
Die Forschung auf dem Gebiet des maschinellen Lernens und der KI, mittlerweile eine Schlüsseltechnologie in praktisch jeder Branche und jedem Unternehmen, ist viel zu umfangreich, als dass jemand sie vollständig lesen könnte. Diese Kolumne, Perceptron, zielt darauf ab, einige der relevantesten jüngsten Entdeckungen und Artikel zu sammeln – insbesondere in, aber nicht beschränkt auf, künstliche Intelligenz – und zu erklären, warum sie wichtig sind.
In diesem Stapel neuerer Forschungen hat Meta ein Sprachsystem als Open Source bereitgestellt, von dem es behauptet, dass es das erste ist, das in der Lage ist, 200 verschiedene Sprachen mit „state-of-the-art“-Ergebnissen zu übersetzen. Um nicht übertroffen zu werden, hat Google ein maschinelles Lernmodell detailliert beschrieben, Minerva, die Probleme des quantitativen Denkens einschließlich mathematischer und naturwissenschaftlicher Fragen lösen können. Und Microsoft hat ein Sprachmodell veröffentlicht, Gödel, um „realistische“ Konversationen zu generieren, die dem weit verbreiteten Lamda von Google entsprechen. Und dann haben wir einige neue Text-zu-Bild-Generatoren mit einem Twist.
Das neue Modell von Meta, NLLB-200, ist Teil der Initiative „No Language Left Behind“ des Unternehmens zur Entwicklung maschineller Übersetzungsfunktionen für die meisten Sprachen der Welt. NLLB-200 ist darauf trainiert, Sprachen wie Kamba (gesprochen von der ethnischen Gruppe der Bantu) und Lao (die offizielle Sprache von Laos) sowie über 540 afrikanische Sprachen zu verstehen, die von früheren Übersetzungssystemen nicht gut oder überhaupt nicht unterstützt werden übersetze Sprachen im Facebook-Newsfeed und auf Instagram zusätzlich zum Inhaltsübersetzungstool der Wikimedia Foundation, wie Meta kürzlich bekannt gab.
Die KI-Übersetzung hat das Potenzial, stark zu skalieren – und das bereits hat skaliert – die Anzahl der Sprachen, die ohne menschliches Fachwissen übersetzt werden können. Aber wie einige Forscher angemerkt haben, können in KI-generierten Übersetzungen Fehler auftreten, die falsche Terminologie, Auslassungen und Fehlübersetzungen umfassen, da die Systeme weitgehend mit Daten aus dem Internet trainiert werden – die nicht alle von hoher Qualität sind. Beispielsweise ging Google Translate einst davon aus, dass Ärzte männlich und Krankenschwestern weiblich waren, während Bings Übersetzer Sätze wie „der Tisch ist weich“ als weibliches „die Tabelle“ ins Deutsche übersetzte.
Für NLLB-200 sagte Meta, es habe seine Datenbereinigungspipeline mit „wichtigen Filterschritten“ und Toxizitätsfilterlisten für den gesamten Satz von 200 Sprachen „komplett überarbeitet“. Es bleibt abzuwarten, wie gut es in der Praxis funktioniert, aber – wie die Meta-Forscher hinter NLLB-200 in einer wissenschaftlichen Arbeit anerkennen, in der sie ihre Methoden beschreiben – kein System ist völlig frei von Vorurteilen.
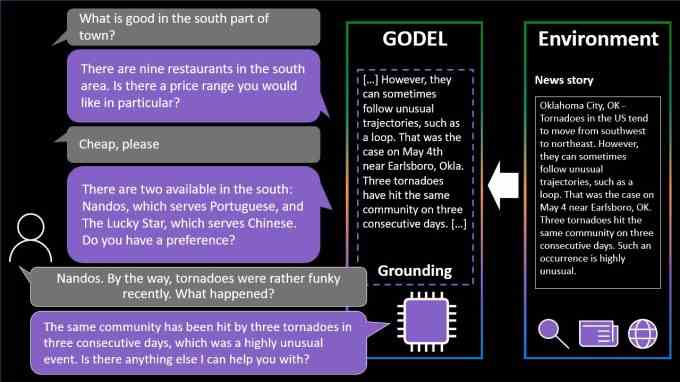
Godel ist in ähnlicher Weise ein Sprachmodell, das mit einer großen Menge an Text aus dem Internet trainiert wurde. Im Gegensatz zu NLLB-200 wurde Godel jedoch entwickelt, um „offene“ Dialoge zu führen – Gespräche über eine Reihe verschiedener Themen.
Bildnachweis: Microsoft
Gödel kann eine Frage zu einem Restaurant beantworten oder einen hin- und hergehenden Dialog über ein bestimmtes Thema führen, z. B. die Geschichte eines Viertels oder ein aktuelles Sportspiel. Nützlicherweise und wie Lamda von Google kann das System auf Inhalte aus dem gesamten Internet zurückgreifen, die nicht Teil des Trainingsdatensatzes waren, einschließlich Restaurantbewertungen, Wikipedia-Artikeln und anderen Inhalten auf öffentlichen Websites.
Aber Gödel stößt auf die gleichen Fallstricke wie NLLB-200. In einem Artikel stellt das für die Erstellung verantwortliche Team fest, dass es aufgrund der „Formen sozialer Voreingenommenheit und anderer Toxizität“ in den Daten, die zum Trainieren verwendet wurden, „schädliche Reaktionen hervorrufen kann“. Diese Vorurteile zu beseitigen oder gar abzumildern, bleibt eine ungelöste Herausforderung im Bereich der KI – eine Herausforderung, die möglicherweise nie vollständig gelöst wird.
Googles Minerva-Modell ist potenziell weniger problematisch. Wie das Team dahinter in einem Blogbeitrag beschreibt, lernte das System aus einem Datensatz von 118 GB wissenschaftlichen Arbeiten und Webseiten mit mathematischen Ausdrücken, um Probleme des quantitativen Denkens zu lösen, ohne externe Tools wie einen Taschenrechner zu verwenden. Minerva kann Lösungen generieren, die numerische Berechnungen und „symbolische Manipulation“ umfassen, und erzielt damit eine führende Leistung bei beliebten STEM-Benchmarks.
Minerva ist nicht das erste Modell, das entwickelt wurde, um diese Art von Problemen zu lösen. Um nur einige zu nennen: DeepMind von Alphabet demonstrierte mehrere Algorithmen, die Mathematikern bei komplexen und abstrakten Aufgaben helfen können, und OpenAI hat dies getan experimentiert mit einem System, das darauf trainiert ist, mathematische Probleme auf Grundschulniveau zu lösen. Aber Minerva integriert neuere Techniken, um mathematische Fragen besser zu lösen, sagt das Team, einschließlich eines Ansatzes, bei dem das Modell mit mehreren Schritt-für-Schritt-Lösungen für bestehende Fragen „aufgefordert“ wird, bevor es mit einer neuen Frage konfrontiert wird.

Bildnachweis: Google
Minerva macht immer noch seinen gerechten Anteil an Fehlern und kommt manchmal zu einer richtigen endgültigen Antwort, aber mit fehlerhafter Begründung. Dennoch hofft das Team, dass es als Grundlage für Modelle dienen wird, die „helfen, die Grenzen von Wissenschaft und Bildung zu verschieben“.
Die Frage, was KI-Systeme tatsächlich „wissen“, ist eher philosophisch als technisch, aber wie sie dieses Wissen organisieren, ist eine faire und relevante Frage. Beispielsweise kann ein Objekterkennungssystem zeigen, dass es „versteht“, dass Hauskatzen und Tiger in gewisser Weise ähnlich sind, indem es die Konzepte bei der Identifizierung absichtlich überlappen lässt – oder vielleicht versteht es es nicht wirklich und die beiden Arten von Kreaturen sind völlig unabhängig davon.
Forscher an der UCLA wollten sehen, ob Sprachmodelle Wörter in diesem Sinne „verstehen“, und eine Methode namens „semantische Projektion“ entwickelt, die darauf hindeutet, dass sie dies tun. Sie können das Modell zwar nicht einfach bitten, zu erklären, wie und warum sich ein Wal von einem Fisch unterscheidet, aber Sie können sehen, wie eng es diese Wörter mit anderen Wörtern verbindet, wie Säugetier, groß, Waage, usw. Wenn Wale stark mit Säugetieren und großen, aber nicht mit Schuppen in Verbindung gebracht werden, wissen Sie, dass er eine gute Vorstellung davon hat, wovon er spricht.
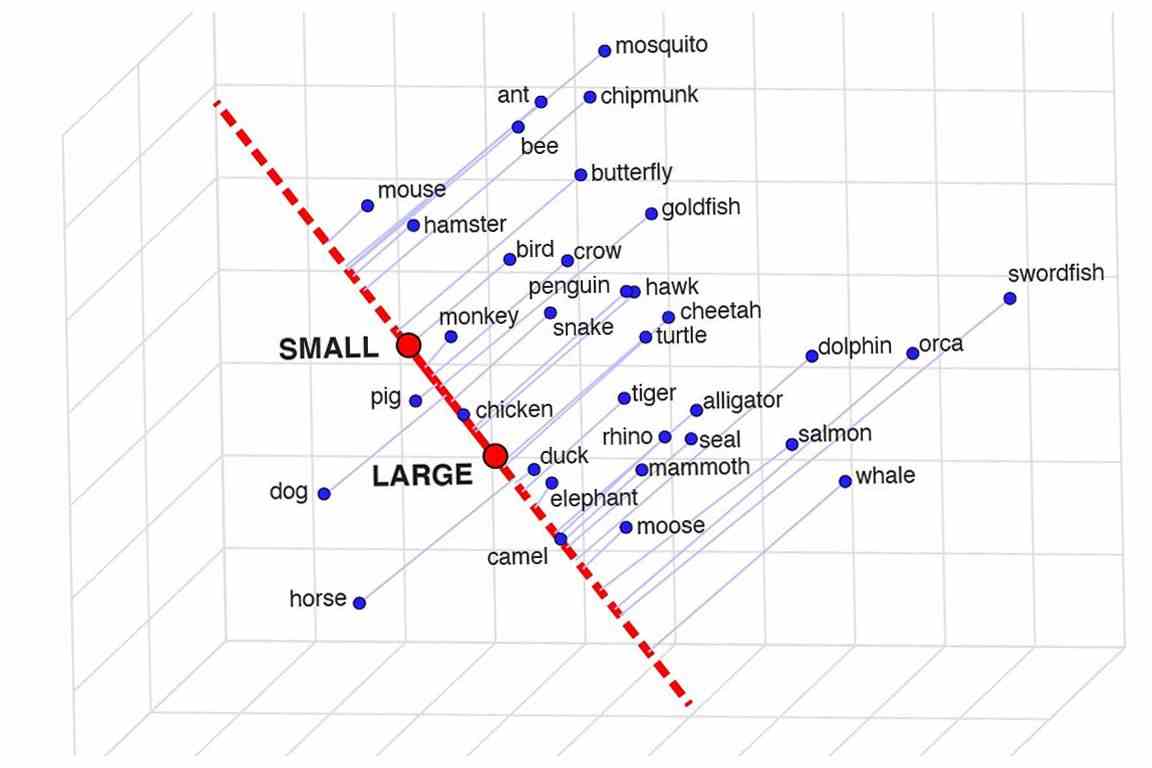
Ein Beispiel dafür, wo Tiere in das vom Modell konzipierte kleine bis große Spektrum fallen.
Als einfaches Beispiel fanden sie heraus, dass Tier mit den Konzepten Größe, Geschlecht, Gefahr und Nässe übereinstimmte (die Auswahl war etwas seltsam), während Staaten mit Wetter, Reichtum und Parteilichkeit zusammenfielen. Tiere sind überparteilich und Staaten sind geschlechtslos, damit alle Spuren.
Derzeit gibt es keinen sichereren Test dafür, ob ein Modell einige Wörter versteht, als es zu bitten, sie zu zeichnen – und Text-zu-Bild-Modelle werden immer besser. Googles „Pathways Autoregressive Text-to-Image“- oder Parti-Modell scheint eines der besten bisher zu sein, aber es ist schwierig, es mit der Konkurrenz (DALL-E et al.) ohne Zugang zu vergleichen, was nur wenige der Modelle bieten . Über den Parti-Ansatz können Sie sich jedenfalls hier informieren.
Ein interessanter Aspekt des Google-Berichts zeigt, wie das Modell mit einer zunehmenden Anzahl von Parametern funktioniert. Sehen Sie, wie sich das Bild allmählich verbessert, wenn die Zahlen zunehmen:

Die Aufforderung lautete: „Ein Porträtfoto eines Kängurus mit einem orangefarbenen Hoodie und einer blauen Sonnenbrille, das auf dem Rasen vor dem Sydney Opera House steht und ein Schild auf der Brust hält, auf dem Welcome Friends steht!“
Bedeutet dies, dass die besten Modelle alle zig Milliarden Parameter haben werden, was bedeutet, dass es ewig dauern wird, sie zu trainieren und nur auf Supercomputern zu betreiben? Im Moment sicher – es ist eine Art Brute-Force-Ansatz, um Dinge zu verbessern, aber das „Tick-Tack“ der KI bedeutet, dass der nächste Schritt nicht nur darin besteht, sie größer und besser zu machen, sondern sie kleiner und gleichwertiger zu machen. Mal sehen, wer das schafft.
Nicht einer, der aus dem Spaß ausgeschlossen werden sollte, zeigte Meta diese Woche auch ein generatives KI-Modell, obwohl eines, von dem es behauptet, dass es den Künstlern, die es verwenden, mehr Einfluss gibt. Nachdem ich selbst viel mit diesen Generatoren gespielt habe, besteht ein Teil des Spaßes darin, zu sehen, was dabei herauskommt, aber sie kommen häufig auf unsinnige Layouts oder „verstehen“ die Eingabeaufforderung nicht. Metas Make-A-Scene zielt darauf ab, das zu beheben.
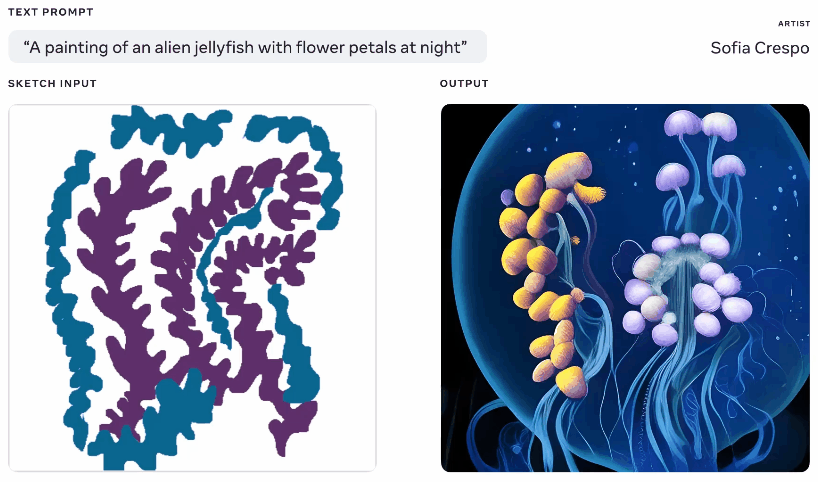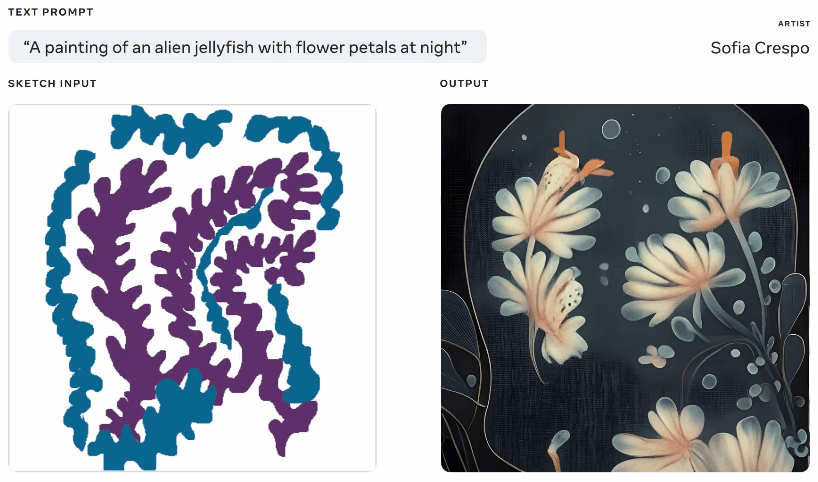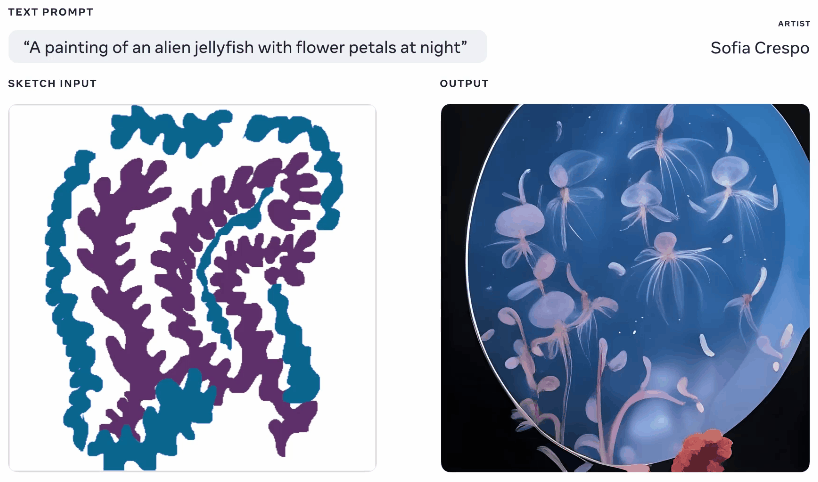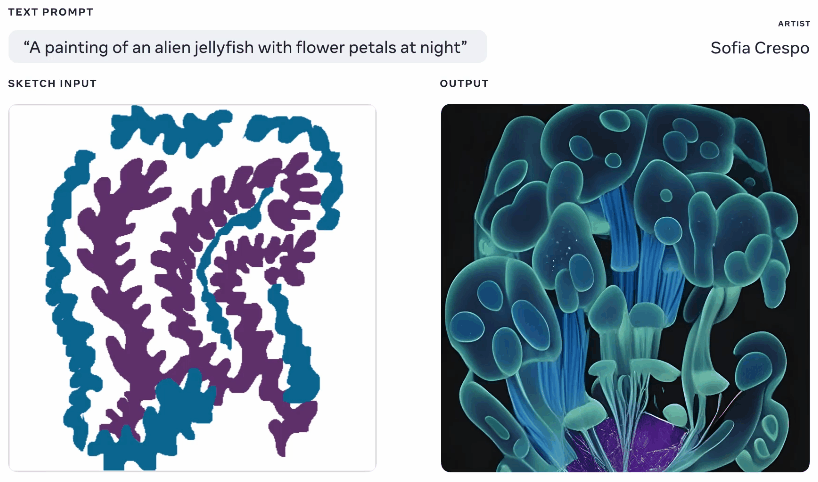
Animation verschiedener generierter Bilder aus demselben Text und Skizzen-Prompt.
Es ist nicht ganz eine originelle Idee – Sie malen eine grundlegende Silhouette dessen, worüber Sie sprechen, und es verwendet dies als Grundlage, um ein Bild darüber zu erzeugen. So etwas haben wir 2020 mit Googles Alptraumgenerator gesehen. Dies ist ein ähnliches Konzept, aber vergrößert, um es zu ermöglichen, realistische Bilder aus Texteingabeaufforderungen zu erstellen, wobei die Skizze als Grundlage verwendet wird, aber mit viel Raum für Interpretationen. Könnte für Künstler nützlich sein, die eine allgemeine Vorstellung davon haben, woran sie denken, aber die unbegrenzte und seltsame Kreativität des Modells einbeziehen möchten.
Wie die meisten dieser Systeme ist Make-A-Scene eigentlich nicht für die öffentliche Nutzung verfügbar, da es wie die anderen ziemlich rechenintensiv ist. Keine Sorge, wir werden bald anständige Versionen dieser Dinge zu Hause bekommen.