepMind zusätzlich zu seinen öffentlichen Überlegungen zur Politik Schritte zu unternehmen, um die Wahrnehmung zu ändern, dass das Unternehmen in Bezug auf die Architektur und das Innenleben seiner Modelle verschwiegen ist. Das Labor hat sich vor einigen Monaten zusammen mit OpenAI und Anthropic dazu verpflichtet, der britischen Regierung „frühzeitigen oder vorrangigen Zugang“ zu seinen KI-Modellen zu gewähren, um die Forschung zu Evaluierung und Sicherheit zu unterstützen.
Die Frage ist: Ist das bloß performativ? Schließlich würde niemand DeepMind Philanthropie vorwerfen – das Labor erwirtschaftet jedes Jahr Einnahmen in Höhe von Hunderten Millionen Dollar, hauptsächlich durch die interne Lizenzierung seiner Arbeit an Google-Teams.
Der nächste große Ethiktest des Labors ist vielleicht Gemini, sein kommender KI-Chatbot, von dem DeepMind-CEO Demis Hassabis wiederholt versprochen hat, dass er in seinen Fähigkeiten dem ChatGPT von OpenAI Konkurrenz machen wird. Wenn DeepMind im Bereich der KI-Ethik ernst genommen werden möchte, muss es die Schwächen und Grenzen von Gemini vollständig und ausführlich beschreiben – nicht nur seine Stärken. Wir werden sicherlich genau beobachten, wie sich die Dinge in den kommenden Monaten entwickeln.
Hier sind einige andere bemerkenswerte KI-Geschichten der letzten Tage:
- Microsoft-Studie findet Mängel in GPT-4: Eine neue, mit Microsoft verbundene wissenschaftliche Arbeit befasste sich mit der „Vertrauenswürdigkeit“ – und Toxizität – großer Sprachmodelle (LLMs), einschließlich GPT-4 von OpenAI. Die Co-Autoren fanden heraus, dass eine frühere Version von GPT-4 leichter als andere LLMs dazu veranlasst werden kann, toxischen, voreingenommenen Text herauszugeben. Großes Lob.
- ChatGPT erhält Websuche und DALL-E 3: Apropos OpenAI, das Unternehmen offiziell eingeleitet seine Internet-Browsing-Funktion zu ChatGPT, einige drei Wochen nach der Wiedereinführung der Funktion in der Betaphase nach mehreren Monaten Pause. In ähnlichen Nachrichten hat OpenAI auch DALL-E 3 in die Betaphase überführt, einen Monat nach der Einführung der neuesten Version des Text-zu-Bild-Generators.
- Herausforderer von GPT-4V: OpenAI ist bereit, bald GPT-4V zu veröffentlichen, eine Variante von GPT-4, die sowohl Bilder als auch Text versteht. Aber zwei Open-Source-Alternativen schlagen es: LLaVA-1.5 und Fuyu-8B, ein Modell des gut finanzierten Startups Adept. Keines davon ist so leistungsfähig wie GPT-4V, aber beide kommen dem nahe – und was noch wichtiger ist: Sie können kostenlos verwendet werden.
- Kann KI Pokémon spielen?: In den letzten Jahren in Seattle ansässiger Softwareentwickler Peter Whidden hat einen Reinforcement-Learning-Algorithmus trainiert, um sich im klassischen ersten Spiel der Pokémon-Reihe zurechtzufinden. Derzeit erreicht es nur Cerulean City – aber Whidden ist zuversichtlich, dass es sich weiter verbessern wird.
- KI-gestützter Sprachlehrer: Google ist auf der Suche nach Duolingo mit einer neuen Google-Suchfunktion, die Menschen dabei helfen soll, ihre Englischkenntnisse zu üben und zu verbessern. Die neue Funktion wird in den nächsten Tagen auf Android-Geräten in ausgewählten Ländern eingeführt und bietet Sprachlernern, die ins oder aus dem Englischen übersetzen, interaktive Sprechübungen.
- Amazon führt weitere Lagerroboter ein: Bei einer Veranstaltung diese Woche Amazon angekündigt dass es damit beginnen wird, den zweibeinigen Roboter Digit von Agility in seinen Einrichtungen zu testen. Wenn man zwischen den Zeilen liest, gibt es jedoch keine Garantie dafür, dass Amazon tatsächlich damit beginnen wird, Digit in seinen Lagereinrichtungen einzusetzen, in denen derzeit mehr als 750.000 Robotersysteme zum Einsatz kommen, schreibt Brian.
- Simulatoren über Simulatoren: In derselben Woche demonstrierte Nvidia die Anwendung eines LLM, um beim Schreiben von Reinforcement-Learning-Code zu helfen, einen naiven, KI-gesteuerten Roboter bei der besseren Ausführung einer Aufgabe anzuleiten, veröffentlichte Meta Habitat 3.0. Die neueste Version des Meta-Datensatzes zum Training von KI-Agenten in realistischen Innenumgebungen. Habitat 3.0 bietet die Möglichkeit, dass menschliche Avatare den Raum in VR teilen.
- Chinas Tech-Titanen investieren in OpenAI-Rivalen: Zhipu AI, ein in China ansässiges Startup, das KI-Modelle entwickelt, die mit OpenAI und denen anderer im Bereich der generativen KI konkurrieren können, angekündigt gab diese Woche bekannt, dass das Unternehmen in diesem Jahr bislang insgesamt 2,5 Milliarden Yuan (340 Millionen US-Dollar) an Finanzierungen eingesammelt hat. Die Ankündigung erfolgt zu einem Zeitpunkt, an dem die geopolitischen Spannungen zwischen den USA und China zunehmen – und keine Anzeichen für ein Abklingen zeigen.
- Die USA drosseln Chinas Lieferung von KI-Chips: Was die geopolitischen Spannungen betrifft, so kündigte die Biden-Regierung diese Woche eine Reihe von Maßnahmen an, um Pekings militärische Ambitionen einzudämmen, darunter eine weitere Beschränkung der Lieferungen von Nvidias KI-Chips nach China. A800 und H800, die beiden KI-Chips, die Nvidia speziell für den weiteren Versand nach China entwickelt hat, wird von der neuen Runde neuer Regeln betroffen sein.
- KI-Wiederholungen von Popsongs gehen viral: Amanda deckt einen merkwürdigen Trend ab: TikTok-Konten die KI verwenden, um Charaktere wie Homer Simpson dazu zu bringen, Rocksongs der 90er und 2000er Jahre zu singen wie „Riecht nach Teen Spirit.“ Oberflächlich betrachtet sind sie lustig und albern, aber die ganze Praxis hat einen dunklen Unterton, schreibt Amanda.
Mehr maschinelles Lernen
Modelle des maschinellen Lernens führen ständig zu Fortschritten in den Biowissenschaften. AlphaFold und RoseTTAFold waren Beispiele dafür, wie ein hartnäckiges Problem (Proteinfaltung) durch das richtige KI-Modell tatsächlich trivialisiert werden kann. Jetzt haben David Baker (Erfinder des letztgenannten Modells) und seine Laborkollegen den Vorhersageprozess erweitert, um mehr als nur die Struktur der relevanten Aminosäureketten einzubeziehen. Schließlich existieren Proteine in einer Suppe aus anderen Molekülen und Atomen, und die Vorhersage, wie sie mit fremden Verbindungen oder Elementen im Körper interagieren, ist für das Verständnis ihrer tatsächlichen Form und Aktivität von entscheidender Bedeutung. RoseTTAFold All-Atom ist ein großer Fortschritt für die Simulation biologischer Systeme.
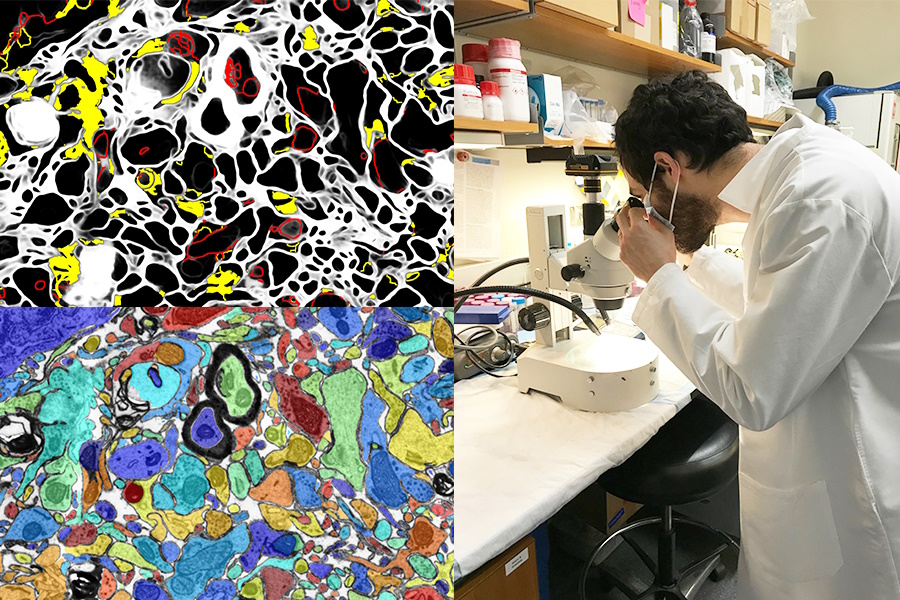
Bildnachweis: MIT/Harvard University
Eine visuelle KI, die die Arbeit im Labor verbessert oder als Lernwerkzeug dient, ist ebenfalls eine großartige Gelegenheit. Das SmartEM-Projekt von MIT und Harvard Integrieren Sie ein Computer-Vision-System und ein ML-Steuerungssystem in ein Rasterelektronenmikroskop, die zusammen das Gerät antreiben, um eine Probe intelligent zu untersuchen. Es kann Bereiche von geringer Bedeutung vermeiden, sich auf interessante oder klare Bereiche konzentrieren und das resultierende Bild auch intelligent kennzeichnen.
Der Einsatz von KI und anderen High-Tech-Tools für archäologische Zwecke wird für mich (wenn Sie so wollen) nie langweilig. Egal, ob es sich um Lidar handelt, das Maya-Städte und -Autobahnen enthüllt oder die Lücken in unvollständigen antiken griechischen Texten füllt, es ist immer cool zu sehen. Und diese Rekonstruktion einer Gedankenrolle, die bei dem Vulkanausbruch, der Pompeji dem Erdboden gleichmachte, zerstört wurde, ist eine der beeindruckendsten, die es je gab.

ML-interpretierter CT-Scan eines verbrannten, zusammengerollten Papyrus. Das sichtbare Wort lautet „Lila“.
Luke Farritor, CS-Student an der University of Nebraska-Lincoln, trainierte ein maschinelles Lernmodell, um die subtilen Muster auf Scans des verkohlten, aufgerollten Papyrus zu verstärken, die für das bloße Auge unsichtbar sind. Dies war eine von vielen Methoden, die im Rahmen eines internationalen Wettbewerbs zum Lesen der Schriftrollen ausprobiert wurden, und sie konnte verfeinert werden, um wertvolle wissenschaftliche Arbeit zu leisten. Viele weitere Informationen finden Sie hier bei Nature. Was war in der Schriftrolle, fragen Sie? Bisher nur das Wort „lila“ – aber selbst das bringt die Papyrologen zum Verzweifeln.
Ein weiterer akademischer Sieg für KI steht bevor Dieses System zur Überprüfung und zum Vorschlagen von Zitaten auf Wikipedia. Natürlich weiß die KI nicht, was wahr oder sachlich ist, aber sie kann aus dem Kontext erkennen, wie ein qualitativ hochwertiger Wikipedia-Artikel und ein Zitat aussehen, und die Website und das Internet nach Alternativen durchsuchen. Niemand schlägt vor, dass wir die Roboter die berühmte benutzergesteuerte Online-Enzyklopädie laufen lassen sollten, aber es könnte helfen, Artikel zu unterstützen, für die es an Zitaten mangelt oder bei denen sich die Redakteure nicht sicher sind.

Beispiel für ein mathematisches Problem, das von Llemma gelöst wird.
Sprachmodelle können für viele Themen feinabgestimmt werden, und höhere Mathematik ist überraschenderweise eines davon. Llemma ist ein neues offenes Modell geschult in mathematischen Beweisen und Arbeiten, die recht komplexe Probleme lösen können. Es ist nicht das erste Mal – Minerva von Google Research arbeitet an ähnlichen Funktionen – aber der Erfolg bei ähnlichen Problemstellungen und die verbesserte Effizienz zeigen, dass „offene“ Modelle (wie auch immer der Begriff genannt wird) in diesem Bereich wettbewerbsfähig sind. Es ist nicht wünschenswert, dass bestimmte Arten von KI von privaten Modellen dominiert werden, daher ist die Nachbildung ihrer Fähigkeiten in der Öffentlichkeit wertvoll, auch wenn dadurch keine neuen Wege beschritten werden.
Besorgniserregend ist, dass Meta in seiner eigenen akademischen Arbeit Fortschritte beim Gedankenlesen macht – aber wie bei den meisten Studien in diesem Bereich übertreibt die Art und Weise, wie es präsentiert wird, den Prozess eher. In einem Artikel mit dem Titel „Gehirndekodierung: Auf dem Weg zur Echtzeit-Rekonstruktion der visuellen Wahrnehmung“ Es mag ein bisschen so wirken, als würden sie direkt Gedanken lesen.

Den Menschen gezeigte Bilder (links) und generative KI erraten, was die Person wahrnimmt (rechts).
Aber es ist etwas indirekter. Durch die Untersuchung, wie ein Hochfrequenz-Gehirnscan aussieht, wenn Menschen Bilder von bestimmten Dingen wie Pferden oder Flugzeugen betrachten, sind die Forscher in der Lage, nahezu in Echtzeit Rekonstruktionen dessen durchzuführen, woran die Person ihrer Meinung nach denkt oder was sie sieht . Dennoch scheint es wahrscheinlich, dass die generative KI hier eine Rolle dabei spielt, wie sie einen visuellen Ausdruck von etwas erzeugen kann, auch wenn dieser nicht direkt mit Scans übereinstimmt.
Sollen Aber wir nutzen KI, um die Gedanken der Menschen zu lesen, wenn das jemals möglich wird? Fragen Sie DeepMind – siehe oben.
Zum Schluss noch ein Projekt bei LAION, das im Moment eher ehrgeizig als konkret ist, aber dennoch lobenswert. Multilingual Contrastive Learning for Audio Representation Acquisition (CLARA) zielt darauf ab, Sprachmodellen ein besseres Verständnis der Nuancen der menschlichen Sprache zu vermitteln. Wissen Sie, wie Sie Sarkasmus oder Flunkerei anhand subverbaler Signale wie Tonfall oder Aussprache erkennen können? Maschinen sind darin ziemlich schlecht, was für jede Mensch-KI-Interaktion eine schlechte Nachricht ist. CLARA nutzt eine Audio- und Textbibliothek in mehreren Sprachen, um einige emotionale Zustände und andere nonverbale „Sprachverständnis“-Hinweise zu identifizieren.