
Das neueste Open-Source-KI-Modell von Meta ist das bisher größte.
Heute gab Meta bekannt, dass es Llama 3.1 405B veröffentlicht, ein Modell mit 405 Milliarden Parametern. Parameter entsprechen in etwa den Problemlösungsfähigkeiten eines Modells, und Modelle mit mehr Parametern schneiden im Allgemeinen besser ab als solche mit weniger Parametern.
Mit 405 Milliarden Parametern ist Llama 3.1 405B nicht das absolute größten Open-Source-Modell auf dem Markt, aber es ist das größte der letzten Jahre. Es wurde mit 16.000 Nvidia H100 GPUs trainiert und profitiert auch von neueren Trainings- und Entwicklungstechniken, die es laut Meta konkurrenzfähig zu führenden proprietären Modellen wie OpenAIs GPT-4o und Anthropics Claude 3.5 Sonnet machen (mit ein paar Einschränkungen).
Wie die Vorgängermodelle von Meta steht Llama 3.1 405B zum Download oder zur Nutzung auf Cloud-Plattformen wie AWS, Azure und Google Cloud zur Verfügung. Es wird auch auf WhatsApp und Meta.ai verwendet, wo es Ein Chatbot-Erlebnis schaffen für Benutzer mit Sitz in den USA.
Neu und verbessert
Wie andere Open- und Closed-Source-Modelle generativer KI kann Llama 3.1 405B eine Reihe verschiedener Aufgaben ausführen, von der Codierung und Beantwortung einfacher mathematischer Fragen bis hin zur Zusammenfassung von Dokumenten in acht Sprachen (Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch). Es ist nur Text, was bedeutet, dass es beispielsweise keine Fragen zu einem Bild beantworten kann, aber die meisten textbasierten Workloads – denken Sie an die Analyse von Dateien wie PDFs und Tabellenkalkulationen – fallen in seinen Zuständigkeitsbereich.
Meta möchte bekannt geben, dass es mit Multimodalität experimentiert. In einem heute veröffentlichten Artikel schreiben die Forscher des Unternehmens, dass sie aktiv Llama-Modelle entwickeln, die Bilder und Videos erkennen und Sprache verstehen (und generieren) können. Diese Modelle sind jedoch noch nicht zur Veröffentlichung bereit.
Um Llama 3.1 405B zu trainieren, verwendete Meta einen Datensatz von 15 Billionen Tokens aus dem Jahr 2024 (Tokens sind Wortteile, die Modelle leichter verinnerlichen können als ganze Wörter, und 15 Billionen Tokens entsprechen unglaublichen 750 Milliarden Wörtern). Es handelt sich nicht per se um einen neuen Trainingssatz, da Meta den Basissatz zum Trainieren früherer Llama-Modelle verwendet hat, aber das Unternehmen behauptet, es habe seine Kurationspipelines für Daten verfeinert und bei der Entwicklung dieses Modells „strengere“ Ansätze zur Qualitätssicherung und Datenfilterung übernommen.
Das Unternehmen verwendete auch synthetische Daten (Daten, die von andere KI-Modelle), um Llama 3.1 405B zu optimieren. Die meisten großen KI-Anbieter, darunter OpenAI und Anthropic, untersuchen Anwendungen synthetischer Daten, um ihr KI-Training zu skalieren, aber einige Experten glauben dass synthetische Daten ein letzter Ausweg aufgrund des Potenzials, den Modellfehler zu verstärken.
Meta wiederum betont, dass es „sorgfältig abwägt[d]„Llama 3.1 405Bs Trainingsdaten, weigerte sich jedoch, genau zu verraten, woher die Daten stammten (außer von Webseiten und öffentlichen Webdateien). Viele Anbieter generativer KI sehen Trainingsdaten als Wettbewerbsvorteil und halten sie und alle damit verbundenen Informationen daher geheim. Details zu Trainingsdaten sind jedoch auch eine potenzielle Quelle für IP-bezogene Klagen, was Unternehmen ebenfalls davon abhält, zu viel preiszugeben.
In dem oben erwähnten Artikel schrieben die Meta-Forscher, dass Llama 3.1 405B im Vergleich zu früheren Llama-Modellen mit einem größeren Mix aus nicht-englischen Daten (um die Leistung bei nicht-englischen Sprachen zu verbessern), mehr „mathematischen Daten“ und Code (um die mathematischen Denkfähigkeiten des Modells zu verbessern) und aktuellen Webdaten (um sein Wissen über aktuelle Ereignisse zu stärken) trainiert wurde.
Aktuelle Berichterstattung von Reuters enthüllte, dass Meta trotz der Warnungen seiner eigenen Anwälte einmal urheberrechtlich geschützte E-Books für das KI-Training verwendet hat. Das Unternehmen trainiert seine KI kontrovers anhand von Instagram- und Facebook-Posts, Fotos und Bildunterschriften und erschwert den Benutzern die DeaktivierungDarüber hinaus ist Meta zusammen mit OpenAI Gegenstand eines laufenden Gerichtsverfahrens von Autoren, darunter der Komikerin Sarah Silverman, wegen der angeblichen unbefugten Verwendung urheberrechtlich geschützter Daten durch die Unternehmen für das Modelltraining.
„Die Trainingsdaten sind in vielerlei Hinsicht so etwas wie das Geheimrezept und die Soße, die in den Aufbau dieser Modelle einfließt“, sagte Ragavan Srinivasan, Vizepräsident für KI-Programmmanagement bei Meta, in einem Interview mit Tech. „Aus unserer Sicht haben wir viel darin investiert. Und es wird eines dieser Dinge sein, an denen wir es weiter verfeinern werden.“
Größerer Kontext und Werkzeuge
Llama 3.1 405B hat ein größeres Kontextfenster als frühere Llama-Modelle: 128.000 Token oder ungefähr die Länge eines 50-seitigen Buches. Der Kontext oder das Kontextfenster eines Modells bezieht sich auf die Eingabedaten (z. B. Text), die das Modell berücksichtigt, bevor es eine Ausgabe (z. B. zusätzlichen Text) generiert.
Einer der Vorteile von Modellen mit größeren Kontexten besteht darin, dass sie längere Textausschnitte und Dateien zusammenfassen können. Bei der Bereitstellung von Chatbots ist es außerdem weniger wahrscheinlich, dass solche Modelle Themen vergessen, die kürzlich besprochen wurden.
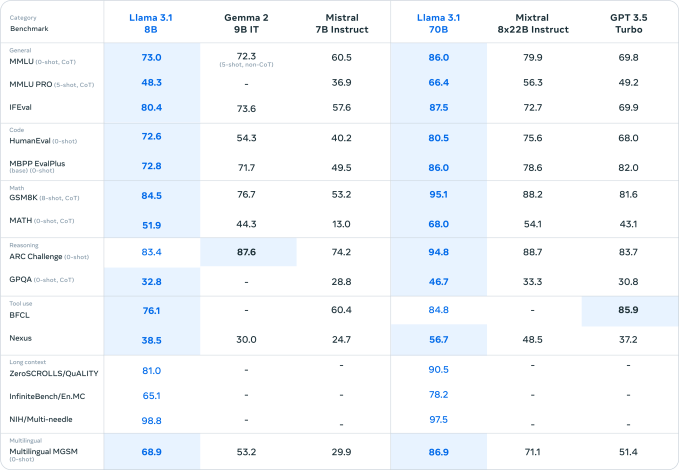
Zwei weitere neue, kleinere Modelle, die Meta heute vorgestellt hat, Llama 3.1 8B und Llama 3.1 70B – aktualisierte Versionen der im April erschienenen Modelle Llama 3 8B und Llama 3 70B des Unternehmens – verfügen ebenfalls über Kontextfenster mit 128.000 Token. Die Kontexte der vorherigen Modelle waren auf 8.000 Token begrenzt, was dieses Upgrade ziemlich umfangreich macht – vorausgesetzt, die neuen Llama-Modelle können über all diese Kontexte hinweg effektiv argumentieren.
Alle Llama 3.1-Modelle können Tools, Apps und APIs von Drittanbietern verwenden, um Aufgaben zu erledigen, wie konkurrierende Modelle von Anthropic und OpenAI. Sie sind sofort einsatzbereit und können Brave Search verwenden, um Fragen zu aktuellen Ereignissen zu beantworten, die Wolfram Alpha API für mathematisch-wissenschaftliche Abfragen und einen Python-Interpreter zur Validierung von Code. Darüber hinaus behauptet Meta, dass die Llama 3.1-Modelle bestimmte Tools verwenden können, die sie bisher noch nicht gesehen haben – bis zu einem gewissen Grad.
Aufbau eines Ökosystems
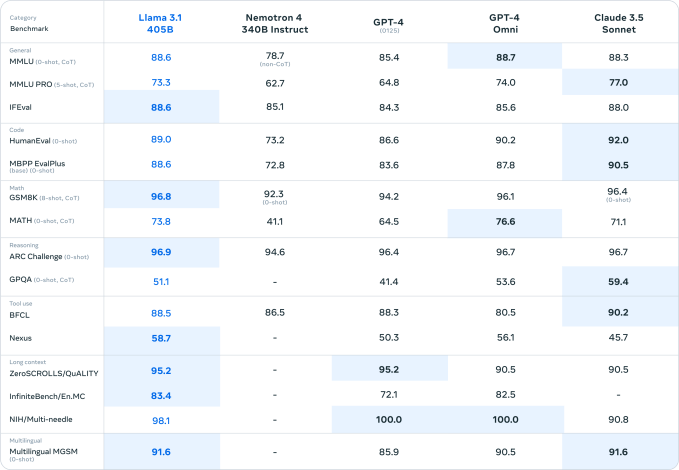
Wenn man Benchmarks Glauben schenken darf (nicht, dass Benchmarks das A und O in der generativen KI sind), ist Llama 3.1 405B in der Tat ein sehr leistungsfähiges Modell. Das wäre eine gute Sache, wenn man einige der schmerzlich offensichtlich Einschränkungen der Llama-Modelle der vorherigen Generation.
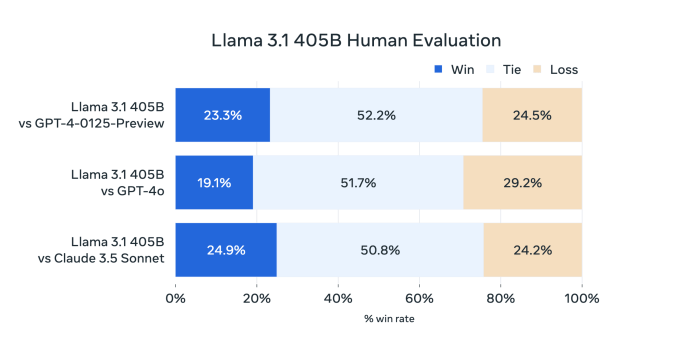
Die Leistung von Llama 3 405B ist mit der von OpenAI GPT-4 vergleichbar und erzielt laut den von Meta beauftragten menschlichen Gutachtern „gemischte Ergebnisse“ im Vergleich zu GPT-4o und Claude 3.5 Sonnet, heißt es in dem Papier. Während Llama 3 405B beim Ausführen von Code und Generieren von Diagrammen besser ist als GPT-4o, sind seine mehrsprachigen Fähigkeiten insgesamt schwächer und Llama 3 405B liegt in den Bereichen Programmierung und allgemeines Denken hinter Claude 3.5 Sonnet zurück.
Und aufgrund seiner Größe ist für den Betrieb leistungsstarke Hardware erforderlich. Meta empfiehlt mindestens einen Serverknoten.
Das ist vielleicht der Grund, warum Meta seine kleineren neuen Modelle Llama 3.1 8B und Llama 3.1 70B für allgemeine Anwendungen wie die Bereitstellung von Chatbots und die Generierung von Code vorantreibt. Llama 3.1 405B, so das Unternehmen, sei besser für die Modelldestillation geeignet – den Prozess der Übertragung von Wissen von einem großen Modell auf ein kleineres, effizienteres Modell – und die Generierung synthetischer Daten zum Trainieren (oder Feinabstimmen) alternativer Modelle.
Um den Anwendungsfall synthetischer Daten zu fördern, hat Meta die Lizenz von Llama aktualisiert, damit Entwickler die Ergebnisse der Modellfamilie Llama 3.1 verwenden können, um generative KI-Modelle von Drittanbietern zu entwickeln (ob das eine kluge Idee ist, ist zur Debatte). Wichtig ist, dass die Lizenz immer noch Einschränkungen So können Entwickler Llama-Modelle einsetzen: App-Entwickler mit mehr als 700 Millionen monatlichen Benutzern müssen bei Meta eine spezielle Lizenz anfordern, die das Unternehmen nach eigenem Ermessen gewährt.
Diese Änderung der Lizenzierung der Outputs, die eine große Kritik von Metas Modellen innerhalb der KI-Community ist Teil der aggressiven Bemühungen des Unternehmens, sich einen Namen im Bereich der generativen KI zu machen.
Neben der Llama 3.1-Familie veröffentlicht Meta ein sogenanntes „Referenzsystem“ und neue Sicherheitstools – einige dieser Blockaufforderungen könnten dazu führen, dass sich Llama-Modelle unvorhersehbar oder unerwünscht verhalten –, um Entwickler zu ermutigen, Llama an mehr Stellen zu verwenden. Das Unternehmen stellt auch den Llama Stack vor und bittet um Kommentare dazu. Dabei handelt es sich um eine bevorstehende API für Tools, mit denen Llama-Modelle optimiert, synthetische Daten mit Llama generiert und „agentische“ Anwendungen erstellt werden können – Apps, die von Llama betrieben werden und im Namen eines Benutzers Aktionen ausführen können.
„[What] Wir haben wiederholt von Entwicklern gehört, dass sie daran interessiert sind, zu lernen, wie man sie tatsächlich einsetzt [Llama models] in der Produktion“, sagte Srinivasan. „Deshalb versuchen wir, ihnen eine Reihe verschiedener Tools und Optionen anzubieten.“
Spiel um Marktanteile
In einem heute Morgen veröffentlichten offenen Brief legt Meta-CEO Mark Zuckerberg eine Vision für die Zukunft dar, in der KI-Tools und -Modelle in die Hände von mehr Entwicklern auf der ganzen Welt gelangen und so sichergestellt wird, dass die Menschen Zugang zu den „Vorteilen und Möglichkeiten“ der KI haben.
Der Brief ist zwar sehr philanthropisch formuliert, bringt aber implizit Zuckerbergs Wunsch zum Ausdruck, dass diese Werkzeuge und Modelle von Meta stammen sollen.
Meta versucht, mit Unternehmen wie OpenAI und Anthropic gleichzuziehen und verfolgt dabei eine bewährte Strategie: Tools kostenlos zur Verfügung stellen, um ein Ökosystem aufzubauen, und dann langsam weitere hinzufügen. Produkte und Dienstleistungen, einige davon kostenpflichtig, zusätzlich. Milliarden Dollar Die Entwicklung von Modellen, die dann zur Massenware werden können, hat auch den Effekt, dass die Preise der Meta-Konkurrenten sinken und die KI-Version des Unternehmens weit verbreitet wird. Außerdem kann das Unternehmen so Verbesserungen aus der Open-Source-Community in seine zukünftigen Modelle integrieren.
Llama hat die Aufmerksamkeit der Entwickler definitiv auf sich gezogen. Meta behauptet, dass Llama-Modelle über 300 Millionen Mal heruntergeladen wurden und bisher mehr als 20.000 von Llama abgeleitete Modelle erstellt wurden.
Machen Sie keinen Fehler, Meta spielt um den Sieg. Es gibt Millionen darauf, die Regulierungsbehörden dazu zu bewegen, sich der von ihr bevorzugten Variante einer „offenen“ generativen KI anzuschließen. Keines der Llama 3.1-Modelle löst die hartnäckigen Probleme der heutigen generativen KI-Technologie, wie etwa ihre Tendenz, Dinge zu erfinden und problematische Trainingsdaten wiederzukäuen. Aber sie fördern eines der Hauptziele von Meta: zum Synonym für generative KI zu werden.
Das hat seinen Preis. In der Forschungsarbeit schreiben die Koautoren – in Anlehnung an Zuckerbergs Letzte Kommentare – diskutieren Sie energiebezogene Zuverlässigkeitsprobleme, indem Sie die ständig wachsenden generativen KI-Modelle von Meta trainieren.
„Während des Trainings können Zehntausende von GPUs gleichzeitig ihren Stromverbrauch erhöhen oder verringern, beispielsweise weil alle GPUs auf den Abschluss von Checkpointing oder kollektiver Kommunikation warten oder weil der gesamte Trainingsjob gestartet oder beendet wird“, schreiben sie. „Wenn dies geschieht, kann es zu sofortigen Schwankungen des Stromverbrauchs im gesamten Rechenzentrum in der Größenordnung von mehreren zehn Megawatt führen und die Grenzen des Stromnetzes überschreiten. Dies ist eine ständige Herausforderung für uns, da wir das Training für zukünftige, noch größere Llama-Modelle skalieren.“
Man kann nur hoffen, dass das Training dieser größeren Modelle nicht dazu führt, dass mehr Versorgungsunternehmen alte Kohlekraftwerke in der Umgebung.