
Sprachmodelle wie GPT-4 und Claude sind leistungsstark und nützlich, aber die Daten, auf denen sie trainiert werden, sind ein streng gehütetes Geheimnis. Das Allen Institute for AI (AI2) möchte diesen Trend mit einem neuen, riesigen Textdatensatz umkehren, der kostenlos verwendet und eingesehen werden kann.
Dolma, wie der Datensatz heißt, soll die Grundlage für das von der Forschungsgruppe geplante offene Sprachmodell OLMo bilden (Dolma ist die Abkürzung für „Data to füttern OLMo’s Appetite“). Da das Modell von der KI-Forschungsgemeinschaft frei verwendet und geändert werden soll, sollte dies (so argumentieren AI2-Forscher) auch der Datensatz sein, den sie zur Erstellung verwenden.
Dies ist das erste „Datenartefakt“, das AI2 im Zusammenhang mit OLMo zur Verfügung stellt in einem Blogbeitrag, erklärt Luca Soldaini von der Organisation die Wahl der Quellen und die Gründe für verschiedene Prozesse, die das Team verwendet hat, um es für die KI-Nutzung schmackhaft zu machen. („Ein umfassenderes Papier ist in Arbeit“, stellen sie zu Beginn fest.)
Obwohl Unternehmen wie OpenAI und Meta einige der wichtigen Statistiken der Datensätze veröffentlichen, die sie zum Aufbau ihrer Sprachmodelle verwenden, werden viele dieser Informationen als proprietär behandelt. Abgesehen von der bekannten Konsequenz, dass eine Prüfung und Verbesserung insgesamt entmutigend ist, gibt es Spekulationen darüber, dass dieser geschlossene Ansatz möglicherweise darauf zurückzuführen ist, dass die Daten weder ethisch noch rechtlich beschafft wurden: Beispielsweise werden Raubkopien der Bücher vieler Autoren eingeholt.
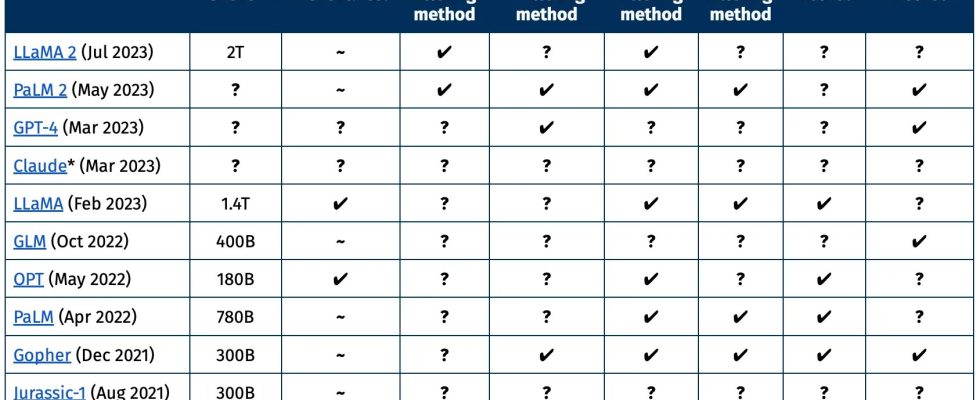
In diesem von AI2 erstellten Diagramm können Sie sehen, dass die größten und neuesten Modelle nur einige der Informationen liefern, die ein Forscher wahrscheinlich über einen bestimmten Datensatz wissen möchte. Welche Informationen wurden entfernt und warum? Was wurde als qualitativ hochwertiger bzw. minderwertiger Text angesehen? Wurden personenbezogene Daten ordnungsgemäß entfernt?
Diagramm, das die Offenheit oder das Fehlen verschiedener Datensätze zeigt.
Natürlich ist es das Vorrecht dieser Unternehmen, im Kontext einer hart umkämpften KI-Landschaft die Geheimnisse der Trainingsprozesse ihrer Modelle zu bewahren. Für Forscher außerhalb der Unternehmen werden diese Datensätze und Modelle jedoch undurchsichtiger und schwieriger zu untersuchen oder zu replizieren.
AI2s Dolma soll das Gegenteil davon sein, wobei alle seine Quellen und Prozesse – etwa wie und warum es auf englischsprachige Originaltexte zugeschnitten wurde – öffentlich dokumentiert sind.
Es ist nicht das erste Unternehmen, das die Sache mit offenen Datensätzen ausprobiert, aber es ist bei weitem das größte (3 Milliarden Token, ein KI-natives Maß für das Inhaltsvolumen) und, wie sie behaupten, das einfachste in Bezug auf Nutzung und Berechtigungen. Es verwendet die „ImpACT-Lizenz für Artefakte mit mittlerem Risiko“. Einzelheiten dazu finden Sie hier. Aber im Wesentlichen erfordert es von potenziellen Benutzern von Dolma Folgendes:
- Geben Sie Kontaktinformationen und beabsichtigte Anwendungsfälle an
- Geben Sie alle von Dolma abgeleiteten Kreationen offen
- Vertreiben Sie diese Derivate unter derselben Lizenz
- Stimmen Sie zu, Dolma nicht in verschiedenen verbotenen Bereichen wie Überwachung oder Desinformation anzuwenden
Für diejenigen, die befürchten, dass trotz aller Bemühungen von AI2 persönliche Daten von ihnen in die Datenbank gelangt sein könnten, gibt es hier ein Antragsformular für die Entfernung. Es handelt sich um spezifische Fälle und nicht nur um eine allgemeine „Benutze mich nicht“-Sache.
Wenn das alles gut für Sie klingt, Der Zugang zu Dolma ist über Hugging Face möglich.