
Es gibt eine neue KI-Modellfamilie, und sie ist eine der wenigen, die von Grund auf reproduziert werden kann.
Am Dienstag veröffentlichte Ai2, die vom verstorbenen Paul Allen gegründete gemeinnützige KI-Forschungsorganisation, OLMo 2, die zweite Modellfamilie seiner OLMo-Serie. (OLMo ist die Abkürzung für „Open Language Model“.) Während es keinen Mangel an „offenen“ Sprachmodellen zur Auswahl gibt (siehe: Metas Lama), erfüllt OLMo 2 die Definition der Open Source Initiative für Open-Source-KI, d. h. die verwendeten Tools und Daten zu entwickeln, sind öffentlich verfügbar.
Die Open Source Initiative, die langjährige Institution Mit dem Ziel, alles, was mit Open Source zu tun hat, zu definieren und zu „verwalten“, hat das Unternehmen im Oktober seine Open-Source-KI-Definition fertiggestellt. Aber auch die ersten OLMo-Modelle, die im Februar auf den Markt kamen, erfüllten das Kriterium.
„OLMo 2 [was] von Anfang bis Ende mit offenen und zugänglichen Trainingsdaten, Open-Source-Trainingscode, reproduzierbaren Trainingsrezepten, transparenten Auswertungen, Zwischenkontrollpunkten und mehr entwickelt“, schrieb AI2 in einem Blogbeitrag. „Durch die offene Weitergabe unserer Daten, Rezepte und Erkenntnisse hoffen wir, der Open-Source-Community die Ressourcen zur Verfügung zu stellen, die sie zur Entdeckung neuer und innovativer Ansätze benötigt.“
Es gibt zwei Modelle in der OLMo 2-Familie: eines mit 7 Milliarden Parametern (OLMo 7B) und eines mit 13 Milliarden Parametern (OLMo 13B). Parameter entsprechen in etwa den Problemlösungsfähigkeiten eines Modells, und Modelle mit mehr Parametern schneiden im Allgemeinen besser ab als solche mit weniger Parametern.
Wie die meisten Sprachmodelle können OLMo 2 7B und 13B eine Reihe textbasierter Aufgaben ausführen, wie das Beantworten von Fragen, das Zusammenfassen von Dokumenten und das Schreiben von Code.
Um die Modelle zu trainieren, verwendete Ai2 einen Datensatz von 5 Billionen Token. Token stellen Bits von Rohdaten dar; 1 Million Token entsprechen etwa 750.000 Wörtern. Das Schulungsset umfasste Websites, die „nach hoher Qualität gefiltert“ wurden, wissenschaftliche Arbeiten, Frage-und-Antwort-Diskussionsforen und Mathematik-Arbeitsbücher, die „sowohl synthetisch als auch von Menschen erstellt“ waren.
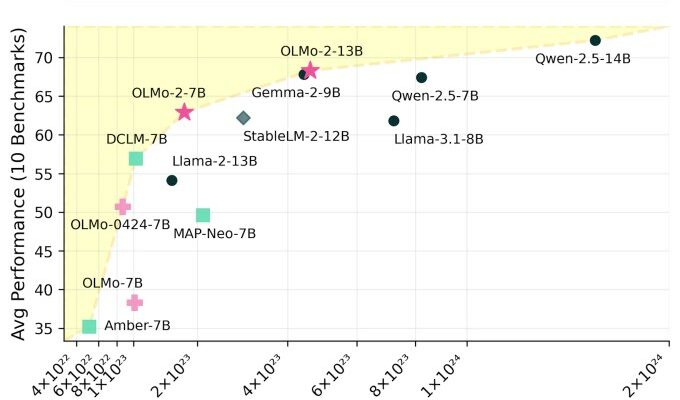
Ai2 behauptet, das Ergebnis seien leistungsmäßig konkurrenzfähige Modelle mit offenen Modellen wie Metas Llama 3.1-Version.
„Wir beobachten nicht nur eine dramatische Leistungsverbesserung bei allen Aufgaben im Vergleich zu unserem früheren OLMo-Modell, sondern insbesondere übertrifft OLMo 2 7B LLama 3.1 8B“, schreibt Ai2. „OLMo 2 [represents] die bisher besten vollständig offenen Sprachmodelle.“
Die OLMo 2-Modelle und alle ihre Komponenten können von Ai2 heruntergeladen werden Webseite. Sie stehen unter der Apache 2.0-Lizenz und können daher kommerziell genutzt werden.
In letzter Zeit gab es einige Debatten über die Sicherheit offener Modelle, wobei Llama-Modelle Berichten zufolge von chinesischen Forschern zur Entwicklung von Verteidigungsinstrumenten verwendet werden. Als ich den Ai2-Ingenieur Dirk Groeneveld im Februar fragte, ob er sich Sorgen über den Missbrauch von OLMo mache, sagte er mir, dass seiner Meinung nach die Vorteile letztendlich die Nachteile überwiegen.
„Ja, es ist möglich, dass offene Modelle unangemessen oder für unbeabsichtigte Zwecke verwendet werden“, sagte er. „[However, this] Der Ansatz fördert auch technische Fortschritte, die zu ethischeren Modellen führen. ist Voraussetzung für Verifikation und Reproduzierbarkeit, da diese nur mit Zugriff auf den gesamten Stack erreicht werden können; und verringert eine wachsende Machtkonzentration und schafft so einen gerechteren Zugang.“