
Deepgram hat sich als eines der führenden Startups für Spracherkennung einen Namen gemacht. Heute gab das kapitalkräftige Unternehmen den Start von bekannt Aura, seine neue Echtzeit-Text-to-Speech-API. Aura kombiniert äußerst realistische Sprachmodelle mit einer API mit geringer Latenz, die es Entwicklern ermöglicht, konversationsfähige KI-Agenten in Echtzeit zu erstellen. Unterstützt durch große Sprachmodelle (LLMs) können diese Agenten dann Kundendienstmitarbeiter in Callcentern und anderen Situationen mit Kundenkontakt vertreten.
Wie mir Scott Stephenson, Mitbegründer und CEO von Deepgram, sagte, ist es schon seit langem möglich, auf großartige Sprachmodelle zuzugreifen, aber diese waren teuer und die Berechnung dauerte lange. Unterdessen neigen Modelle mit geringer Latenz dazu, roboterhaft zu klingen. Deepgrams Aura kombiniert menschenähnliche Sprachmodelle, die extrem schnell rendern (normalerweise in deutlich unter einer halben Sekunde) und dies, wie Stephenson wiederholt anmerkte, zu einem niedrigen Preis.
Bildnachweis: Deepgram
„Jeder sagt jetzt: ‚Hey, wir brauchen Sprach-KI-Bots in Echtzeit, die wahrnehmen können, was gesagt wird, und die verstehen und eine Antwort generieren können – und dann können sie antworten‘“, sagte er. Seiner Ansicht nach bedarf es einer Kombination aus Genauigkeit (die er als Grundvoraussetzung für einen Dienst wie diesem bezeichnete), geringer Latenz und akzeptablen Kosten, um ein solches Produkt für Unternehmen lohnenswert zu machen, insbesondere in Kombination mit den relativ hohen Kosten für den Zugriff auf LLMs .
Deepgram argumentiert, dass die Preise von Aura derzeit mit 0,015 US-Dollar pro 1.000 Zeichen praktisch alle Konkurrenten übertreffen. Das ist gar nicht so weit von den Preisen von Google entfernt WaveNet-Stimmen bei 0,016 pro 1.000 Zeichen und Polly’s von Amazon Neuronal Stimmen kosten ebenfalls 0,016 US-Dollar pro 1.000 Zeichen, sind aber – zugegeben – günstiger. Die höchste Stufe von Amazon ist jedoch deutlich teurer.
„Man muss insgesamt einen wirklich guten Preis erzielen [segments], aber dann muss man auch erstaunliche Latenzen und Geschwindigkeit haben – und dann auch erstaunliche Genauigkeit. Es ist also wirklich schwer zu erreichen“, sagte Stephenson über den allgemeinen Ansatz von Deepgram bei der Entwicklung seines Produkts. „Aber darauf haben wir uns von Anfang an konzentriert und deshalb haben wir vier Jahre lang daran gearbeitet, bevor wir etwas veröffentlicht haben, weil wir die zugrunde liegende Infrastruktur aufgebaut haben, um dies zu verwirklichen.“
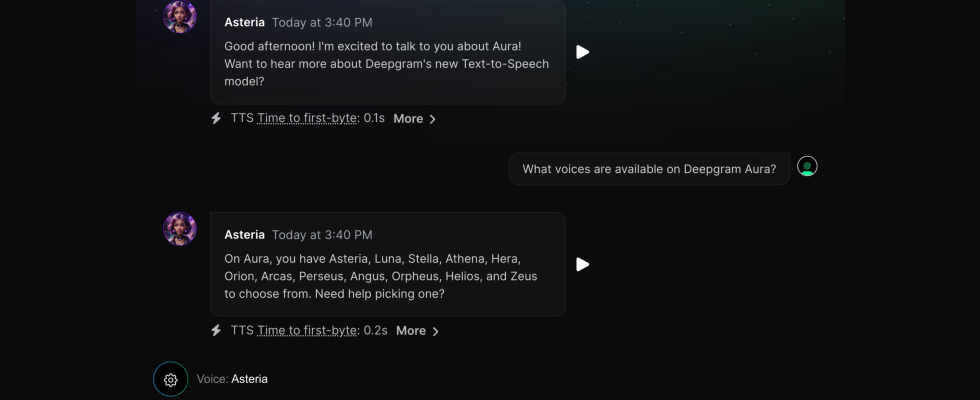
Aura bietet herum ein Dutzend Zu diesem Zeitpunkt wurden Sprachmodelle erstellt, die alle mithilfe eines Datensatzes trainiert wurden, den Deepgram zusammen mit Synchronsprechern erstellt hatte. Das Aura-Modell wurde wie alle anderen Modelle des Unternehmens intern geschult. So klingt das:
Hier können Sie eine Demo von Aura ausprobieren. Ich habe es eine Weile getestet und auch wenn Sie manchmal auf einige seltsame Aussprachen stoßen, ist neben dem bestehenden hochwertigen Speech-to-Text-Modell von Deepgram vor allem die Geschwindigkeit das Besondere. Um die Geschwindigkeit hervorzuheben, mit der es Antworten generiert, notiert Deepgram die Zeit, die das Modell brauchte, um mit dem Sprechen zu beginnen (im Allgemeinen weniger als 0,3 Sekunden) und wie lange es dauerte, bis das LLM seine Antwort generierte (normalerweise knapp eine Sekunde).