

Die Forschung im Bereich maschinelles Lernen und KI, mittlerweile eine Schlüsseltechnologie in praktisch jeder Branche und jedem Unternehmen, ist viel zu umfangreich, als dass man sie vollständig lesen könnte. Diese Kolumne, Perceptron (früher Deep Science), zielt darauf ab, einige der relevantesten jüngsten Entdeckungen und Artikel zu sammeln – insbesondere im Bereich der künstlichen Intelligenz, aber nicht darauf beschränkt – und zu erklären, warum sie wichtig sind.
Diese Woche in KI, Ingenieure bei Penn State angekündigt dass sie einen Chip entwickelt haben, der fast zwei Milliarden Bilder pro Sekunde verarbeiten und klassifizieren kann. Carnegie Mellon hingegen schon unterzeichnet einen Auftrag der US-Armee über 10,5 Millionen US-Dollar zur Ausweitung des Einsatzes von KI in der vorausschauenden Wartung. Und an der UC Berkeley wendet ein Team von Wissenschaftlern KI-Forschung an, um Klimaprobleme zu lösen, wie z Verständnis Schnee als Wasserressource.
Die Arbeit der Penn State zielte darauf ab, die Einschränkungen herkömmlicher Prozessoren bei der Anwendung auf KI-Workloads zu überwinden – insbesondere das Erkennen und Klassifizieren von Bildern oder den darin enthaltenen Objekten. Bevor ein maschinelles Lernsystem ein Bild verarbeiten kann, muss es vom Bildsensor einer Kamera erfasst werden (vorausgesetzt, es handelt sich um ein reales Bild), vom Sensor von Licht in elektrische Signale umgewandelt und dann wieder in binäre Daten umgewandelt. Nur dann kann das System das Bild ausreichend „verstehen“, um es zu verarbeiten, zu analysieren und zu klassifizieren.
Ingenieure der Penn State, darunter der Postdoktorand Farshid Ashtiani, der Doktorand Alexander J. Geers und der außerordentliche Professor für Elektro- und Systemtechnik Firooz Aflatouni, haben eine Problemumgehung entwickelt, von der sie behaupten, dass sie die zeitaufwändigsten Aspekte der traditionellen Chip-basierten KI-Bildverarbeitung beseitigt. Ihr kundenspezifischer 9,3-Quadratmillimeter-Prozessor verarbeitet Licht, das von einem „Objekt von Interesse“ empfangen wird, direkt unter Verwendung eines sogenannten „optischen tiefen neuronalen Netzwerks“.
3D-Rendering, Computerplatine mit Schaltkreisen und Chip
Im Wesentlichen verwendet der Prozessor der Forscher „optische Neuronen“, die über optische Drähte, sogenannte Wellenleiter, miteinander verbunden sind, um ein tiefes Netzwerk aus vielen Schichten zu bilden. Informationen werden durch die Schichten geleitet, wobei jeder Schritt dazu beiträgt, das Eingabebild in eine seiner erlernten Kategorien einzuordnen. Dank der Fähigkeit des Chips zu rechnen, während sich Licht durch ihn ausbreitet, und optische Signale direkt zu lesen und zu verarbeiten, behaupten die Forscher, dass der Chip keine Informationen speichern muss und eine vollständige Bildklassifizierung in etwa einer halben Nanosekunde durchführen kann.
„Wir sind nicht die Ersten, die eine Technologie entwickelt haben, die optische Signale direkt liest“, sagte Geers in einer Erklärung, „aber wir sind die Ersten, die das komplette System in einem Chip schaffen, der sowohl mit bestehender Technologie kompatibel als auch skalierbar ist mit komplexeren Daten.“ Er erwartet, dass die Arbeit Anwendungen bei der automatischen Erkennung von Text in Fotos, der Unterstützung selbstfahrender Autos bei der Erkennung von Hindernissen und anderen Aufgaben im Zusammenhang mit Computer Vision haben wird.
Drüben bei Carnegie Mellon konzentriert sich das Auton Lab des Colleges auf eine andere Reihe von Anwendungsfällen: die Anwendung vorausschauender Wartungstechniken auf alles, von Bodenfahrzeugen bis hin zu Stromgeneratoren. Unterstützt durch den oben genannten Vertrag wird Artur Dubrawski, Direktor des Auton Lab, die Grundlagenforschung leiten, um die Anwendbarkeit von Computermodellen komplexer physikalischer Systeme, die als digitale Zwillinge bekannt sind, auf viele Bereiche auszudehnen.
Technologien für digitale Zwillinge sind nicht neu. GEAWS und andere Unternehmen bieten Produkte an, mit denen Kunden modellieren können digitale Zwillinge von Maschinen. In London ansässig SenSa erstellt digitale Zwillingsmodelle von Standorten für Bau-, Bergbau- und Energieprojekte. Unterdessen bauen Startups wie Lacuna und Nexar digitale Zwillinge ganzer Städte.
Aber Technologien für digitale Zwillinge haben die gleichen Einschränkungen, vor allem die ungenaue Modellierung, die von ungenauen Daten ausgeht. Wie überall heißt es Müll rein, Müll raus.
Um dieses und andere Hindernisse für eine breitere Nutzung digitaler Zwillinge anzugehen, arbeitet das Team von Dubrawski mit einer Reihe von Interessengruppen zusammen, wie z. B. Klinikern auf der Intensivstation, um Szenarien zu untersuchen, einschließlich im Gesundheitswesen. Das Auton Lab zielt darauf ab, neue, effizientere Methoden zur „Erfassung menschlichen Fachwissens“ zu entwickeln, damit KI-Systeme Kontexte verstehen können, die in Daten nicht gut dargestellt sind, sowie Methoden, um dieses Fachwissen mit Benutzern zu teilen.
Eine Sache, die KI bald haben könnte, die einigen Menschen zu fehlen scheint, ist der gesunde Menschenverstand. DARPA hat eine Reihe von Initiativen finanziert in verschiedenen Labors, die darauf abzielen, Robotern ein allgemeines Gefühl dafür zu vermitteln, was zu tun ist, wenn die Dinge nicht ganz in Ordnung sind, wenn sie gehen, etwas tragen oder ein Objekt greifen.
Normalerweise sind diese Modelle ziemlich spröde und versagen kläglich, sobald bestimmte Parameter überschritten werden oder unerwartete Ereignisse eintreten. Wenn Sie ihnen „gesunden Menschenverstand“ beibringen, werden sie flexibler und haben ein allgemeines Gespür dafür, wie sie eine Situation retten können. Dies sind keine besonders hochrangigen Konzepte, sondern nur intelligentere Möglichkeiten, damit umzugehen. Wenn beispielsweise etwas außerhalb der erwarteten Parameter liegt, kann es andere Parameter anpassen, um dem entgegenzuwirken, auch wenn sie nicht speziell dafür ausgelegt sind.
Das bedeutet nicht, dass Roboter herumlaufen und alles improvisieren werden – sie werden nur nicht so leicht oder so hart scheitern, wie sie es derzeit tun. Die aktuelle Forschung zeigt, dass die Fortbewegung in unwegsamem Gelände besser ist, Lasten besser getragen werden und unbekannte Gegenstände besser gegriffen werden, wenn das Training des „gesunden Menschenverstandes“ eingeschlossen ist.
Das Forschungsteam an der UC Berkeley hingegen beschäftigt sich besonders mit einem Bereich: dem Klimawandel. Die kürzlich gestartete Berkeley AI Research Climate Initiative (BAIR), organisiert von den Informatik-Doktoranden Colorado Reed und Medhini Narasimhan und dem Informatik-Doktoranden Ritwik Gupta, sucht Partner unter Klimaexperten, Regierungsbehörden und der Industrie, um Ziele zu erreichen, die für beide von Bedeutung sind Klima und KI.
Eines der ersten Projekte, die die Initiative in Angriff nehmen will, wird eine KI-Technik verwenden, um Messungen aus Flugzeugbeobachtungen von Schnee und offen verfügbaren Wetter- und Satellitendatenquellen zu kombinieren. KI wird helfen, den Lebenszyklus von Schnee zu verfolgen, was derzeit ohne großen Aufwand nicht möglich ist, und es den Forschern ermöglichen, abzuschätzen und vorherzusagen, wie viel Wasser sich im Schnee in den Bergen der Sierra Nevada befindet – und die Auswirkungen auf den Abfluss der Region vorherzusagen.
Eine Pressemitteilung, in der die Bemühungen des BAIR detailliert beschrieben werden, stellt fest, dass der Zustand des Schnees Auswirkungen auf die öffentliche Gesundheit und die Wirtschaft hat. Etwa 1,2 Milliarden Menschen sind weltweit für den Wasserverbrauch oder andere Zwecke auf die Schneeschmelze angewiesen, und allein die Berge der Sierra versorgen mehr als die Hälfte der kalifornischen Bevölkerung mit Wasser.
Jede Technologie oder Forschung, die von der Klimainitiative durchgeführt wird, wird offen veröffentlicht und nicht exklusiv lizenziert, sagte Trevor Darrel, Mitbegründer von BAIR und Informatikprofessor in Berkeley.
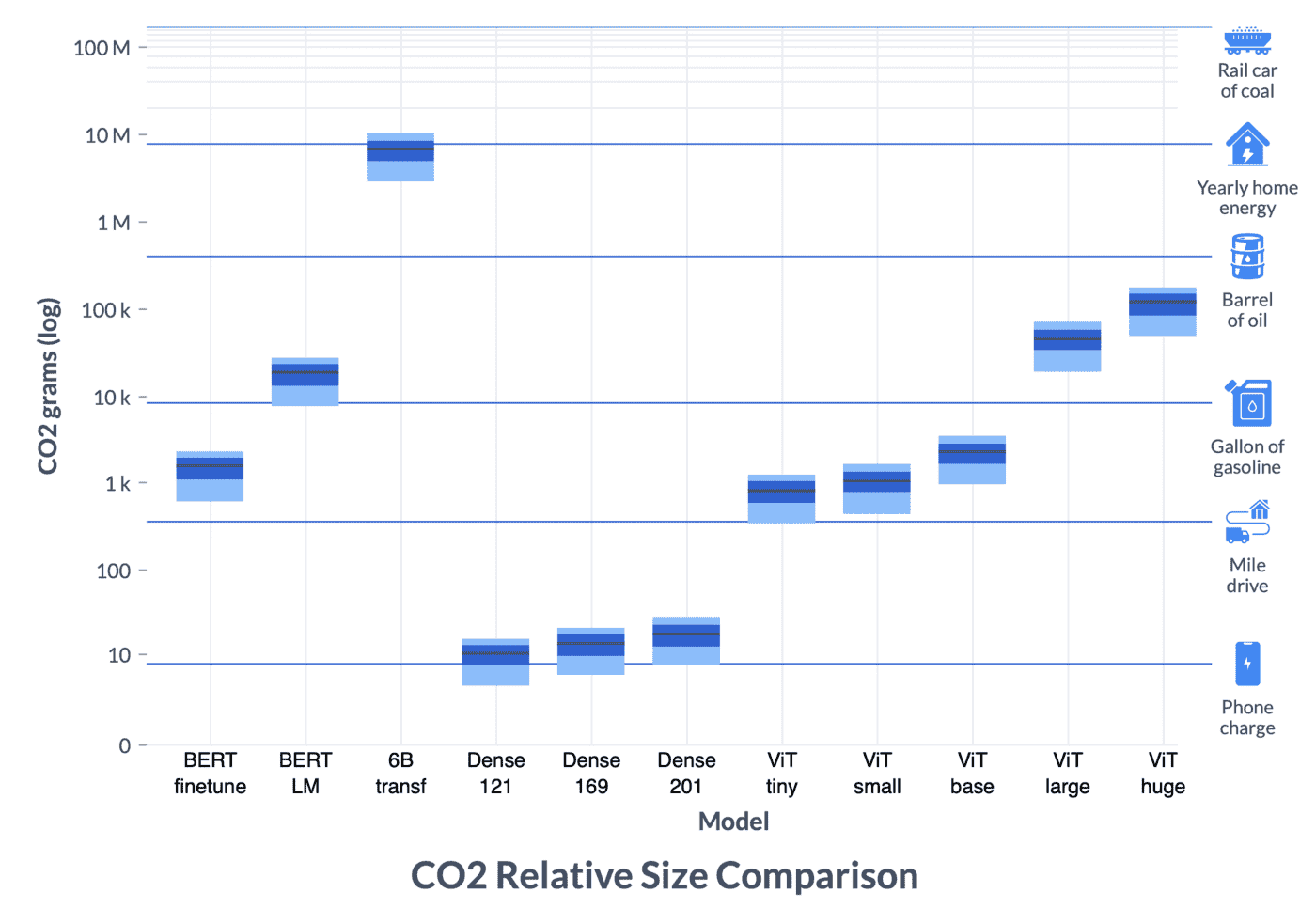
Ein Diagramm, das den CO2-Ausstoß verschiedener KI-Modelltrainingsprozesse zeigt.
Die KI selbst trägt jedoch auch zum Klimawandel bei, da enorme Rechenressourcen erforderlich sind, um Modelle wie GPT-3 und DALL-E zu trainieren. Das Allen Institute for AI (AI2) hat eine Studie durchgeführt wie diese Trainingszeiten intelligent gestaltet werden können, um ihre Auswirkungen auf das Klima zu reduzieren. Es ist keine triviale Rechnung: Woher der Strom kommt, ist ständig im Fluss und Spitzenverbrauch wie ein ganztägiger Supercomputing-Lauf kann nicht einfach aufgeteilt werden, um nächste Woche zu laufen, wenn die Sonne scheint und reichlich Solarstrom vorhanden ist.
Die Arbeit von AI2 befasst sich mit der CO2-Intensität des Trainings verschiedener Modelle an verschiedenen Orten und zu verschiedenen Zeiten, die Teil eines größeren Projekts der Green Software Foundation sind, um den Fußabdruck dieser wichtigen, aber energiefressenden Prozesse zu reduzieren.
Zu guter Letzt hat OpenAI diese Woche enthüllt Video PreTraining (VPT), eine Trainingstechnik, die eine kleine Menge gekennzeichneter Daten verwendet, um einem KI-System beizubringen, Aufgaben wie die Herstellung von Diamantwerkzeugen in Minecraft zu erledigen. VPT umfasst das Durchsuchen des Internets nach Videos und das Produzieren von Daten durch Auftragnehmer (z. B. 2.000 Stunden Videos, die mit Maus- und Tastaturaktionen gekennzeichnet sind) und das anschließende Trainieren eines Modells zur Vorhersage von Aktionen bei vergangenen und zukünftigen Videoframes. Im letzten Schritt werden die Originalvideos aus dem Web mit den Daten des Auftragnehmers gekennzeichnet, um ein System darauf zu trainieren, Aktionen nur anhand vergangener Frames vorherzusagen.
OpenAI verwendete Minecraft als Testfall für VPT, aber die Firma behauptet, dass der Ansatz ziemlich allgemein ist – was einen Schritt in Richtung „allgemeiner Computer verwendender Agenten“ darstellt. In jedem Fall ist das Modell in Open Source verfügbar, ebenso wie die Daten des Auftragnehmers, die OpenAI für seine Experimente beschafft hat.