
Danke an die Cloud ist die Menge der generierten und gespeicherten Daten in Umfang und Umfang explodiert.
Jeder Aspekt des Unternehmens wird für Daten instrumentiert, sodass auf der Grundlage dieser Daten neue Operationen aufgebaut werden, die jedes Unternehmen dazu bringen, ein Datenunternehmen zu werden.
Eine der tiefgreifendsten und vielleicht nicht offensichtlichsten Veränderungen, die dies vorantreiben, ist das Aufkommen der Cloud-Datenbank. Dienste wie Amazon S3, Google BigQuery, Snowflake und Databricks haben die Berechnung großer Datenmengen gelöst und das Speichern von Daten aus jeder verfügbaren Quelle vereinfacht.
Das Unternehmen möchte alles speichern, was es kann, in der Hoffnung, verbesserte Kundenerlebnisse und neue Marktfähigkeiten liefern zu können.
Es ist eine gute Zeit, ein Datenbankunternehmen zu sein
Laut CB Insights haben Datenbankunternehmen in den letzten 10 Jahren über 8,7 Milliarden US-Dollar gesammelt, fast die Hälfte davon, 4,1 Milliarden US-Dollar, allein in den letzten 24 Monaten.
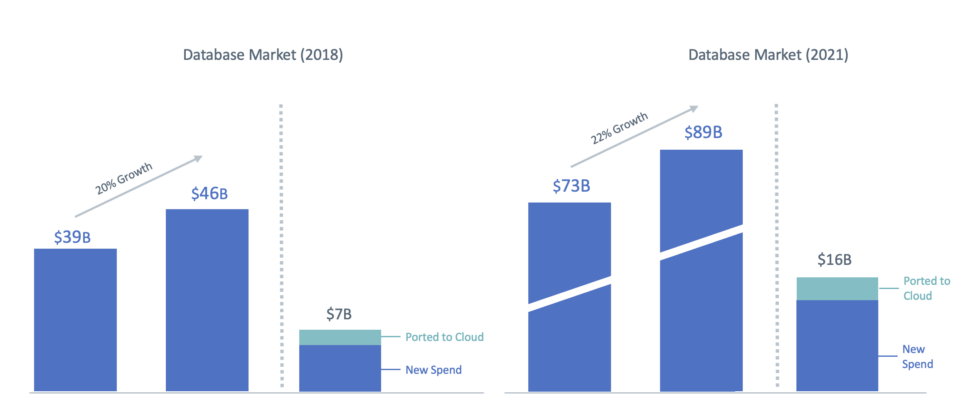
Angesichts der himmelhohen Bewertungen von Snowflake und Databricks ist das nicht verwunderlich. Der Markt hat sich in den letzten vier Jahren auf fast 90 Milliarden US-Dollar verdoppelt und wird sich voraussichtlich in den nächsten vier Jahren noch einmal verdoppeln. Man kann mit Sicherheit sagen, dass es eine große Chance gibt, danach zu streben.
Hier finden Sie eine solide Liste der Datenbankfinanzierungen im Jahr 2021.
Das Datenbankwachstum treibt die Ausgaben im Unternehmen voran. Bildnachweis: Venrock
Vor 20 Jahren gab es nur eine Option: Eine relationale Datenbank
Heute sind dank der Cloud, Microservices, verteilten Anwendungen, globaler Skalierung, Echtzeitdaten und Deep Learning neue Datenbankarchitekturen entstanden, um neue Leistungsanforderungen zu erfüllen.
Wir haben jetzt verschiedene Systeme für schnelles Lesen und schnelles Schreiben. Es gibt auch Systeme speziell für Ad-hoc-Analysen oder für Daten, die unstrukturiert, halbstrukturiert, transaktional, relational, grafisch oder zeitseriell sind, sowie für Daten, die für Cache, Suche, basierend auf Indizes, Ereignissen und mehr verwendet werden .
Es mag überraschen, aber es gibt immer noch Milliarden von Dollar in Oracle-Instanzen, die heute noch wichtige Anwendungen unterstützen, und sie werden wahrscheinlich nirgendwo hingehen.
Jedes System hat unterschiedliche Leistungsanforderungen, darunter Hochverfügbarkeit, horizontale Skalierung, verteilte Konsistenz, Failover-Schutz, Partitionstoleranz und serverlose und vollständige Verwaltung.
Infolgedessen speichern Unternehmen Daten im Durchschnitt in sieben oder mehr verschiedenen Datenbanken. Sie haben beispielsweise Snowflake als Data Warehouse, Clickhouse für Ad-hoc-Analysen, Timescale für Zeitreihendaten, Elastic für ihre Suchdaten, S3 für Protokolle, Postgres für Transaktionen, Redis für Caching oder Anwendungsdaten, Cassandra für Komplexe Workloads und Dgraph* für Beziehungsdaten oder dynamische Schemas.
Das alles setzt voraus, dass Sie in einer einzigen Cloud zusammengefasst sind und einen modernen Datenstapel von Grund auf neu aufgebaut haben.
Das Leistungsniveau und die Garantien dieser Dienste und Plattformen sind auf einem ganz anderen Niveau als vor fünf bis zehn Jahren. Gleichzeitig sorgen die Ausbreitung und Fragmentierung der Datenbankschicht zunehmend für neue Herausforderungen.
Beispielsweise die Synchronisierung über verschiedene Schemas und Systeme hinweg, das Schreiben neuer ETL-Jobs zur Überbrückung von Workloads über mehrere Datenbanken hinweg, ständiges Übersprechen und Konnektivitätsprobleme, der Aufwand für die Verwaltung von Aktiv-Aktiv-Clustering über so viele verschiedene Systeme hinweg oder Datenübertragungen, wenn neue Cluster oder Systeme gehen online. Jede davon hat unterschiedliche Skalierungs-, Verzweigungs-, Ausbreitungs-, Sharding- und Ressourcenanforderungen.
Darüber hinaus haben wir jetzt jeden Monat neue Datenbanken, die darauf abzielen, die nächste Herausforderung der Unternehmensgröße zu lösen.
Die New-Age-Datenbank
Die Frage ist also, wird die Zukunft der Datenbank weiterhin so definiert, wie sie heute ist?