
ChatGPT Hersteller OpenAI hat angekündigt seine nächste große Produktveröffentlichung: Ein generatives KI-Modell mit dem Codenamen Strawberry, offiziell OpenAI o1 genannt.
Genauer gesagt handelt es sich bei o1 eigentlich um eine Familie von Modellen. Zwei davon sind am Donnerstag in ChatGPT und über die API von OpenAI verfügbar: o1-preview und o1-mini, ein kleineres, effizienteres Modell zur Codegenerierung.
Sie müssen ChatGPT Plus oder Team abonniert haben, um o1 im ChatGPT-Client zu sehen. Unternehmens- und Bildungsbenutzer erhalten Anfang nächster Woche Zugriff.
Beachten Sie, dass die Chatbot-Erfahrung von o1 derzeit ziemlich dürftig ist. Im Gegensatz zu GPT-4o, dem Vorgänger von o1, kann o1 noch nicht im Internet surfen oder Dateien analysieren. Das Modell verfügt zwar über Bildanalysefunktionen, diese wurden jedoch bis zum Abschluss weiterer Tests deaktiviert. Und o1 ist geschwindigkeitsbegrenzt; die wöchentlichen Limits liegen derzeit bei 30 Nachrichten für o1-preview und 50 für o1-mini.
Ein weiterer Nachteil ist, dass o1 teuer. Sehr teuer. In der API kostet o1-preview 15 USD pro 1 Million Eingabetoken und 60 USD pro 1 Million Ausgabetoken. Das sind das Dreifache der Kosten im Vergleich zu GPT-4o für die Eingabe und das Vierfache der Kosten für die Ausgabe. (Token sind Rohdaten; 1 Million entspricht etwa 750.000 Wörtern.)
OpenAI will allen kostenlosen ChatGPT-Nutzern Zugriff auf o1-mini gewähren, hat aber noch kein Veröffentlichungsdatum festgelegt. Wir werden das Unternehmen daran erinnern.
Argumentationskette
OpenAI o1 vermeidet einige der Denkfallen, die generative KI-Modelle normalerweise zum Stolpern bringen, da es sich selbst effektiv auf Fakten überprüfen kann, indem es mehr Zeit darauf verwendet, alle Teile einer Frage zu berücksichtigen. Laut OpenAI ist die Fähigkeit von o1, „nachzudenken“, bevor es auf Anfragen antwortet, was es „qualitativ“ anders macht als andere generative KI-Modelle.
Wenn o1 zusätzliche Zeit zum „Nachdenken“ erhält, kann es eine Aufgabe ganzheitlich durchdenken – es plant voraus und führt über einen längeren Zeitraum eine Reihe von Aktionen aus, die dem Modell helfen, zu einer Antwort zu gelangen. Dadurch eignet sich o1 gut für Aufgaben, bei denen die Ergebnisse mehrerer Teilaufgaben zusammengefasst werden müssen, wie das Erkennen vertraulicher E-Mails im Posteingang eines Anwalts oder das Brainstorming einer Produktmarketingstrategie.
In einer Reihe von Beiträge Noam Brown, ein Forscher bei OpenAI, sagte am Donnerstag auf X, dass „o1 mit Verstärkungslernen trainiert wird“. Dies lehre das System, „über eine private Gedankenkette nachzudenken, bevor es antwortet“, indem es Belohnungen erhält, wenn o1 die richtigen Antworten gibt, und Strafen, wenn es dies nicht tut, sagte er.
Brown fügte hinzu, dass OpenAI einen neuen Optimierungsalgorithmus und einen Trainingsdatensatz verwendet, der „Argumentationsdaten“ und wissenschaftliche Literatur enthält, die speziell auf Argumentationsaufgaben zugeschnitten sind. „Je länger [o1] denkt, desto besser ist das“, sagte er.
Tech hatte nicht die Möglichkeit, o1 vor seinem Debüt zu testen; wir werden es so bald wie möglich in die Hände bekommen. Aber laut einer Person, die tat Zugriff haben – Pablo Arredondo, VP bei Thomson Reuters – o1 ist besser als frühere Modelle von OpenAI (z. B. GPT-4o) bei Dingen wie der Analyse von Rechtsgutachten und der Identifizierung von Lösungen für Probleme in LSAT-Logikspielen.
„Wir haben gesehen, dass es sich mit umfangreicheren, vielschichtigeren Analysen befasst“, sagte Arredondo gegenüber Tech. „Unsere automatisierten Tests zeigten auch Verbesserungen bei einer Vielzahl einfacher Aufgaben.“
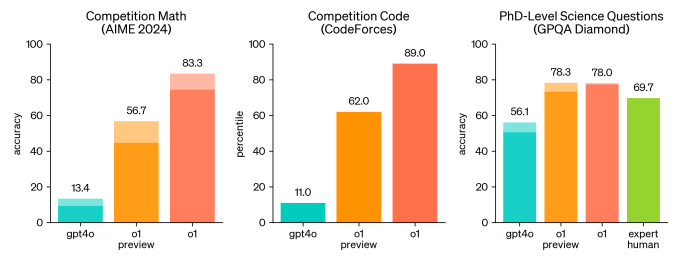
In einer Qualifikationsprüfung für die Internationale Mathematik-Olympiade (IMO), einem Mathematik-Wettbewerb für Highschools, löste o1 laut OpenAI 83 % der Aufgaben richtig, während GPT-4o nur 13 % löste. (Das ist weniger beeindruckend, wenn man bedenkt, dass Google DeepMinds jüngste KI erreicht eine Silbermedaille in einem Äquivalent zum eigentlichen IMO-Wettbewerb.) OpenAI sagt auch, dass o1 in den als Codeforces bekannten Online-Programmierwettbewerbsrunden das 89. Perzentil der Teilnehmer erreicht hat – was immer das bedeuten mag, besser ist als DeepMinds Flaggschiffsystem AlphaCode 2.
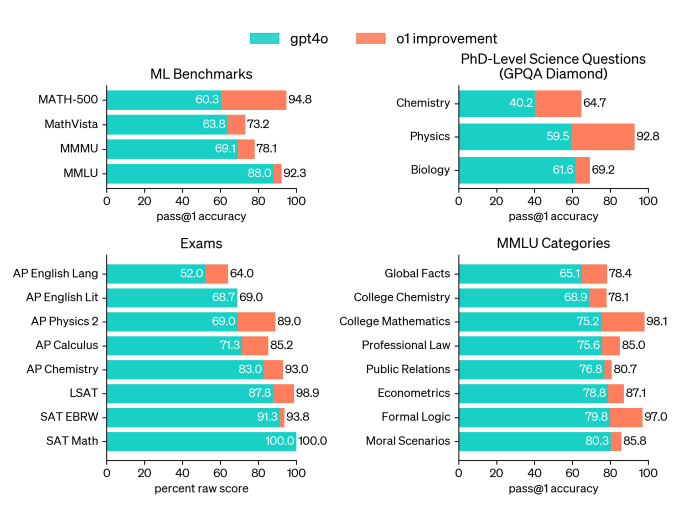
Im Allgemeinen sollte o1 bei Problemen in den Bereichen Datenanalyse, Wissenschaft und Codierung besser abschneiden, sagt OpenAI. (GitHub, das o1 mit seinem KI-Codierungsassistenten getestet hat GitHub Copilot, Berichte dass das Modell gut darin ist, Algorithmen und App-Code zu optimieren.) Und zumindest laut Benchmarking von OpenAI übertrifft o1 GPT-4o in seinen Mehrsprachigkeitsfähigkeiten, insbesondere bei Sprachen wie Arabisch und Koreanisch.
Ethan Mollick, Professor für Management an der Wharton University, schrieb seine Eindrücke von o1 nach einem Monat der Nutzung in einem Beitrag auf seinem persönlichen Blog. Bei einem anspruchsvollen Kreuzworträtsel schnitt o1 gut ab, sagte er – er hatte alle Antworten richtig (obwohl er einen neuen Hinweis halluzinierte).
OpenAI o1 ist nicht perfekt
Nun, da Sind Nachteile.
OpenAI o1 dürfen langsamer sein als andere Modelle, je nach Abfrage. Arredondo sagt, dass o1 über 10 Sekunden brauchen kann, um einige Fragen zu beantworten; es zeigt seinen Fortschritt an, indem es ein Etikett für die aktuell ausgeführte Unteraufgabe anzeigt.
Angesichts der unvorhersehbaren Natur generativer KI-Modelle weist o1 wahrscheinlich weitere Mängel und Einschränkungen auf. Brown gab zu, dass o1 beispielsweise bei Tic-Tac-Toe-Spielen von Zeit zu Zeit stolpert. Und in einem FachartikelOpenAI sagte, es habe von Testern anekdotisches Feedback erhalten, wonach O1 zu Halluzinationen neigt (d. h., sich selbstbewusst Dinge ausdenkt). mehr als GPT-4o – und gibt seltener zu, wenn es die Antwort auf eine Frage nicht hat.
„Fehler und Halluzinationen passieren immer noch [with o1]”, schreibt Mollick in seinem Beitrag. „Es ist immer noch nicht fehlerfrei.“
Wir werden zweifellos mit der Zeit mehr über die verschiedenen Probleme erfahren, wenn wir die Möglichkeit haben, o1 selbst auf Herz und Nieren zu prüfen.
Harter Wettbewerb
Wir wären nachlässig, wenn wir nicht darauf hinweisen würden, dass OpenAI bei weitem nicht der einzige KI-Anbieter ist, der diese Art von Argumentationsmethoden untersucht, um die Faktizität von Modellen zu verbessern.
Google DeepMind-Forscher veröffentlichten kürzlich eine Studie Dies zeigt, dass die Leistung von Modellen ohne zusätzliche Optimierungen erheblich verbessert werden kann, indem den Modellen im Wesentlichen mehr Rechenzeit und Anleitung zur Erfüllung eingehender Anfragen gegeben wird.
OpenAI veranschaulicht die Härte des Wettbewerbs sagte dass man sich teilweise aufgrund von „Wettbewerbsvorteilen“ dagegen entschieden hat, die Rohdaten der „Gedankenketten“ von o1 in ChatGPT anzuzeigen. (Stattdessen entschied sich das Unternehmen dafür, „modellgenerierte Zusammenfassungen“ der Ketten anzuzeigen.)
OpenAI ist mit o1 vielleicht als erstes am Start. Aber vorausgesetzt, dass die Konkurrenz bald mit ähnlichen Modellen nachzieht, wird die wahre Herausforderung für das Unternehmen darin bestehen, o1 allgemein verfügbar zu machen – und zwar zu einem günstigeren Preis.
Von dort aus werden wir sehen, wie schnell OpenAI verbesserte Versionen von o1 liefern kann. Das Unternehmen sagt, es wolle mit o1-Modellen experimentieren, die stunden-, tage- oder sogar wochenlang argumentieren, um ihre Denkfähigkeiten weiter zu verbessern.