

Mit einer so schnelllebigen Branche wie der KI Schritt zu halten, ist eine große Herausforderung. Bis eine KI dies für Sie erledigen kann, finden Sie hier eine praktische Zusammenfassung der Geschichten der letzten Woche in der Welt des maschinellen Lernens sowie bemerkenswerte Forschungsergebnisse und Experimente, die wir nicht alleine behandelt haben.
Diese Woche dominierte Google den KI-Nachrichtenzyklus mit einer Reihe neuer Produkte, die auf seiner jährlichen I/O-Entwicklerkonferenz vorgestellt wurden. Sie reichen von einer codegenerierenden KI, die mit GitHubs Copilot konkurrieren soll, bis hin zu einem KI-Musikgenerator, der Textansagen in kurze Lieder umwandelt.
Eine ganze Reihe dieser Tools scheinen echte Arbeitsersparnisse zu sein – das heißt mehr als nur Marketing-Füllung. Ich bin besonders fasziniert von Project Tailwind, einer Notizen-App, die KI nutzt, um Dateien aus einem persönlichen Google Docs-Ordner zu organisieren, zusammenzufassen und zu analysieren. Sie offenbaren aber auch die Grenzen und Unzulänglichkeiten selbst der besten KI-Technologien von heute.
Nehmen wir zum Beispiel PaLM 2, Googles neuestes Large Language Model (LLM). PaLM 2 wird das aktualisierte Bard-Chat-Tool von Google unterstützen, den Konkurrenten des Unternehmens zu ChatGPT von OpenAI, und als Grundlage für die meisten neuen KI-Funktionen von Google dienen. Aber während PaLM 2 wie vergleichbare LLMs Code, E-Mails und mehr schreiben kann, antwortet es auch auf giftige und voreingenommene Weise auf Fragen.
Auch der Musikgenerator von Google ist in seinen Möglichkeiten recht begrenzt. Wie ich in meinen eigenen Händen geschrieben habe, klingen die meisten Songs, die ich mit MusicLM erstellt habe, bestenfalls passabel – und im schlimmsten Fall wie ein Vierjähriger, der sich auf ein Lied einlässt DAW.
Es wurde viel darüber geschrieben, wie KI Arbeitsplätze ersetzen wird – laut einer Studie potenziell das Äquivalent von 300 Millionen Vollzeitstellen Bericht von Goldman Sachs. In einem Umfrage Laut Harris befürchten 40 % der Arbeitnehmer, die mit dem KI-gestützten Chatbot-Tool ChatGPT von OpenAI vertraut sind, dass es ihre Jobs vollständig ersetzen wird.
Die KI von Google ist nicht das A und O. Tatsächlich die des Unternehmens wohl im Rückstand im KI-Rennen. Aber es ist eine unbestreitbare Tatsache, die Google anwendet einige der besten KI-Forscher der Welt. Und wenn dies das Beste ist, was sie schaffen können, ist das ein Beweis dafür, dass KI noch lange kein gelöstes Problem ist.
Hier sind die anderen bemerkenswerten KI-Schlagzeilen der letzten Tage:
- Meta bringt generative KI in Anzeigen: Meta hat diese Woche eine Art KI-Sandbox für Werbetreibende angekündigt, die ihnen bei der Erstellung alternativer Kopien, der Hintergrundgenerierung durch Textaufforderungen und dem Zuschneiden von Bildern für Facebook- oder Instagram-Anzeigen helfen soll. Das Unternehmen sagte, dass die Funktionen derzeit ausgewählten Werbetreibenden zur Verfügung stehen und den Zugang im Juli auf weitere Werbetreibende erweitern werden.
- Kontext hinzugefügt: Anthropic hat das Kontextfenster für Claude – sein Flaggschiffmodell der textgenerierenden KI, das sich noch in der Vorschau befindet – von 9.000 Token auf 100.000 Token erweitert. Das Kontextfenster bezieht sich auf den Text, den das Modell berücksichtigt, bevor es zusätzlichen Text generiert, während Token Rohtext darstellen (z. B. würde das Wort „fantastic“ in die Token „fan“, „tas“ und „tic“ aufgeteilt). In der Vergangenheit und auch heute noch war ein schlechtes Gedächtnis ein Hindernis für den Nutzen textgenerierender KI. Aber größere Kontextfenster könnten das ändern.
- Anthropic wirbt für „verfassungsmäßige KI“: Größere Kontextfenster sind nicht das einzige Unterscheidungsmerkmal der Anthropic-Modelle. Das Unternehmen erläuterte diese Woche „Verfassungs-KI“, seine interne KI-Trainingstechnik, die darauf abzielt, KI-Systeme mit „Werten“ zu erfüllen, die durch eine „Verfassung“ definiert sind. Im Gegensatz zu anderen Ansätzen argumentiert Anthropic, dass konstitutionelle KI das Verhalten von Systemen sowohl leichter verständlich als auch bei Bedarf einfacher anzupassen macht.
- Ein LLM für die Forschung: Das gemeinnützige Allen Institute for AI Research (AI2) gab bekannt, dass es plant, ein forschungsorientiertes LLM namens Open Language Model auszubilden und damit die große und wachsende Open-Source-Bibliothek zu erweitern. AI2 betrachtet das Open Language Model, kurz OLMo, als Plattform und nicht nur als Modell – eines, das es der Forschungsgemeinschaft ermöglicht, jede von AI2 erstellte Komponente zu übernehmen und sie entweder selbst zu nutzen oder zu verbessern.
- Neuer Fonds für KI: In anderen AI2-Nachrichten ist AI2 Incubator, der KI-Startup-Fonds der gemeinnützigen Organisation, wieder auf das Dreifache seiner vorherigen Größe gestiegen – 30 Millionen US-Dollar gegenüber 10 Millionen US-Dollar. Seit 2017 haben 21 Unternehmen den Inkubator durchlaufen und rund 160 Millionen US-Dollar an weiteren Investitionen und mindestens einer großen Übernahme angezogen: XNOR, ein Unternehmen für KI-Beschleunigung und -Effizienz, das anschließend von Apple für rund 200 Millionen US-Dollar aufgekauft wurde.
- EU-Einführungsregeln für generative KI: In einer Reihe von Abstimmungen im Europäischen Parlament haben die Abgeordneten diese Woche eine Reihe von Änderungsanträgen zum Entwurf der KI-Gesetzgebung des Blocks unterstützt – einschließlich der Festlegung von Anforderungen für die sogenannten Basismodelle, die generativen KI-Technologien wie ChatGPT von OpenAI zugrunde liegen. Durch die Änderungen wird den Anbietern von Basismodellen die Verpflichtung auferlegt, Sicherheitsüberprüfungen, Data-Governance-Maßnahmen und Risikominderungen durchzuführen, bevor sie ihre Modelle auf den Markt bringen
- Ein universeller Übersetzer: Google testet einen leistungsstarken neuen Übersetzungsdienst, der Videos in eine neue Sprache umwandelt und gleichzeitig die Lippen des Sprechers mit Wörtern synchronisiert, die er nie gesprochen hat. Es könnte aus vielen Gründen sehr nützlich sein, aber das Unternehmen warnte offen vor der Möglichkeit eines Missbrauchs und den Maßnahmen, die ergriffen wurden, um ihn zu verhindern.
- Automatisierte Erklärungen: Es wird oft gesagt, dass LLMs nach dem Vorbild von OpenAIs ChatGPT eine Blackbox seien, und daran ist sicherlich etwas Wahres dran. OpenAI ist bestrebt, diese Schichten aufzulösen Entwicklung ein Tool zur automatischen Identifizierung, welche Teile eines LLM für welches seiner Verhaltensweisen verantwortlich sind. Die Ingenieure dahinter betonen, dass es sich noch im Anfangsstadium befindet, der Code für die Ausführung jedoch seit dieser Woche als Open Source auf GitHub verfügbar ist.
- IBM führt neue KI-Dienste ein: Auf seiner jährlichen Think-Konferenz kündigte IBM IBM Watsonx an, eine neue Plattform, die Tools zum Erstellen von KI-Modellen bereitstellt und Zugriff auf vorab trainierte Modelle zum Generieren von Computercode, Text und mehr bietet. Das Unternehmen gibt an, dass die Einführung durch die Herausforderungen motiviert war, mit denen viele Unternehmen immer noch bei der Bereitstellung von KI am Arbeitsplatz konfrontiert sind.
Andere maschinelles Lernen
Bildnachweis: Landungs-KI
Andrew Ngs neues Unternehmen Landungs-KI verfolgt einen intuitiveren Ansatz bei der Erstellung von Computer-Vision-Schulungen. Einem Modell verständlich zu machen, was man in Bildern identifizieren möchte, ist aber ziemlich mühsam ihre Technik der „visuellen Aufforderung“. Mit nur wenigen Pinselstrichen können Sie Ihre Absicht erkennen. Jeder, der Segmentierungsmodelle erstellen muss, sagt „Mein Gott, endlich!“ Wahrscheinlich viele Doktoranden, die derzeit Stunden damit verbringen, Organellen und Haushaltsgegenstände zu maskieren.
Microsoft hat sich beworben Diffusionsmodelle auf einzigartige und interessante Weise, indem es sie im Wesentlichen verwendet, um einen Aktionsvektor anstelle eines Bildes zu erzeugen, nachdem es auf viele beobachtete menschliche Aktionen trainiert wurde. Es ist noch sehr früh und Diffusion ist hierfür nicht die offensichtliche Lösung, aber da sie stabil und vielseitig sind, ist es interessant zu sehen, wie sie über rein visuelle Aufgaben hinaus eingesetzt werden können. Ihr Papier wird später in diesem Jahr beim ICLR vorgestellt.
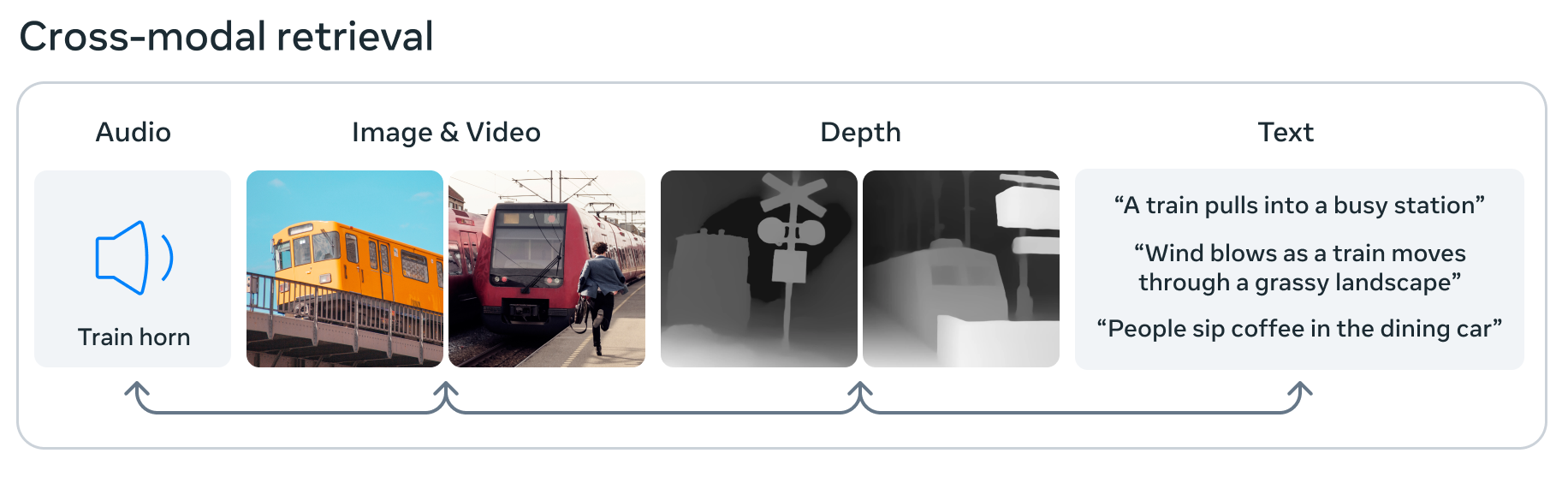
Bildnachweis: Meta
Meta stößt auch an die Grenzen der KI ImageBind, das angeblich das erste Modell ist, das Daten aus sechs verschiedenen Modalitäten verarbeiten und integrieren kann: Bilder und Video, Audio, 3D-Tiefendaten, thermische Informationen sowie Bewegungs- oder Positionsdaten. Das bedeutet, dass in seinem kleinen Einbettungsraum für maschinelles Lernen ein Bild mit einem Ton, einer 3D-Form und verschiedenen Textbeschreibungen verknüpft werden kann, nach denen jede gefragt oder zur Entscheidungsfindung verwendet werden kann. Es ist ein Schritt in Richtung einer „allgemeinen“ KI, da sie Daten eher wie das Gehirn aufnimmt und verknüpft – aber sie ist immer noch einfach und experimentell, also seien Sie noch nicht zu aufgeregt.
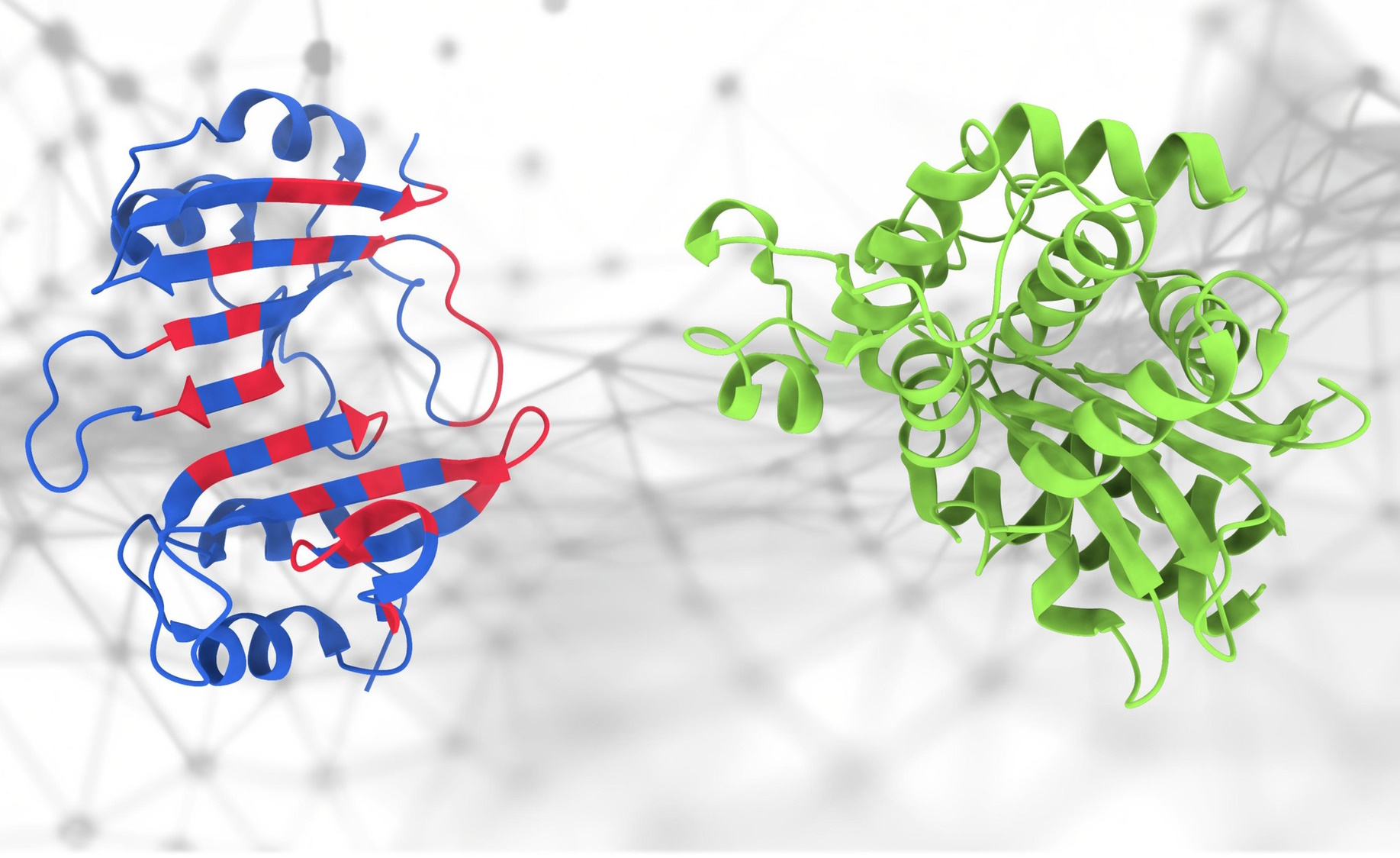
Wenn sich diese Proteine berühren … was passiert?
Jeder war von AlphaFold begeistert, und das aus gutem Grund, aber Struktur ist eigentlich nur ein kleiner Teil der sehr komplexen Wissenschaft der Proteomik. Die Art und Weise, wie diese Proteine interagieren, ist sowohl wichtig als auch schwer vorherzusagen – aber das ist neu PeSTo-Modell der EPFL versucht genau das zu tun. „Es konzentriert sich auf wichtige Atome und Wechselwirkungen innerhalb der Proteinstruktur“, sagte Hauptentwickler Lucien Krapp. „Das bedeutet, dass diese Methode die komplexen Wechselwirkungen innerhalb von Proteinstrukturen effektiv erfasst, um eine genaue Vorhersage von Proteinbindungsschnittstellen zu ermöglichen.“ Auch wenn es nicht genau oder 100 % zuverlässig ist, ist es für Forscher sehr nützlich, nicht bei Null anfangen zu müssen.
Die Regierung legt großen Wert auf KI. Der Präsident kam sogar vorbei Treffen mit einer Reihe Top-KI-CEOs um zu sagen, wie wichtig es ist, dies richtig zu machen. Vielleicht sind einige Unternehmen nicht unbedingt die Richtigen, aber sie haben zumindest einige Ideen, die es wert sind, in Betracht gezogen zu werden. Aber sie haben doch schon Lobbyisten, oder?
Ich bin mehr gespannt darauf Neue KI-Forschungszentren entstehen mit Bundesmitteln. Grundlagenforschung ist dringend erforderlich, um ein Gegengewicht zur produktorientierten Arbeit von Unternehmen wie OpenAI und Google zu bilden – wenn es also KI-Zentren mit dem Auftrag gibt, Dinge wie zu untersuchen Sozialwissenschaften (an der CMU)oder Klimawandel und Landwirtschaft (an der U of Minnesota), es fühlt sich an wie grüne Felder (sowohl im übertragenen als auch im wörtlichen Sinne). Allerdings möchte ich auch einen kleinen Gruß dazu aussprechen Metaforschung zur forstwirtschaftlichen Messung.

Gemeinsam KI auf einer großen Leinwand machen – das ist Wissenschaft!
Es gibt viele interessante Gespräche über KI. ich dachte Dieses Interview mit den UCLA-Wissenschaftlern Jacob Foster und Danny Snelson (meine Alma Mater, go Bruins). war interessant. Hier ist ein toller Gedanke zu LLMs, um so zu tun, als hätten Sie ihn sich dieses Wochenende ausgedacht, als die Leute über KI reden:
Diese Systeme zeigen, wie formal konsistent die meisten Schriften sind. Je allgemeiner die Formate sind, die diese Vorhersagemodelle simulieren, desto erfolgreicher sind sie. Diese Entwicklungen drängen uns dazu, die normativen Funktionen unserer Formen zu erkennen und sie möglicherweise zu transformieren. Nach der Einführung der Fotografie, die sehr gut darin ist, einen Darstellungsraum einzufangen, entwickelte sich im malerischen Milieu der Impressionismus, ein Stil, der eine genaue Darstellung völlig ablehnte und sich stattdessen auf die Materialität der Farbe selbst beschränkte.
Das werde ich auf jeden Fall nutzen!