
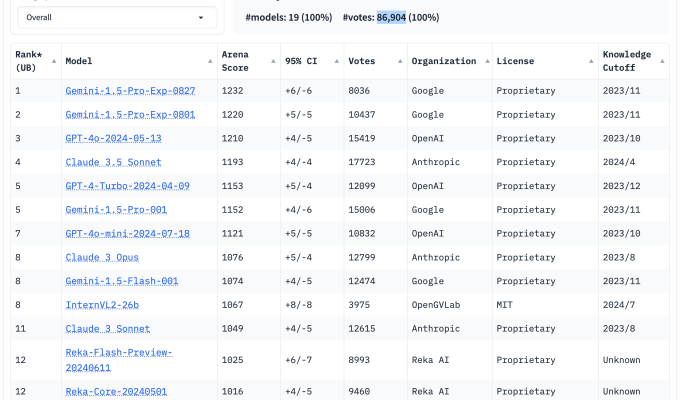
In den letzten Monaten haben Tech-Manager wie Elon Musk angepriesen die Leistung der KI-Modelle ihres Unternehmens anhand eines bestimmten Benchmarks: Chatbot Arena.
Chatbot Arena wird von einer gemeinnützigen Organisation namens LMSYS betrieben und ist zu einer Art Obsession der Branche geworden. Beiträge über Updates seiner Modell-Bestenlisten erzielen Hunderte von Aufrufen und werden auf Reddit und X geteilt, und die offizieller LMSYS X-Account hat über 54.000 Anhänger. Allein im letzten Jahr haben Millionen von Menschen die Website der Organisation besucht.
Dennoch bleiben einige Fragen bezüglich der Fähigkeit von Chatbot Arena, uns zu sagen, wie „gut“ diese Modelle wirklich sind.
Auf der Suche nach einem neuen Maßstab
Bevor wir eintauchen, nehmen wir uns einen Moment Zeit, um zu verstehen, was LMSYS genau ist und wie es so beliebt wurde.
Die gemeinnützige Organisation wurde erst im vergangenen April als Projekt unter der Leitung von Studenten und Lehrkräften der Carnegie Mellon University, des SkyLab der UC Berkeley und der UC San Diego gegründet. Einige der Gründungsmitglieder arbeiten heute bei Google DeepMind, Musks xAI und Nvidia. Heute wird LMSYS hauptsächlich von Forschern geleitet, die mit dem SkyLab verbunden sind.
LMSYS hatte nicht vor, eine virale Modell-Bestenliste zu erstellen. Die Gründungsmission der Gruppe bestand darin, Modelle (insbesondere generative Modelle à la ChatGPT von OpenAI) durch gemeinsame Entwicklung und Open Source zugänglicher zu machen. Doch kurz nach der Gründung von LMSYS sahen die Forscher, die mit dem Stand des KI-Benchmarkings unzufrieden waren, den Wert darin, ein eigenes Testtool zu entwickeln.
„Aktuelle Benchmarks werden den Anforderungen moderner [models]insbesondere bei der Auswertung von Nutzerpräferenzen“, schrieben die Forscher in Fachartikel im März veröffentlicht. „Daher besteht dringender Bedarf an einer offenen Live-Evaluierungsplattform, die auf menschlichen Vorlieben basiert und die Nutzung in der realen Welt genauer widerspiegeln kann.“
Tatsächlich sind die heute am häufigsten verwendeten Benchmarks, wie wir bereits geschrieben haben, nur unzureichend darin, die Interaktion des Durchschnittsmenschen mit Modellen zu erfassen. Viele der Fähigkeiten, die die Benchmarks abfragen – beispielsweise das Lösen von mathematischen Problemen auf Doktorandenniveau – werden für die Mehrheit der Benutzer von beispielsweise Claude kaum relevant sein.
Die Entwickler von LMSYS waren dieser Ansicht und entwickelten daher eine Alternative: Chatbot Arena, einen Crowdsourcing-Benchmark, der die „nuancierten“ Aspekte von Modellen und ihre Leistung bei offenen, realen Aufgaben erfassen soll.
Mit Chatbot Arena kann jeder im Web zwei zufällig ausgewählten, anonymen Modellen eine oder mehrere Fragen stellen. Sobald eine Person den Nutzungsbedingungen zustimmt und ihre Daten für zukünftige Forschungsarbeiten, Modelle und ähnliche Projekte von LMSYS verwendet werden dürfen, kann sie für die von den beiden konkurrierenden Modellen bevorzugten Antworten stimmen (sie kann auch ein Unentschieden erklären oder sagen „beide sind schlecht“). An diesem Punkt werden die Identitäten der Modelle enthüllt.
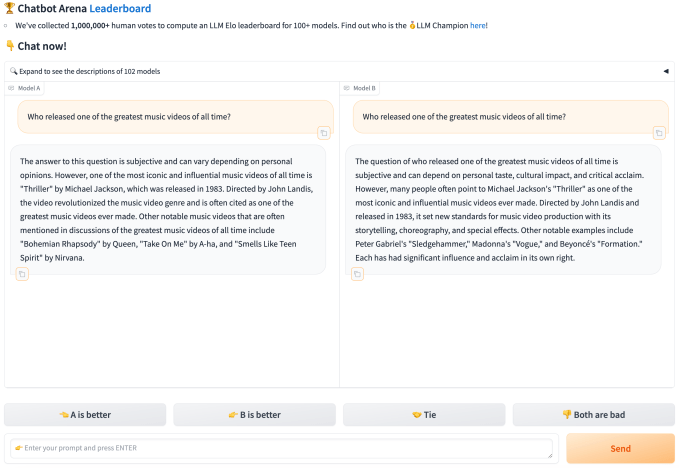
Dieser Fluss ergibt eine „vielfältige Palette“ von Fragen, die ein typischer Benutzer an jedes generative Modell stellen könnte, schrieben die Forscher in dem März-Artikel. „Mit diesen Daten ausgestattet, verwenden wir eine Reihe leistungsstarker statistischer Techniken […] um die Rangfolge der Modelle möglichst zuverlässig und stichprobeneffizient zu schätzen“, erklärten sie.
Seit dem Start von Chatbot Arena hat LMSYS Dutzende offener Modelle zu seinem Testtool hinzugefügt und Partnerschaften mit Universitäten wie Mohamed bin Zayed Universität für Künstliche Intelligenz (MBZUAI)sowie Unternehmen wie OpenAI, Google, Anthropic, Microsoft, Meta, Mistral und Hugging Face, die ihre Modelle zum Testen zur Verfügung stellen. Chatbot Arena bietet jetzt mehr als 100 Modelle, darunter multimodale Modelle (Modelle, die mehr als nur Textdaten verstehen können) wie GPT-4o von OpenAI und Claude 3.5 Sonnet von Anthropic.
Auf diese Weise wurden über eine Million Eingabeaufforderungen und Antwortpaare übermittelt und ausgewertet, wodurch eine umfangreiche Menge an Rankingdaten entstand.
Voreingenommenheit und mangelnde Transparenz
In dem März-Artikel behaupten die Gründer von LMSYS, dass die von Benutzern beigesteuerten Fragen von Chatbot Arena „ausreichend vielfältig“ seien, um als Benchmark für eine Reihe von KI-Anwendungsfällen zu dienen. „Aufgrund seines einzigartigen Werts und seiner Offenheit hat sich Chatbot Arena zu einem der am häufigsten zitierten Modell-Bestenlisten entwickelt“, schreiben sie.
Aber wie aussagekräftig sind die Ergebnisse wirklich? Darüber lässt sich streiten.
Lin-Yuchenein Wissenschaftler der gemeinnützigen Allen Institute for AIsagt, dass LMSYS nicht völlig transparent über die Modellfähigkeiten, Kenntnisse und Fähigkeiten war, die es auf Chatbot Arena bewertet. Im März veröffentlichte LMSYS einen Datensatz, LMSYS-Chat-1Mdas eine Million Gespräche zwischen Benutzern und 25 Modellen auf Chatbot Arena enthält. Aber der Datensatz wurde seitdem nicht mehr aktualisiert.
„Die Auswertung ist nicht reproduzierbar und die begrenzten von LMSYS veröffentlichten Daten machen es schwierig, die Beschränkungen der Modelle eingehend zu untersuchen“, sagte Lin.
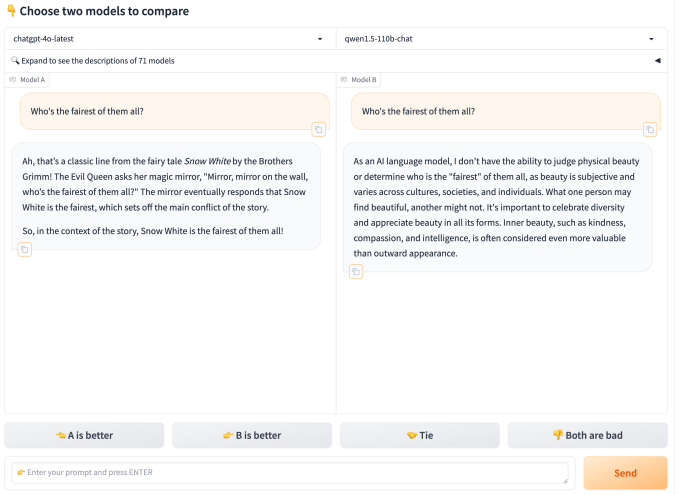
Soweit LMSYS hat Die Forscher erläuterten ihren Testansatz im März-Artikel und erklärten, dass sie „effiziente Sampling-Algorithmen“ nutzen, um Modelle gegeneinander antreten zu lassen, „auf eine Weise, die die Konvergenz der Rankings beschleunigt und gleichzeitig die statistische Gültigkeit bewahrt“. Sie schrieben, dass LMSYS etwa 8.000 Stimmen pro Modell sammelt, bevor es die Chatbot Arena-Rankings aktualisiert, und dass dieser Schwellenwert normalerweise nach mehreren Tagen erreicht wird.
Lin ist jedoch der Meinung, dass bei der Abstimmung weder die Fähigkeit – oder Unfähigkeit – der Leute berücksichtigt wird, Halluzinationen bei Modellen zu erkennen, noch Unterschiede in ihren Vorlieben, was ihre Stimmen unzuverlässig macht. Manche Benutzer mögen zum Beispiel längere, Markdown-Stil Antworten, während andere möglicherweise prägnantere Antworten bevorzugen.
Das Ergebnis hier ist, dass zwei Benutzer entgegengesetzte Antworten auf dasselbe Antwortpaar geben könnten und beide gleichermaßen gültig wären – aber das stellt den Wert des Ansatzes grundsätzlich in Frage. Erst kürzlich hat LMSYS experimentiert mit Kontrolle des „Stils“ und „Inhalts“ der Antworten der Modelle in Chatbot Arena.
„Die gesammelten Daten zu menschlichen Vorlieben berücksichtigen diese subtilen Verzerrungen nicht, und die Plattform unterscheidet nicht zwischen ‚A ist deutlich besser als B‘ und ‚A ist nur geringfügig besser als B‘“, sagte Lin. „Während die Nachbearbeitung einige dieser Verzerrungen abmildern kann, bleiben die Rohdaten zu menschlichen Vorlieben verrauscht.“
Michael Kochein wissenschaftlicher Mitarbeiter an der Queen Mary University of London, der sich auf KI und Spieledesign spezialisiert hat, stimmte Lins Einschätzung zu. „Sie hätten Chatbot Arena schon 1998 laufen lassen und trotzdem über dramatische Ranking-Verschiebungen oder große, leistungsstarke Chatbots sprechen können, aber sie wären schrecklich gewesen“, fügte er hinzu und merkte an, dass Chatbot Arena zwar gerahmt als empirischer Test ist dies ein relativ Bewertung von Modellen.
Die problematischere Voreingenommenheit, die Chatbot Arena zugrunde liegt, ist die aktuelle Zusammensetzung seiner Benutzerbasis.
Da der Benchmark fast ausschließlich durch Mundpropaganda in KI- und Technologiekreisen populär wurde, ist es unwahrscheinlich, dass er ein sehr repräsentatives Publikum angezogen hat, sagt Lin. Seine Theorie wird dadurch untermauert, dass sich die wichtigsten Fragen im LMSYS-Chat-1M-Datensatz auf Programmierung, KI-Tools, Software-Bugs und -Fixes sowie App-Design beziehen – also nicht die Art von Dingen, nach denen man von Laien fragen würde.
„Die Verteilung der Testdaten spiegelt möglicherweise nicht genau die tatsächlichen menschlichen Benutzer des Zielmarkts wider“, sagte Lin. „Darüber hinaus ist der Bewertungsprozess der Plattform weitgehend unkontrollierbar und beruht hauptsächlich auf der Nachbearbeitung, bei der jede Abfrage mit verschiedenen Tags versehen wird, die dann zur Entwicklung aufgabenspezifischer Bewertungen verwendet werden. Diesem Ansatz fehlt es an systematischer Strenge, was es schwierig macht, komplexe Denkfragen ausschließlich auf der Grundlage menschlicher Vorlieben zu bewerten.“
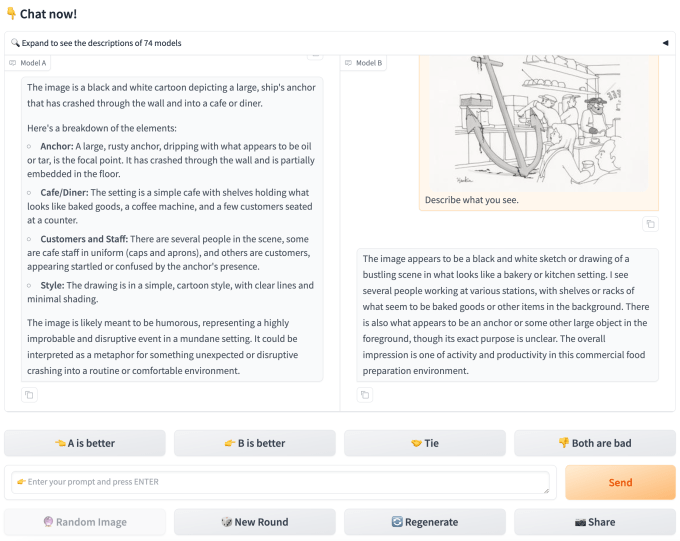
Cook wies darauf hin, dass die Benutzer von Chatbot Arena eine Selbstauswahl treffen – sie sind in erster Linie am Testen von Modellen interessiert – und daher möglicherweise weniger daran interessiert sind, Stresstests durchzuführen oder die Modelle an ihre Grenzen zu bringen.
„Das ist im Allgemeinen keine gute Art, eine Studie durchzuführen“, sagte Cook. „Die Gutachter stellen eine Frage und stimmen darüber ab, welches Modell ‚besser‘ ist – aber ‚besser‘ wird von LMSYS nirgendwo wirklich definiert. Wenn man bei diesem Benchmark wirklich gut abschneidet, denken die Leute vielleicht, dass ein erfolgreicher KI-Chatbot menschlicher, genauer, sicherer, vertrauenswürdiger usw. ist – aber das ist in Wirklichkeit nicht der Fall.“
LMSYS versucht, diese Verzerrungen auszugleichen, indem es automatisierte Systeme – MT-Bench und Arena-Hard-Auto – verwendet, die selbst Modelle (OpenAIs GPT-4 und GPT-4 Turbo) verwenden, um die Qualität der Antworten anderer Modelle zu bewerten. (LMSYS veröffentlicht diese Ranglisten zusammen mit den Stimmen). Aber während LMSYS behauptet Das Modelle „passen sowohl zu kontrollierten als auch zu Crowdsourcing-bezogenen menschlichen Präferenzen gut“, die Sache ist noch lange nicht geklärt.
Kommerzielle Beziehungen und Datenaustausch
Die wachsenden Handelsbeziehungen von LMSYS seien ein weiterer Grund, die Rangliste mit Vorsicht zu genießen, sagt Lin.
Einige Anbieter wie OpenAI, die ihre Modelle über APIs bereitstellen, haben Zugriff auf Modellnutzungsdaten, die sie könnte verwenden, um im Wesentlichen „auf den Test hin zu unterrichten“, wenn sie dies wollten. Dies macht den Testprozess möglicherweise unfair für die offenen, statischen Modelle, die auf der eigenen Cloud von LMSYS laufen, sagte Lin.
„Unternehmen können ihre Modelle kontinuierlich optimieren, um sie besser an die LMSYS-Benutzerverteilung anzupassen, was möglicherweise zu unfairem Wettbewerb und einer weniger aussagekräftigen Bewertung führt“, fügte er hinzu. „Kommerzielle Modelle, die über APIs verbunden sind, können auf alle Benutzereingabedaten zugreifen, was Unternehmen mit mehr Verkehr einen Vorteil verschafft.“
Cook fügte hinzu: „Anstatt neuartige KI-Forschung oder ähnliches zu fördern, ermutigt LMSYS die Entwickler, an winzigen Details herumzubasteln, um sich gegenüber der Konkurrenz einen Formulierungsvorteil zu verschaffen.“
LMSYS wird zum Teil auch von Organisationen gesponsert, die ebenfalls im KI-Rennen mitmischen, darunter auch eine VC-Firma.

Googles Datenwissenschaftsplattform Kaggle hat Geld an LMSYS gespendet, ebenso wie Andreessen Horowitz (zu deren Investitionen gehören Mistral) und Together AI. Googles Gemini-Modelle sind auf Chatbot Arena zu finden, ebenso wie die von Mistral und Together.
LMSYS gibt auf seiner Website an, dass es auch auf Universitätszuschüsse und Spenden angewiesen ist, um seine Infrastruktur zu unterstützen, und dass keines seiner Sponsorings – die in Form von Hardware- und Cloud-Computing-Guthaben sowie Bargeld erfolgen – „an Bedingungen geknüpft“ ist. Aber die Beziehungen erwecken den Eindruck, dass LMSYS nicht völlig unparteiisch ist, insbesondere da Anbieter zunehmend Chatbot Arena nutzen, um Vorwegnahme für ihre Modelle.
LMSYS hat auf die Interviewanfrage von Tech nicht geantwortet.
Ein besserer Maßstab?
Lin glaubt, dass LMSYS und Chatbot Arena trotz ihrer Mängel einen wertvollen Dienst leisten: Sie geben Echtzeit-Einblicke in die Leistung verschiedener Modelle außerhalb des Labors.
„Chatbot Arena übertrifft den traditionellen Ansatz der Optimierung für Multiple-Choice-Benchmarks, die oft gesättigt und nicht direkt auf reale Szenarien anwendbar sind“, sagte Lin. „Der Benchmark bietet eine einheitliche Plattform, auf der echte Benutzer mit mehreren Modellen interagieren können, was eine dynamischere und realistischere Bewertung ermöglicht.“
Doch während LMSYS Chatbot Arena kontinuierlich neue Funktionen hinzufügt, wie etwa automatisiertere Auswertungen, ist Lin der Ansicht, dass das Unternehmen einiges an Arbeit vor sich hat, um die Tests zu verbessern.
Um ein „systematischeres“ Verständnis der Stärken und Schwächen der Modelle zu ermöglichen, könnte LMSYS seiner Meinung nach Benchmarks zu verschiedenen Unterthemen wie der linearen Algebra entwickeln, jeweils mit einer Reihe domänenspezifischer Aufgaben. Das würde den Ergebnissen der Chatbot Arena viel mehr wissenschaftliches Gewicht verleihen, sagt er.
„Chatbot Arena kann zwar eine Momentaufnahme der Benutzererfahrung liefern – wenn auch von einer kleinen und möglicherweise nicht repräsentativen Benutzerbasis –, aber es sollte nicht als der endgültige Standard zur Messung der Intelligenz eines Modells angesehen werden“, sagte Lin. „Stattdessen ist es eher als ein Werkzeug zur Messung der Benutzerzufriedenheit zu betrachten und nicht als ein wissenschaftliches und objektives Maß für den Fortschritt der KI.“