
Wenn man den mythischen Ouroboros sieht, ist es vollkommen logisch, zu denken: „Das wird aber nicht so bleiben.“ Ein starkes Symbol – den eigenen Schwanz zu verschlucken –, aber in der Praxis schwierig. Das könnte auch bei der KI der Fall sein, bei der einer neuen Studie zufolge die Gefahr eines „Modellzusammenbruchs“ besteht, nachdem sie einige Runden lang mit selbst generierten Daten trainiert wurde.
In einem in Nature veröffentlichten Artikel zeigen britische und kanadische Forscher unter der Leitung von Ilia Shumailov in Oxford, dass die heutigen Modelle des maschinellen Lernens grundsätzlich anfällig für ein Syndrom, das sie „Modellkollaps“ nennen. In der Einleitung des Artikels schreiben sie:
Wir stellen fest, dass wahlloses Lernen aus Daten, die von anderen Modellen erstellt wurden, zum „Modellkollaps“ führt – einem degenerativen Prozess, bei dem Modelle mit der Zeit die wahre zugrunde liegende Datenverteilung vergessen …
Wie passiert das und warum? Der Vorgang ist eigentlich ganz einfach zu verstehen.
KI-Modelle sind im Grunde Mustererkennungssysteme: Sie lernen Muster aus ihren Trainingsdaten, gleichen diese Muster mit Eingabeaufforderungen ab und füllen die wahrscheinlichsten nächsten Punkte in der Zeile aus. Ob Sie nun fragen: „Was ist ein gutes Snickerdoodle-Rezept?“ oder „Listen Sie die US-Präsidenten in der Reihenfolge ihres Alters bei der Amtseinführung auf“, das Modell gibt im Grunde nur die wahrscheinlichste Fortsetzung dieser Wortfolge zurück. (Bei Bildgeneratoren ist das anders, aber in vielerlei Hinsicht ähnlich.)
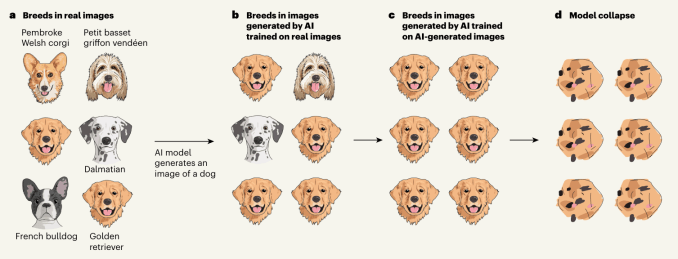
Aber die Sache ist die: Modelle tendieren zum gängigsten Ergebnis. Sie erhalten kein umstrittenes Snickerdoodle-Rezept, sondern das beliebteste und gewöhnlichste. Und wenn Sie einen Bildgenerator bitten, ein Bild von einem Hund zu erstellen, wird er Ihnen keine seltene Rasse liefern, von der er in seinen Trainingsdaten nur zwei Bilder gesehen hat; Sie erhalten wahrscheinlich einen Golden Retriever oder einen Labrador.
Kombinieren Sie diese beiden Dinge nun mit der Tatsache, dass das Internet von KI-generierten Inhalten überschwemmt wird und dass neue KI-Modelle diese Inhalte wahrscheinlich aufnehmen und darauf trainieren werden. Das bedeutet, dass sie eine viel von Goldenen!
Und wenn sie erst einmal auf diese Verbreitung von Golden Retrievern (oder mittelmäßigem Blogspam, falschen Gesichtern oder generierten Liedern) trainiert sind, ist das ihre neue Grundwahrheit. Sie werden denken, dass 90 % der Hunde wirklich Golden Retriever sind, und wenn sie daher aufgefordert werden, einen Hund zu generieren, werden sie den Anteil der Golden Retriever noch weiter erhöhen – bis sie im Grunde den Überblick darüber verloren haben, was Hunde überhaupt sind.
Diese wunderbare Illustration aus dem begleitenden Kommentarartikel von Nature veranschaulicht den Vorgang visuell:
Ähnliches passiert mit Sprachmodellen und anderen, die im Grunde die häufigsten Daten in ihrem Trainingsset für Antworten bevorzugen – was, um es klar zu sagen, normalerweise das Richtige ist. Es ist kein wirkliches Problem, bis es auf den Ozean aus Köder trifft, der derzeit das öffentliche Web ist.
Wenn die Modelle sich gegenseitig weiterhin Daten abgreifen, vielleicht ohne es zu wissen, werden sie im Grunde immer seltsamer und dümmer, bis sie zusammenbrechen. Die Forscher liefern zahlreiche Beispiele und Abhilfemaßnahmen, gehen aber so weit, den Zusammenbruch der Modelle zumindest theoretisch als „unvermeidlich“ zu bezeichnen.
Auch wenn es vielleicht nicht so ausgeht, wie die Experimente zeigen, sollte diese Möglichkeit jedem im KI-Bereich Angst machen. Vielfalt und Tiefe der Trainingsdaten werden zunehmend als der wichtigste Faktor für die Qualität eines Modells angesehen. Wenn die Daten ausgehen, aber mehr Daten generiert werden, besteht das Risiko eines Modellzusammenbruchs. Schränkt das die heutige KI grundsätzlich ein? Wenn es tatsächlich passiert, wie werden wir es wissen? Und können wir etwas tun, um das Problem zu verhindern oder abzumildern?
Zumindest auf die letzte Frage lässt sich vermutlich mit „Ja“ antworten, auch wenn das unsere Bedenken nicht zerstreuen sollte.
Qualitative und quantitative Benchmarks für Datenherkunft und -vielfalt würden helfen, aber wir sind noch weit davon entfernt, diese zu standardisieren. Wasserzeichen in KI-generierten Daten würden anderen KIs helfen, dies zu vermeiden, aber bisher hat niemand eine geeignete Möglichkeit gefunden, Bilder auf diese Weise zu markieren (also … ich schon).
Tatsächlich könnte es für Unternehmen sogar entmutigend sein, derartige Informationen weiterzugeben, und sie horten stattdessen alle überaus wertvollen, originalen und von Menschen generierten Daten, die sie kriegen können, um das zu wahren, was Shumailov et al. ihren „First-Mover-Vorteil“ nennen.
[Model collapse] muss ernst genommen werden, wenn wir die Vorteile des Trainings anhand von umfangreichen, aus dem Internet gecrawlten Daten aufrechterhalten wollen. Tatsächlich wird der Wert der über echte menschliche Interaktionen mit Systemen gesammelten Daten angesichts von LLM-generierten Inhalten in aus dem Internet gecrawlten Daten immer wertvoller.
… [I]Es könnte zunehmend schwieriger werden, neuere Versionen von LLMs zu trainieren, ohne Zugriff auf Daten zu haben, die vor der Masseneinführung der Technologie aus dem Internet gecrawlt wurden, oder ohne direkten Zugriff auf in großem Umfang von Menschen generierte Daten.
Fügen Sie es zu dem Stapel potenziell katastrophaler Herausforderungen für KI-Modelle hinzu – und zu den Argumenten gegen die heutigen Methoden, die Superintelligenz von morgen hervorzubringen.