
Die allgemeine Meinung ist, dass Unternehmen wie Google, OpenAI und Anthropic mit ihren bodenlosen Geldreserven und Hunderten von Spitzenforschern die einzigen sind, die ein hochmodernes Stiftungsmodell entwickeln können. Aber als einer von ihnen bekanntlich bemerktsie „haben keinen Burggraben“ – und AI2 hat dies heute mit der Veröffentlichung von Molmoein multimodales KI-Modell, das ihren Anforderungen am besten entspricht und gleichzeitig klein, kostenlos und wirklich Open Source ist.
Um es klar zu sagen: Molmo (multimodales offenes Sprachmodell) ist eine visuelle Verständnis-Engine, kein Full-Service-Chatbot wie ChatGPT. Es hat keine API, ist nicht bereit für die Unternehmensintegration und durchsucht das Internet nicht für Sie oder für seine eigenen Zwecke. Sie können es sich als den Teil dieser Modelle vorstellen, der ein Bild sieht, es versteht und Fragen dazu beschreiben oder beantworten kann.
Molmo (erhältlich in den Parametervarianten 72B, 7B und 1B) ist wie andere multimodale Modelle in der Lage, Fragen zu nahezu jeder Alltagssituation oder jedem Gegenstand zu erkennen und zu beantworten. Wie funktioniert diese Kaffeemaschine? Wie viele Hunde auf diesem Bild haben ihre Zungen rausgestreckt? Welche Optionen auf dieser Speisekarte sind vegan? Was sind die Variablen in diesem Diagramm? Es handelt sich um die Art von visueller Verständnisaufgabe, die wir seit Jahren mit unterschiedlichem Erfolg und unterschiedlicher Latenzzeit demonstriert sehen.
Der Unterschied besteht nicht unbedingt in den Fähigkeiten von Molmo (die Sie in der Demo unten sehen oder testen können). Hier), sondern wie diese Ziele erreicht werden.
Visuelles Verständnis ist natürlich ein weites Feld, das Dinge wie das Zählen von Schafen auf einem Feld, das Erraten des emotionalen Zustands einer Person oder das Zusammenfassen eines Menüs umfasst. Daher ist es schwer zu beschreiben, geschweige denn quantitativ zu testen, aber wie AI2-Präsident Ali Farhadi bei einer Demo-Veranstaltung im Hauptsitz der Forschungsorganisation in Seattle erklärte, kann man zumindest zeigen, dass zwei Modelle in ihren Fähigkeiten ähnlich sind.
„Eine Sache, die wir heute zeigen, ist, dass offen gleich geschlossen ist“, sagte er, „und klein jetzt gleich groß ist.“ (Er stellte klar, dass er == meinte, also Äquivalenz und nicht Identität; ein feiner Unterschied, den manche zu schätzen wissen.)
Eine Konstante in der KI-Entwicklung ist „größer ist besser“. Mehr Trainingsdaten, mehr Parameter im resultierenden Modell und mehr Rechenleistung, um sie zu erstellen und zu betreiben. Aber irgendwann kann man sie buchstäblich nicht mehr größer machen: Es sind nicht genug Daten dafür vorhanden oder die Rechenkosten und -zeiten werden so hoch, dass es kontraproduktiv wird. Man muss einfach mit dem auskommen, was man hat, oder noch besser: mit weniger mehr erreichen.
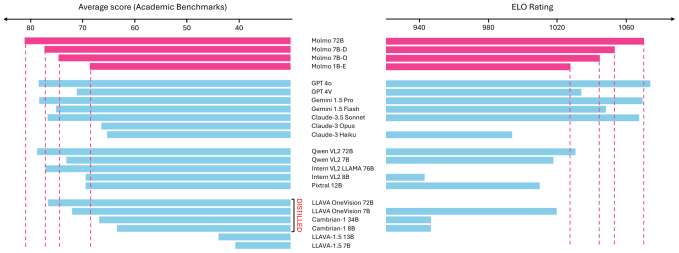
Farhadi erklärte, dass Molmo zwar auf Augenhöhe mit GPT-4o, Gemini 1.5 Pro und Claude-3.5 Sonnet arbeitet, aber (nach besten Schätzungen) nur etwa ein Zehntel deren Größe auf die Waage bringt. Und es nähert sich deren Leistungsfähigkeit mit einem Modell, das ein Zehntel der Das.
„Es gibt Dutzende verschiedener Benchmarks, anhand derer die Leute ihre Ergebnisse bewerten. Ich mag dieses Spiel nicht, wissenschaftlich betrachtet … aber ich musste den Leuten eine Zahl zeigen“, erklärte er. „Unser größtes Modell ist ein kleines Modell, 72B, es übertrifft GPTs und Claudes und Geminis bei diesen Benchmarks. Auch hier gilt: Nehmen Sie es mit Vorsicht: Bedeutet das, dass es wirklich besser ist als sie oder nicht? Ich weiß es nicht. Aber zumindest für uns bedeutet es, dass wir das gleiche Spiel spielen.“
Wenn Sie versuchen wollen, es zu vereiteln, Schauen Sie sich gerne die öffentliche Demo andas auch auf Mobilgeräten funktioniert. (Wenn Sie sich nicht anmelden möchten, können Sie aktualisieren oder nach oben scrollen und die ursprüngliche Eingabeaufforderung „bearbeiten“, um das Bild zu ersetzen.)
Das Geheimnis liegt darin, weniger, dafür aber qualitativ bessere Daten zu verwenden. Anstatt mit einer Bibliothek von Milliarden von Bildern zu trainieren, deren Qualität nicht alle kontrolliert, beschrieben oder dedupliziert werden können, hat AI2 einen Satz von nur 600.000 Bildern kuratiert und kommentiert. Natürlich ist das immer noch viel, aber verglichen mit sechs Milliarden ist das ein Tropfen auf den heißen Stein – ein Bruchteil eines Prozents. Zwar bleibt dadurch ein wenig Long-Tail-Material weg, aber ihr Auswahlprozess und ihre interessante Kommentierungsmethode ermöglichen ihnen Beschreibungen von sehr hoher Qualität.
Interessant, wie? Nun, sie zeigen Leuten ein Bild und sagen ihnen, sie sollen es beschreiben – laut. Es stellt sich heraus, dass Leute anders über Dinge reden, als sie darüber schreiben, und das führt nicht nur zu genauen, sondern auch zu gesprächigen und nützlichen Ergebnissen. Die daraus resultierenden Bildbeschreibungen, die Molmo erstellt, sind ausführlich und praktisch.
Das zeigt sich am besten an seiner neuen und seit einigen Tagen einzigartigen Fähigkeit, auf die relevanten Teile der Bilder zu „zeigen“. Als es aufgefordert wurde, die Hunde auf einem Foto zu zählen (33), setzte es auf jedes ihrer Gesichter einen Punkt. Als es aufgefordert wurde, die Zungen zu zählen, setzte es auf jede Zunge einen Punkt. Diese Spezifität ermöglicht ihm alle möglichen neuen Zero-Shot-Aktionen. Und was wichtig ist: Es funktioniert auch auf Weboberflächen: Ohne den Code der Website zu betrachten, versteht das Modell, wie man auf einer Seite navigiert, ein Formular absendet und so weiter. (Rabbit hat kürzlich etwas Ähnliches für sein r1 gezeigt, das nächste Woche veröffentlicht wird.)
Warum ist das alles wichtig? Praktisch jeden Tag kommen neue Modelle heraus. Google hat gerade welche angekündigt. OpenAI hat bald einen Demo-Tag. Perplexity macht ständig irgendwelche Andeutungen. Meta macht Hype um die Llama-Version von was auch immer.
Nun, Molmo ist völlig kostenlos und Open Source und außerdem klein genug, um lokal ausgeführt zu werden. Keine API, kein Abonnement, kein wassergekühlter GPU-Cluster erforderlich. Die Absicht hinter der Erstellung und Veröffentlichung des Modells besteht darin, Entwicklern und Entwicklern die Möglichkeit zu geben, KI-gestützte Apps, Dienste und Erlebnisse zu erstellen, ohne die Erlaubnis eines der größten Technologieunternehmen der Welt einholen (und bezahlen) zu müssen.
„Wir richten uns an Forscher, Entwickler, App-Entwickler, Leute, die nicht wissen, wie sie mit diesen [large] Modelle. Ein Schlüsselprinzip bei der Ansprache eines so breiten Publikums ist das Schlüsselprinzip, das wir schon seit einiger Zeit vorantreiben, nämlich: es zugänglicher zu machen“, sagte Farhadi. „Wir veröffentlichen alles, was wir getan haben. Dazu gehören Daten, Bereinigung, Anmerkungen, Schulung, Code, Kontrollpunkte, Auswertung. Wir veröffentlichen alles, was wir darüber entwickelt haben.“
Er fügte hinzu, er erwarte, dass die Leute sofort mit diesem Datensatz und Code anfangen würden – darunter auch finanzkräftige Konkurrenten, die alle „öffentlich verfügbaren“ Daten aufsaugen, also alles, was nicht niet- und nagelfest ist. („Ob sie es erwähnen oder nicht, ist eine ganz andere Geschichte“, fügte er hinzu.)
Die KI-Welt entwickelt sich schnell, doch die großen Player liefern sich zunehmend einen Wettlauf nach unten: Sie senken die Preise auf das absolute Minimum und treiben gleichzeitig Hunderte Millionen auf, um die Kosten zu decken. Wenn ähnliche Funktionen auch über kostenlose Open-Source-Optionen verfügbar sind, kann der Wert, den diese Unternehmen bieten, dann wirklich so astronomisch sein? Zumindest zeigt Molmo, dass der Kaiser, obwohl die Frage, ob er Kleider trägt, definitiv keinen Burggraben hat.