
OctoAI (früher bekannt als OctoML), kündigte die Einführung von OctoStack an, seiner neuen End-to-End-Lösung für die Bereitstellung generativer KI-Modelle in der privaten Cloud eines Unternehmens, sei es vor Ort oder in einer virtuellen privaten Cloud von einem der großen Anbieter. darunter AWS, Google, Microsoft und Azure sowie CoreWeave, Lambda Labs, Snowflake und andere.
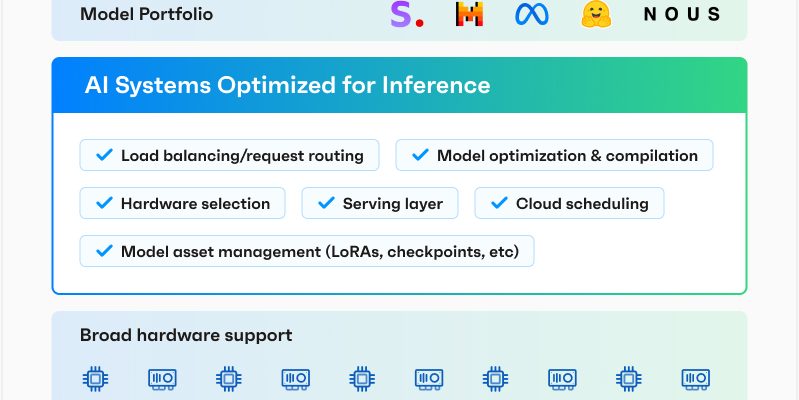
In seinen Anfängen konzentrierte sich OctoAI fast ausschließlich auf die Optimierung von Modellen, um sie effektiver laufen zu lassen. Basierend auf Apache TVM Nachdem das Unternehmen das Compiler-Framework für maschinelles Lernen entwickelt hatte, startete es dann seine TVM-as-a-Service-Plattform und erweiterte diese im Laufe der Zeit zu einem vollwertigen Model-Serving-Angebot, das seine Optimierungsmöglichkeiten mit einer DevOps-Plattform kombinierte. Mit dem Aufkommen der generativen KI startete das Team dann die vollständig verwaltete OctoAI-Plattform, um seinen Nutzern bei der Bedienung und Feinabstimmung vorhandener Modelle zu helfen. OctoStack ist im Kern die OctoAI-Plattform, jedoch für private Bereitstellungen.
Bildnachweis: OctoAI
OctoAI CEO und Mitbegründer Luis Céze Mir wurde gesagt, dass das Unternehmen über 25.000 Entwickler auf der Plattform und Hunderte zahlende Kunden hat, die sie in der Produktion nutzen. Viele dieser Unternehmen, sagte Ceze, seien GenAI-native Unternehmen. Der Markt der traditionellen Unternehmen, die generative KI einführen möchten, ist jedoch deutlich größer, daher ist es vielleicht keine Überraschung, dass OctoAI mit OctoStack nun auch sie anspricht.
„Eine Sache, die deutlich wurde, ist, dass, während der Unternehmensmarkt letztes Jahr von Experimenten zu Bereitstellungen übergeht, sich zum einen alle umschauen, weil sie nervös sind, Daten über eine API zu senden“, sagte Ceze. „Zweitens: Viele von ihnen haben auch ihre eigene Rechenleistung bereitgestellt. Warum sollte ich also eine API kaufen, wenn ich bereits über eine eigene Rechenleistung verfüge? Und drittens: Ganz gleich, welche Zertifizierungen Sie erhalten und wie groß Ihr Name ist, sie haben das Gefühl, dass ihre KI ebenso wertvoll ist wie ihre Daten, und sie möchten sie nicht weitergeben. Es besteht also ein wirklich klarer Bedarf im Unternehmen, die Bereitstellung unter Ihrer Kontrolle zu haben.“
Ceze wies darauf hin, dass das Team schon seit einiger Zeit an der Entwicklung der Architektur arbeite, um sowohl die SaaS- als auch die gehostete Plattform anzubieten. Und während die SaaS-Plattform für Nvidia-Hardware optimiert ist, kann OctoStack eine weitaus größere Auswahl an Hardware unterstützen, einschließlich AMD-GPUs und Inferentia von AWS Beschleuniger, was wiederum die Optimierungsherausforderung um einiges schwieriger macht (und gleichzeitig die Stärken von OctoAI ausnutzt).
Die Bereitstellung von OctoStack sollte für die meisten Unternehmen unkompliziert sein, da OctoAI die Plattform mit sofort lesbaren Containern und den zugehörigen Helm-Charts für Bereitstellungen bereitstellt. Für Entwickler bleibt die API dieselbe, egal ob sie das SaaS-Produkt oder OctoAI in ihrer privaten Cloud im Visier haben.
Der kanonische Unternehmensanwendungsfall verwendet weiterhin Textzusammenfassung und RAG, um Benutzern das Chatten mit ihren internen Dokumenten zu ermöglichen. Einige Unternehmen optimieren diese Modelle jedoch auch auf ihrer internen Codebasis, um ihre eigenen Codegenerierungsmodelle auszuführen (ähnlich dem, was GitHub jetzt anbietet). für Copilot Enterprise-Benutzer).
Für viele Unternehmen ist die Möglichkeit, dies in einer sicheren Umgebung tun zu können, die streng unter ihrer Kontrolle steht, der Grund dafür, dass sie diese Technologien nun für ihre Mitarbeiter und Kunden in die Produktion bringen können.
„Für unseren leistungs- und sicherheitsrelevanten Anwendungsfall ist es unerlässlich, dass die Modelle, die Anrufdaten verarbeiten, in einer Umgebung laufen, die Flexibilität, Skalierbarkeit und Sicherheit bietet“, sagte Dali Kaafar, Gründer und CEO von Apate KI. „OctoStack ermöglicht es uns, die von uns benötigten maßgeschneiderten Modelle einfach und effizient in den von uns gewählten Umgebungen auszuführen und den Umfang zu liefern, den unsere Kunden benötigen.“