
Meta hat freigegeben der neueste Eintrag in seiner Llama-Reihe generativer Open-Source-KI-Modelle: Llama 3. Genauer gesagt hat das Unternehmen zwei Modelle seiner neuen Llama-3-Familie als Open-Source-Modell bereitgestellt, der Rest soll zu einem unbestimmten Zeitpunkt in der Zukunft erscheinen.
Meta beschreibt die neuen Modelle – Llama 3 8B, das 8 Milliarden Parameter enthält, und Llama 3 70B, das 70 Milliarden Parameter enthält – als „großen Sprung“ im Vergleich zu den Llama-Modellen der vorherigen Generation, Llama 2 8B und Llama 2 70B. Leistungsmäßig. (Parameter definieren im Wesentlichen die Fähigkeiten eines KI-Modells für ein Problem, wie das Analysieren und Generieren von Text; Modelle mit höherer Parameteranzahl sind im Allgemeinen leistungsfähiger als Modelle mit niedrigerer Parameteranzahl.) Tatsächlich sagt Meta, dass z ihre jeweiligen Parameteranzahlen, Llama 3 8B und Llama 3 70B – trainiert auf zwei speziell angefertigten 24.000 GPU-Clustern – sind gehören zu den leistungsstärksten generativen KI-Modellen, die heute verfügbar sind.
Das ist ein ziemlicher Anspruch. Wie unterstützt Meta es? Nun, das Unternehmen verweist auf die Ergebnisse der Llama 3-Modelle bei beliebten KI-Benchmarks wie MMLU (der versucht, Wissen zu messen), ARC (der versucht, den Kompetenzerwerb zu messen) und DROP (der die Argumentation eines Modells anhand von Textabschnitten testet). Wie wir bereits geschrieben haben, steht der Nutzen – und die Gültigkeit – dieser Benchmarks zur Debatte. Aber im Guten wie im Schlechten bleiben sie eine der wenigen standardisierten Methoden, mit denen KI-Spieler wie Meta ihre Modelle bewerten.
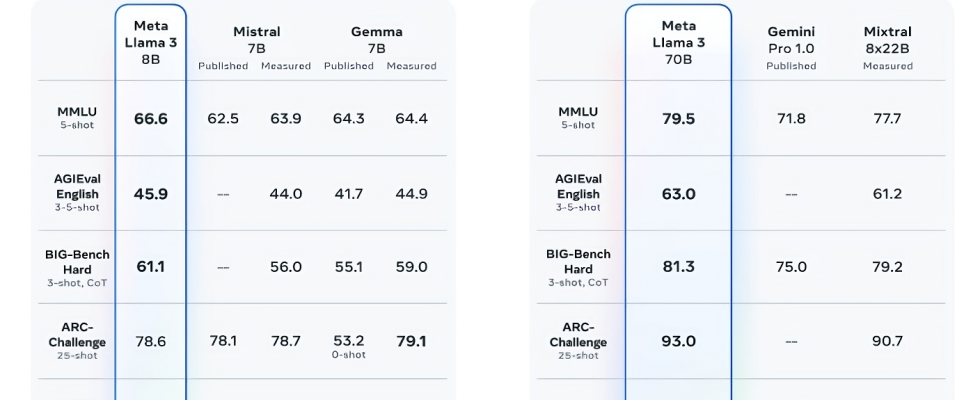
Llama 3 8B übertrifft andere Open-Source-Modelle wie Mistral 7B und Gemma 7B von Google, die beide 7 Milliarden Parameter enthalten, bei mindestens neun Benchmarks: MMLU, ARC, DROP, GPQA (eine Reihe von Biologie-, Physik- und Chemie-) verwandte Fragen), HumanEval (ein Test zur Codegenerierung), GSM-8K (Mathe-Textaufgaben), MATH (ein weiterer Mathematik-Benchmark), AGIEval (ein Testsatz zur Problemlösung) und BIG-Bench Hard (eine Bewertung des gesunden Menschenverstandes).
Nun sind Mistral 7B und Gemma 7B nicht gerade auf dem neuesten Stand (Mistral 7B wurde letzten September veröffentlicht), und in einigen Benchmarks, die Meta zitiert, schneidet Llama 3 8B nur ein paar Prozentpunkte besser ab als beide. Meta behauptet aber auch, dass das Llama 3-Modell mit der größeren Parameteranzahl, Llama 3 70B, mit Flaggschiffmodellen für generative KI konkurrenzfähig ist, darunter Gemini 1.5 Pro, das neueste Modell der Gemini-Serie von Google.
Bildnachweis: Meta
Llama 3 70B schlägt Gemini 1.5 Pro bei MMLU, HumanEval und GSM-8K, und obwohl es nicht mit dem leistungsstärksten Modell von Anthropic, Claude 3 Opus, mithalten kann, schneidet Llama 3 70B besser ab als das schwächste Modell der Claude 3-Serie, Claude 3 Sonnet, auf fünf Benchmarks (MMLU, GPQA, HumanEval, GSM-8K und MATH).
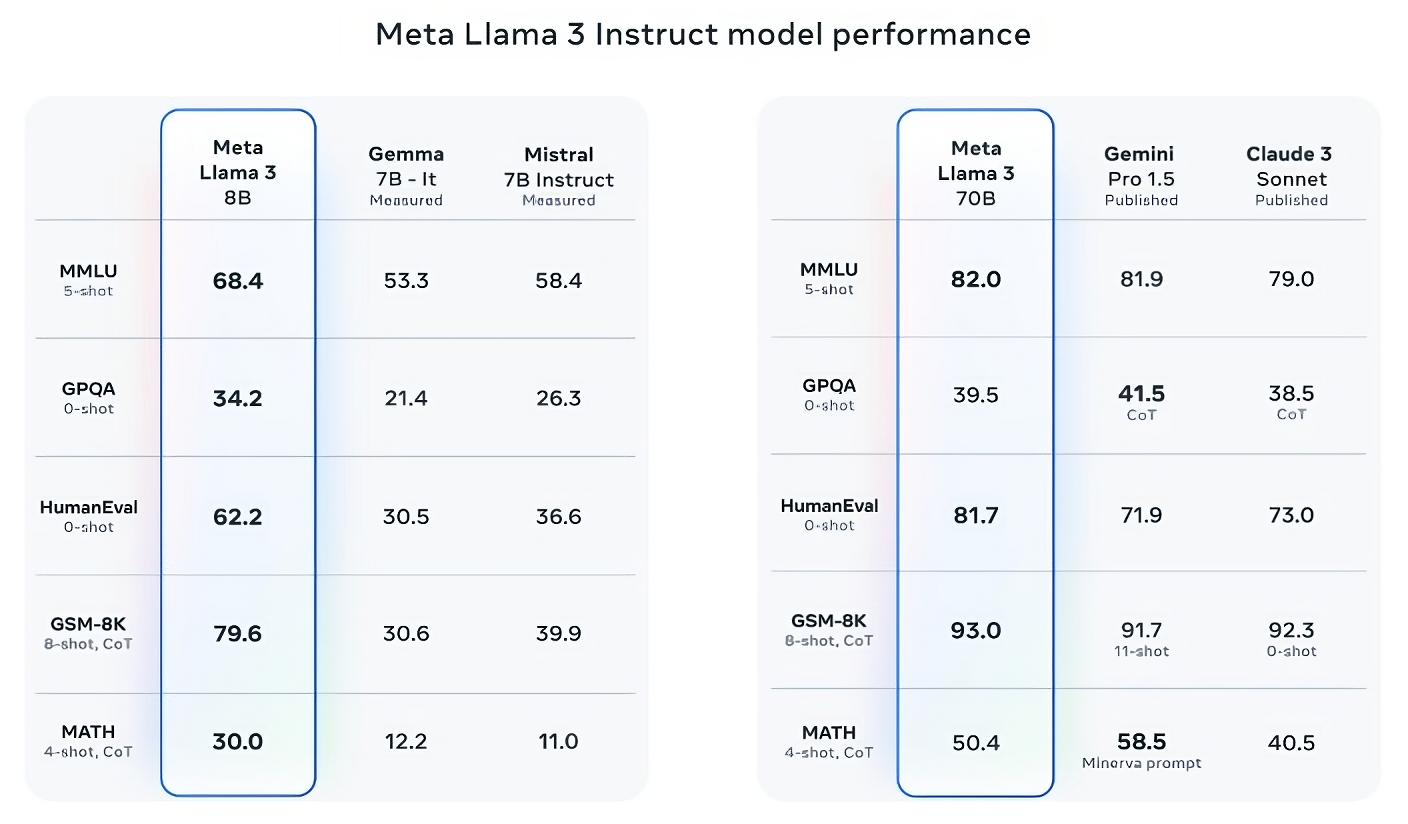
Bildnachweis: Meta
Meta hat außerdem ein eigenes Testset entwickelt, das Anwendungsfälle abdeckt, die vom Codieren und Verfassen von Texten über Argumentation bis hin zur Zusammenfassung reichen, und – Überraschung! – Llama 3 70B setzte sich gegen Mistrals Modell Mistral Medium, OpenAIs GPT-3.5 und Claude Sonnet durch. Meta sagt, dass es seinen Modellierungsteams den Zugriff auf das Set verwehrt hat, um die Objektivität zu wahren, aber angesichts der Tatsache, dass Meta den Test selbst entwickelt hat, sind die Ergebnisse natürlich mit Vorsicht zu genießen.

Bildnachweis: Meta
Auf qualitativerer Ebene sagt Meta, dass Benutzer der neuen Llama-Modelle mehr „Steuerbarkeit“, eine geringere Wahrscheinlichkeit, die Beantwortung von Fragen zu verweigern, und eine höhere Genauigkeit bei Quizfragen, Fragen im Zusammenhang mit Geschichte und MINT-Bereichen wie Ingenieurwesen und Naturwissenschaften sowie allgemeinem Programmieren erwarten sollten Empfehlungen. Dies ist zum Teil einem viel größeren Datensatz zu verdanken: einer Sammlung von 15 Billionen Token oder unglaublichen ~750.000.000.000 Wörtern – siebenmal so groß wie der Llama 2-Trainingssatz. (Im KI-Bereich bezieht sich „Token“ auf unterteilte Rohdatenbits, wie die Silben „fan“, „tas“ und „tic“ im Wort „fantastic“.)
Woher stammen diese Daten? Gute Frage. Meta wollte das nicht sagen und enthüllte nur, dass es aus „öffentlich zugänglichen Quellen“ stammte, viermal mehr Code enthielt als im Llama 2-Trainingsdatensatz und dass 5 % dieses Satzes nicht-englische Daten enthielten (in etwa 30 Sprachen). um die Leistung in anderen Sprachen als Englisch zu verbessern. Meta sagte auch, dass es synthetische Daten – also KI-generierte Daten – verwendet habe, um längere Dokumente für das Training der Llama-3-Modelle zu erstellen. ein etwas kontroverser Ansatz aufgrund möglicher Leistungseinbußen.
„Während die Modelle, die wir heute veröffentlichen, nur für englische Ausgaben optimiert sind, hilft die erhöhte Datenvielfalt den Modellen, Nuancen und Muster besser zu erkennen und bei einer Vielzahl von Aufgaben eine starke Leistung zu erbringen“, schreibt Meta in einem mit Tech geteilten Blogbeitrag.
Viele Anbieter generativer KI betrachten Trainingsdaten als Wettbewerbsvorteil und halten diese und die damit verbundenen Informationen daher stets griffbereit. Aber auch Details zu Trainingsdaten sind eine potenzielle Quelle für Klagen im Zusammenhang mit geistigem Eigentum, ein weiterer Anreiz, viel preiszugeben. Aktuelle Berichterstattung enthüllte, dass Meta in seinem Bestreben, mit der KI-Konkurrenz Schritt zu halten, trotz der Warnungen der unternehmenseigenen Anwälte einmal urheberrechtlich geschützte E-Books für die KI-Schulung verwendet hat; Meta und OpenAI sind Gegenstand einer laufenden Klage von Autoren, darunter der Komikerin Sarah Silverman, wegen der angeblich unbefugten Nutzung urheberrechtlich geschützter Daten durch die Anbieter für Schulungen.
Was ist also mit Toxizität und Voreingenommenheit, zwei weiteren häufigen Problemen bei generativen KI-Modellen (einschließlich Lama 2)? Verbessert sich Llama 3 in diesen Bereichen? Ja, behauptet Meta.
Meta sagt, dass es neue Datenfilterungspipelines entwickelt hat, um die Qualität seiner Modelltrainingsdaten zu verbessern, und dass es sein Paar generativer KI-Sicherheitssuiten, Llama Guard und CybersecEval, aktualisiert hat, um zu versuchen, den Missbrauch und unerwünschte Textgenerierungen von Llama zu verhindern 3 Modelle und andere. Das Unternehmen veröffentlicht außerdem ein neues Tool, Code Shield, das darauf ausgelegt ist, Code aus generativen KI-Modellen zu erkennen, der möglicherweise Sicherheitslücken mit sich bringt.
Das Filtern ist jedoch nicht narrensicher – und Tools wie Llama Guard, CybersecEval und Code Shield reichen nur bis zu einem gewissen Grad. (Siehe: Die Tendenz von Lama 2 dazu Antworten auf Fragen erfinden und private Gesundheits- und Finanzinformationen preisgeben.) Wir müssen abwarten, wie sich die Llama-3-Modelle in freier Wildbahn schlagen, einschließlich der Tests von Wissenschaftlern mit alternativen Benchmarks.
Meta sagt, dass die Llama 3-Modelle – die jetzt zum Download verfügbar sind und den Meta-KI-Assistenten von Meta auf Facebook, Instagram, WhatsApp, Messenger und im Internet unterstützen – bald in verwalteter Form auf einer Vielzahl von Cloud-Plattformen gehostet werden, darunter AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBMs WatsonX, Microsoft Azure, Nvidias NIM und Snowflake. Zukünftig werden auch Versionen der Modelle verfügbar sein, die für Hardware von AMD, AWS, Dell, Intel, Nvidia und Qualcomm optimiert sind.
Und leistungsfähigere Modelle sind in Sicht.
Meta sagt, dass es derzeit Llama-3-Modelle mit einer Größe von über 400 Milliarden Parametern trainiert – Modelle mit der Fähigkeit, „in mehreren Sprachen zu kommunizieren“, mehr Daten aufzunehmen und Bilder und andere Modalitäten sowie Text zu verstehen, was die Llama-3-Serie hervorbringen würde im Einklang mit offenen Veröffentlichungen wie Hugging Face’s Ideen2.

Bildnachweis: Meta
„Unser Ziel in naher Zukunft ist es, Llama 3 mehrsprachig und multimodal zu machen, einen längeren Kontext zu haben und die Gesamtleistung im gesamten Kern weiter zu verbessern [large language model] Fähigkeiten wie Argumentation und Codierung“, schreibt Meta in einem Blogbeitrag. „Es kommt noch viel mehr.“
In der Tat.