
Am Samstag wurde Oleksandr Tomchuk, CEO von Triplegangers, darüber informiert, dass die E-Commerce-Website seines Unternehmens nicht verfügbar sei. Es schien sich um eine Art verteilten Denial-of-Service-Angriff zu handeln.
Bald stellte er fest, dass der Übeltäter ein Bot von OpenAI war, der unermüdlich versuchte, seine gesamte, riesige Website zu zerstören.
„Wir haben über 65.000 Produkte, jedes Produkt hat eine Seite“, sagte Tomchuk gegenüber Tech. „Jede Seite enthält mindestens drei Fotos.“
OpenAI schickte „Zehntausende“ Serveranfragen, um alles herunterzuladen, Hunderttausende Fotos, zusammen mit ihren detaillierten Beschreibungen.
„OpenAI hat 600 IPs verwendet, um Daten zu extrahieren, und wir analysieren immer noch die Protokolle der letzten Woche, vielleicht sind es noch viel mehr“, sagte er über die IP-Adressen, die der Bot verwendet hat, um zu versuchen, seine Website zu konsumieren.
„Ihre Crawler haben unsere Website zerstört“, sagte er. „Im Grunde war es ein DDoS-Angriff.“
Die Website von Triplegangers ist ihr Geschäft. Das Unternehmen mit sieben Mitarbeitern hat über ein Jahrzehnt damit verbracht, die seiner Meinung nach größte Datenbank „menschlicher digitaler Doppelgänger“ im Internet zusammenzustellen, d. h. 3D-Bilddateien, die von tatsächlichen menschlichen Modellen gescannt wurden.
Es verkauft die 3D-Objektdateien sowie Fotos – alles von Händen über Haare, Haut bis hin zu ganzen Körpern – an 3D-Künstler, Videospielentwickler und jeden, der authentische menschliche Eigenschaften digital nachbilden muss.
Tomchuks Team hat seinen Sitz in der Ukraine, ist aber auch in den USA in Tampa, Florida, lizenziert Seite mit den Nutzungsbedingungen auf seiner Website, die Bots verbietet, seine Bilder ohne Erlaubnis aufzunehmen. Aber das allein hat nichts gebracht. Websites müssen eine ordnungsgemäß konfigurierte robot.txt-Datei mit Tags verwenden, die den Bot von OpenAI, GPTBot, ausdrücklich anweisen, die Website in Ruhe zu lassen. (OpenAI hat auch ein paar andere Bots, ChatGPT-User und OAI-SearchBot, die ihre eigenen Tags haben, laut seiner Informationsseite zu seinen Crawlern.)
Robot.txt, auch bekannt als Robots Exclusion Protocol, wurde erstellt, um Suchmaschinen-Websites mitzuteilen, was sie bei der Indizierung des Webs nicht crawlen sollen. OpenAI gibt auf seiner Informationsseite an, dass es solche Dateien berücksichtigt, wenn es mit einem eigenen Satz von Do-not-Crawl-Tags konfiguriert ist. Es warnt jedoch auch, dass es bis zu 24 Stunden dauern kann, bis seine Bots eine aktualisierte robot.txt-Datei erkennen.
Wie Tomchuk erfahren hat, verstehen OpenAI und andere, wenn eine Website robot.txt nicht ordnungsgemäß verwendet, dies so, dass sie nach Herzenslust weitermachen können. Es handelt sich nicht um ein Opt-in-System.
Um das Ganze noch schlimmer zu machen, wurde Triplegangers nicht nur während der Geschäftszeiten in den USA vom OpenAI-Bot offline geschaltet, sondern Tomchuk rechnet auch mit einer überhöhten AWS-Rechnung dank der ganzen CPU- und Download-Aktivitäten des Bots.
Robot.txt ist auch nicht ausfallsicher. KI-Unternehmen halten sich freiwillig daran. Ein weiteres KI-Startup, Perplexity, wurde im vergangenen Sommer bekanntlich durch eine Wired-Untersuchung kritisiert, als einige Beweise darauf hindeuteten, dass Perplexity dem nicht nachkam.
Ich kann nicht genau wissen, was genommen wurde
Am Mittwoch, nachdem der OpenAI-Bot tagelang zurückgekehrt war, hatte Triplegangers eine ordnungsgemäß konfigurierte robot.txt-Datei sowie ein Cloudflare-Konto eingerichtet, um den GPTBot und mehrere andere von ihm entdeckte Bots zu blockieren, wie Barkrowler (ein SEO-Crawler) und Bytespider ( TokToks Crawler). Tomchuk hofft auch, dass er Crawler anderer KI-Modellunternehmen blockiert. Am Donnerstagmorgen sei die Seite nicht abgestürzt, sagte er.
Aber Tomchuk hat immer noch keine vernünftige Möglichkeit, genau herauszufinden, was OpenAI erfolgreich genommen hat, oder dieses Material entfernen zu lassen. Er hat keine Möglichkeit gefunden, OpenAI zu kontaktieren und nachzufragen. OpenAI antwortete nicht auf die Bitte von Tech um einen Kommentar. Und OpenAI hat es bisher nicht geschafft, sein seit langem versprochenes Opt-out-Tool bereitzustellen, wie Tech kürzlich berichtete.
Dies ist ein besonders heikles Thema für Tripleganger. „Wir sind in einem Geschäft tätig, in dem die Rechte ein ernstes Problem darstellen, weil wir echte Menschen scannen“, sagte er. Mit Gesetzen wie der europäischen DSGVO „können sie nicht einfach ein Foto von irgendjemandem im Internet machen und es verwenden.“
Auch für KI-Crawler war die Website von Triplegangers ein besonders leckerer Fund. Es wurden milliardenschwere Start-ups wie Scale AI gegründet, bei denen Menschen Bilder mühsam markieren, um KI zu trainieren. Die Website von Triplegangers enthält Fotos mit detaillierten Tags: ethnische Zugehörigkeit, Alter, Tätowierungen vs. Narben, alle Körpertypen und so weiter.
Die Ironie besteht darin, dass es die Gier des OpenAI-Bots war, die Triplegangers darauf aufmerksam machte, wie exponiert er war. Hätte es sanfter gekratzt, hätte Tomchuk es nie erfahren, sagte er.
„Es ist beängstigend, denn es scheint eine Lücke zu geben, die diese Unternehmen zum Crawlen von Daten nutzen, indem sie sagen: „Sie können sich abmelden, wenn Sie Ihre robot.txt-Datei mit unseren Tags aktualisieren“, sagt Tomchuk, aber das legt dem Geschäftsinhaber die Pflicht auf, dies zu tun verstehen, wie man sie blockiert.
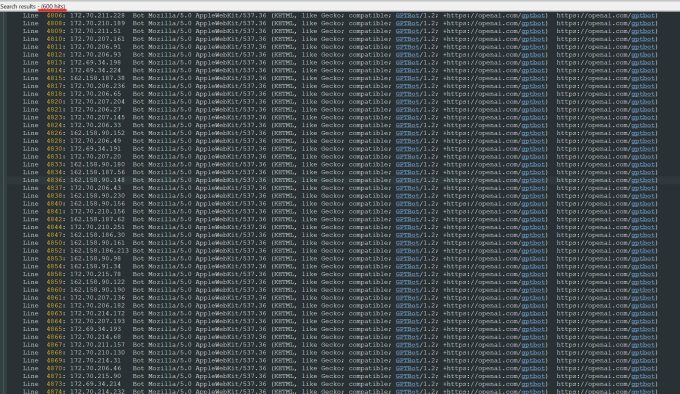
Er möchte, dass andere kleine Online-Unternehmen wissen, dass die einzige Möglichkeit, herauszufinden, ob ein KI-Bot urheberrechtlich geschütztes Eigentum einer Website stiehlt, darin besteht, aktiv danach zu suchen. Er ist sicherlich nicht der Einzige, der von ihnen terrorisiert wird. Besitzer anderer Websites haben es kürzlich erzählt Geschäftsinsider wie OpenAI-Bots ihre Websites zum Absturz brachten und ihre AWS-Rechnungen in die Höhe trieben.
Das Problem nahm im Jahr 2024 immer größere Ausmaße an. Neue Studie des digitalen Werbeunternehmens DoubleVerify habe herausgefunden, dass KI-Crawler und Scraper verursachten im Jahr 2024 einen Anstieg des „allgemein ungültigen Datenverkehrs“ um 86 % – also Datenverkehr, der nicht von einem echten Benutzer stammt.
Dennoch „haben die meisten Websites keine Ahnung, dass sie von diesen Bots gehackt wurden“, warnt Tomchuk. „Jetzt müssen wir die Protokollaktivität täglich überwachen, um diese Bots zu erkennen.“
Wenn man darüber nachdenkt, funktioniert das ganze Modell ein bisschen wie eine Mafiabwehr: Die KI-Bots nehmen sich, was sie wollen, es sei denn, man hat Schutz.
„Sie sollten um Erlaubnis bitten und nicht nur Daten abkratzen“, sagt Tomchuk.