
Ein bekannter Test für künstliche allgemeine Intelligenz (AGI) steht kurz vor seiner Lösung. Die Ersteller der Tests sagen jedoch, dass dies eher auf Mängel im Design des Tests als auf einen echten Forschungsdurchbruch hindeutet.
Im Jahr 2019 stellte Francois Chollet, eine führende Persönlichkeit in der KI-Welt, den ARC-AGI-Benchmark vor, kurz für „Abstract and Reasoning Corpus for Artificial General Intelligence“. Entwickelt, um zu bewerten, ob ein KI-System effizient neue Fähigkeiten außerhalb der Daten erwerben kann, auf denen es trainiert wurde. ARC-AGIFrancois behauptet, dass es nach wie vor der einzige KI-Test ist, der Fortschritte in Richtung allgemeiner Intelligenz misst (obwohl andere wurden vorgeschlagen.)
Bis zu diesem Jahr konnte die leistungsstärkste KI nur knapp ein Drittel der Aufgaben in ARC-AGI lösen. Chollet machte dafür den Fokus der Branche auf große Sprachmodelle (LLMs) verantwortlich, die seiner Meinung nach nicht in der Lage seien, wirkliche „Schlussfolgerungen“ zu ziehen.
„LLMs haben Schwierigkeiten mit der Verallgemeinerung, da sie vollständig auf das Auswendiglernen angewiesen sind“, sagt er sagte in einer Reihe von Beiträgen auf X im Februar. „Sie scheitern an allem, was nicht in ihren Trainingsdaten enthalten war.“
Für Chollet sind LLMs statistische Maschinen. Anhand vieler Beispiele lernen sie Muster in diesen Beispielen, um Vorhersagen zu treffen, wie zum Beispiel das „an wen“ in einer E-Mail normalerweise vor „es könnte etwas bedeuten“ steht.
Chollet behauptet, dass LLMs zwar in der Lage seien, sich „Denkmuster“ zu merken, es aber unwahrscheinlich sei, dass sie „neue Argumente“ auf der Grundlage neuartiger Situationen generieren könnten. „Wenn Sie viele Beispiele eines Musters lernen müssen, auch wenn es implizit ist, um eine wiederverwendbare Darstellung dafür zu lernen, müssen Sie es sich merken“, sagt Chollet argumentierte in einem anderen Beitrag.
Um Anreize für die Forschung über LLMs hinaus zu schaffen, startete Mike Knoop, Mitbegründer von Chollet und Zapier, im Juni ein 1-Millionen-Dollar-Programm Wettbewerb um eine Open-Source-KI zu entwickeln, die ARC-AGI schlagen kann. Von 17.789 Einsendungen erzielte der Beste eine Punktzahl von 55,5 % – etwa 20 % mehr als der Top-Scorer von 2023, wenn auch unter der für den Sieg erforderlichen 85 %-Grenze auf „menschlichem Niveau“.
Das bedeutet jedoch nicht, dass wir etwa 20 % näher an AGI sind, sagt Knoop.
Heute geben wir die Gewinner des ARC-Preises 2024 bekannt. Außerdem veröffentlichen wir einen ausführlichen technischen Bericht darüber, was wir aus dem Wettbewerb gelernt haben (Link im nächsten Tweet).
Der Stand der Technik stieg von 33 % auf 55,5 %, der größte einjährige Anstieg, den wir seit 2020 gesehen haben. Die…
— François Chollet (@fchollet) 6. Dezember 2024
In einem Blogbeitragsagte Knoop, dass viele der Einreichungen bei ARC-AGI mit „brutaler Gewalt“ zu einer Lösung gelangen konnten, was darauf hindeutet, dass ein „großer Teil“ der ARC-AGI-Aufgaben „[don’t] tragen viele nützliche Signale für die allgemeine Intelligenz.“
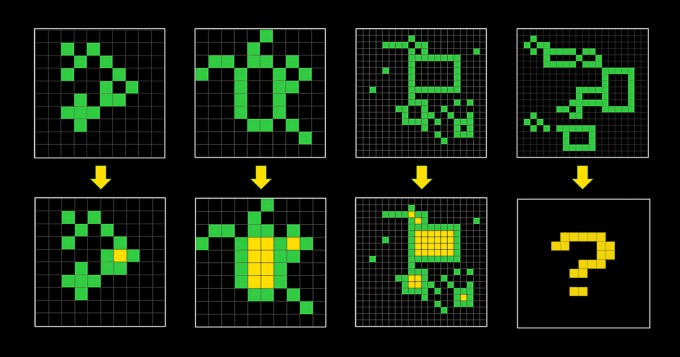
ARC-AGI besteht aus rätselartigen Problemen, bei denen eine KI anhand eines Rasters aus verschiedenfarbigen Quadraten das richtige „Antwort“-Raster generieren muss. Die Probleme sollten eine KI dazu zwingen, sich an neue Probleme anzupassen, die sie zuvor noch nicht gesehen hat. Aber es ist nicht klar, ob ihnen das gelingt.
„[ARC-AGI] ist seit 2019 unverändert und nicht perfekt“, räumte Knoop in seinem Beitrag ein.
Francois und Knoop standen sich ebenfalls gegenüber Kritik für den Überverkauf von ARC-AGI als Benchmark für AGI – zu einer Zeit, in der die Definition von AGI heftig umstritten ist. Ein OpenAI-Mitarbeiter kürzlich behauptet dass AGI „bereits“ erreicht wurde, wenn man AGI als KI definiert, die „bei den meisten Aufgaben besser ist als die meisten Menschen“.
Knoop und Chollet sagen, dass sie neben einem Wettbewerb im Jahr 2025 die Veröffentlichung eines ARC-AGI-Benchmarks der zweiten Generation planen, um diese Probleme anzugehen. „Wir werden die Bemühungen der Forschungsgemeinschaft weiterhin auf die aus unserer Sicht wichtigsten ungelösten Probleme der KI richten und den Zeitplan für AGI beschleunigen“, schrieb Chollet in einem X Post.
Die Lösung wird wahrscheinlich nicht einfach sein. Wenn die Mängel des ersten ARC-AGI-Tests Anzeichen dafür sind, wird die Definition von Intelligenz für KI ebenso hartnäckig sein – und entzündlich – wie es auch für Menschen war.