
Eines der ersten Dinge, die man in der Welt der Robotik entdeckt, ist die Komplexität einfacher Aufgaben. Dinge, die für Menschen einfach erscheinen, haben potenziell unendliche Variablen, die wir für selbstverständlich halten. Roboter haben keinen solchen Luxus.
Genau aus diesem Grund konzentriert sich ein Großteil der Branche auf wiederholbare Aufgaben in strukturierten Umgebungen. Glücklicherweise hat die Welt des Roboterlernens in den letzten Jahren einige bahnbrechende Durchbrüche erlebt, und die Branche ist auf dem richtigen Weg, anpassungsfähigere Systeme zu entwickeln und einzusetzen.
Letztes Jahr das Robotik-Team von Google DeepMind präsentiert Robotics Transformer – RT-1 – das seine Everyday Robot-Systeme darauf trainierte, Aufgaben wie das Auswählen und Platzieren sowie das Öffnen von Ziehungen auszuführen. Das System basierte auf einer Datenbank mit 130.000 Demonstrationen, was nach Angaben des Teams zu einer Erfolgsquote von 97 % bei „über 700“ Aufgaben führte.
Bildnachweis: Google DeepMind
Heute wird RT-2 enthüllt. In ein Blogbeitragsagt Vincent Vanhoucke, Distinguished Scientist und Head of Robotics bei DeepMind, dass das System es Robotern ermöglicht, Konzepte, die auf relativ kleinen Datensätzen gelernt wurden, effektiv auf verschiedene Szenarien zu übertragen.
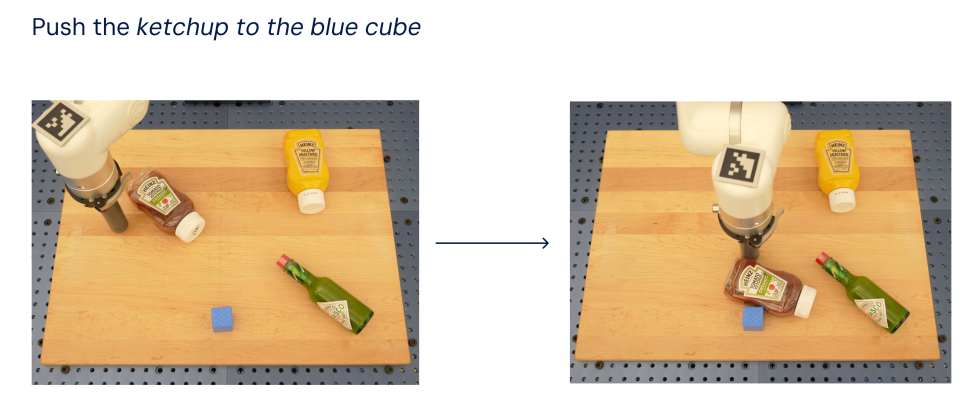
„RT-2 zeigt verbesserte Generalisierungsfähigkeiten und semantisches und visuelles Verständnis über die Roboterdaten hinaus, denen es ausgesetzt war“, erklärt Google. „Dazu gehört die Interpretation neuer Befehle und die Reaktion auf Benutzerbefehle durch die Durchführung rudimentärer Überlegungen, beispielsweise Überlegungen zu Objektkategorien oder Beschreibungen auf hoher Ebene.“ Das System demonstriert effektiv die Fähigkeit, auf der Grundlage vorhandener Kontextinformationen beispielsweise das beste Werkzeug für eine bestimmte neuartige Aufgabe zu bestimmen.
Vanhoucke zitiert ein Szenario, in dem ein Roboter gebeten wird, Müll wegzuwerfen. Bei vielen Modellen muss der Benutzer dem Roboter beibringen, zu erkennen, was als Müll gilt, und ihm dann beibringen, den Müll aufzusammeln und wegzuwerfen. Es handelt sich um eine Detailebene, die nicht besonders skalierbar für Systeme ist, von denen erwartet wird, dass sie eine Reihe unterschiedlicher Aufgaben ausführen.
„Da RT-2 in der Lage ist, Wissen aus einem großen Korpus an Webdaten zu übertragen, hat es bereits eine Vorstellung davon, was Müll ist, und kann ihn ohne explizite Schulung identifizieren“, schreibt Vanhoucke. „Es hat sogar eine Idee, wie man den Müll wegwirft, obwohl es nie darauf trainiert wurde, so etwas zu tun. Und denken Sie an die abstrakte Natur von Müll – was eine Tüte Chips oder eine Bananenschale war, wird zu Müll, nachdem Sie sie gegessen haben. RT-2 ist in der Lage, dies anhand seiner Vision-Language-Trainingsdaten zu verstehen und die Aufgabe zu erledigen.“
Das Team gibt an, dass sich die Wirksamkeitsrate bei der Ausführung neuer Aufgaben beim Sprung von RT-1 auf RT-2 von 32 % auf 62 % verbessert hat.