
Die Forschung auf dem Gebiet des maschinellen Lernens und der KI, mittlerweile eine Schlüsseltechnologie in praktisch jeder Branche und jedem Unternehmen, ist viel zu umfangreich, als dass jemand sie vollständig lesen könnte. Diese Kolumne, Perceptron (früher Deep Science), zielt darauf ab, einige der relevantesten jüngsten Entdeckungen und Artikel zu sammeln – insbesondere im Bereich der künstlichen Intelligenz, aber nicht darauf beschränkt – und zu erklären, warum sie wichtig sind.
Diese Woche im Bereich KI zeigt eine neue Studie, wie Voreingenommenheit, ein häufiges Problem bei KI-Systemen, mit den Anweisungen beginnen kann, die den rekrutierten Personen gegeben werden, um Daten zu kommentieren, aus denen KI-Systeme lernen, Vorhersagen zu treffen. Die Koautoren stellen fest, dass Annotatoren Muster in den Anweisungen aufgreifen, die sie dazu bringen, Anmerkungen beizusteuern, die dann in den Daten überrepräsentiert werden, wodurch das KI-System auf diese Anmerkungen ausgerichtet wird.
Viele KI-Systeme „lernen“ heute, Bilder, Videos, Text und Audio anhand von Beispielen zu verstehen, die von Kommentatoren gekennzeichnet wurden. Die Beschriftungen ermöglichen es den Systemen, die Beziehungen zwischen den Beispielen (z. B. die Verknüpfung zwischen der Überschrift „Küchenspüle“ und einem Foto einer Küchenspüle) auf Daten zu extrapolieren, die die Systeme zuvor nicht gesehen haben (z. B. Fotos von Küchenspülen, die keine nicht in den Daten enthalten, die zum „Lernen“ des Modells verwendet werden).
Das funktioniert bemerkenswert gut. Aber Annotation ist ein unvollkommener Ansatz – Annotatoren bringen Vorurteile auf den Tisch, die in das trainierte System einfließen können. Studien haben zum Beispiel gezeigt, dass die durchschnittlicher Kommentator wahrscheinlicher Sätze in African-American Vernacular English (AAVE), der informellen Grammatik, die von einigen schwarzen Amerikanern verwendet wird, als giftig kennzeichnen, führende KI-Toxizitätsdetektoren, die auf den Etiketten geschult wurden, um AAVE als unverhältnismäßig giftig zu sehen.
Wie sich herausstellt, sind die Prädispositionen der Kommentatoren möglicherweise nicht allein für das Vorhandensein von Voreingenommenheit in den Trainingsetiketten verantwortlich. In einem Vordruck lernen von der Arizona State University und dem Allen Institute for AI untersuchten Forscher, ob eine Quelle für Verzerrungen in den Anweisungen liegen könnte, die von den Erstellern von Datensätzen geschrieben wurden, um als Leitfaden für Kommentatoren zu dienen. Solche Anweisungen enthalten normalerweise eine kurze Beschreibung der Aufgabe (z. B. „Beschrifte alle Vögel auf diesen Fotos“) zusammen mit mehreren Beispielen.
Bildnachweis: Parmaret al.
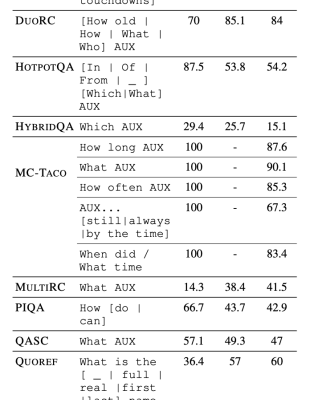
Die Forscher untersuchten 14 verschiedene „Benchmark“-Datensätze, die verwendet werden, um die Leistung von Verarbeitungssystemen für natürliche Sprache oder von KI-Systemen zu messen, die Text klassifizieren, zusammenfassen, übersetzen und anderweitig analysieren oder manipulieren können. Bei der Untersuchung der Aufgabenanweisungen für Annotatoren, die an den Datensätzen arbeiteten, fanden sie Hinweise darauf, dass die Anweisungen die Annotatoren dazu veranlassten, bestimmten Mustern zu folgen, die dann an die Datensätze weitergegeben wurden. Zum Beispiel beginnt mehr als die Hälfte der Anmerkungen in Quoref, einem Datensatz, der entwickelt wurde, um die Fähigkeit von KI-Systemen zu testen, zu verstehen, wenn sich zwei oder mehr Ausdrücke auf dieselbe Person (oder Sache) beziehen, mit dem Satz „Wie ist der Name“. ein Satz, der in einem Drittel der Anweisungen für den Datensatz vorhanden ist.
Das Phänomen, das die Forscher „Instruction Bias“ nennen, ist besonders besorgniserregend, da es darauf hindeutet, dass Systeme, die mit voreingenommenen Instruktions-/Anmerkungsdaten trainiert wurden, möglicherweise nicht so gut funktionieren wie ursprünglich angenommen. Tatsächlich stellten die Co-Autoren fest, dass die Anweisungsverzerrung die Leistung von Systemen überschätzt und dass diese Systeme häufig nicht über Anweisungsmuster hinaus verallgemeinern können.
Der Silberstreif am Horizont ist, dass sich herausstellte, dass große Systeme wie GPT-3 von OpenAI im Allgemeinen weniger empfindlich auf Anweisungsverzerrungen reagieren. Aber die Forschung dient als Erinnerung daran, dass KI-Systeme wie Menschen anfällig dafür sind, Vorurteile aus Quellen zu entwickeln, die nicht immer offensichtlich sind. Die unlösbare Herausforderung besteht darin, diese Quellen zu entdecken und die nachgelagerten Auswirkungen zu mindern.
In einem weniger ernüchternden Papier kommen Wissenschaftler aus der Schweiz abgeschlossen dass Gesichtserkennungssysteme nicht leicht von realistischen KI-bearbeiteten Gesichtern getäuscht werden können. „Morphing-Angriffe“, wie sie genannt werden, umfassen die Verwendung von KI, um das Foto auf einem Personalausweis, Reisepass oder einem anderen Identitätsdokument zu verändern, um Sicherheitssysteme zu umgehen. Die Co-Autoren erstellten „Morphs“ mithilfe von KI (Nvidias StyleGAN 2) und testeten sie mit vier hochmodernen Gesichtserkennungssystemen. Die Morphs stellten trotz ihres lebensechten Aussehens keine nennenswerte Bedrohung dar, behaupteten sie.
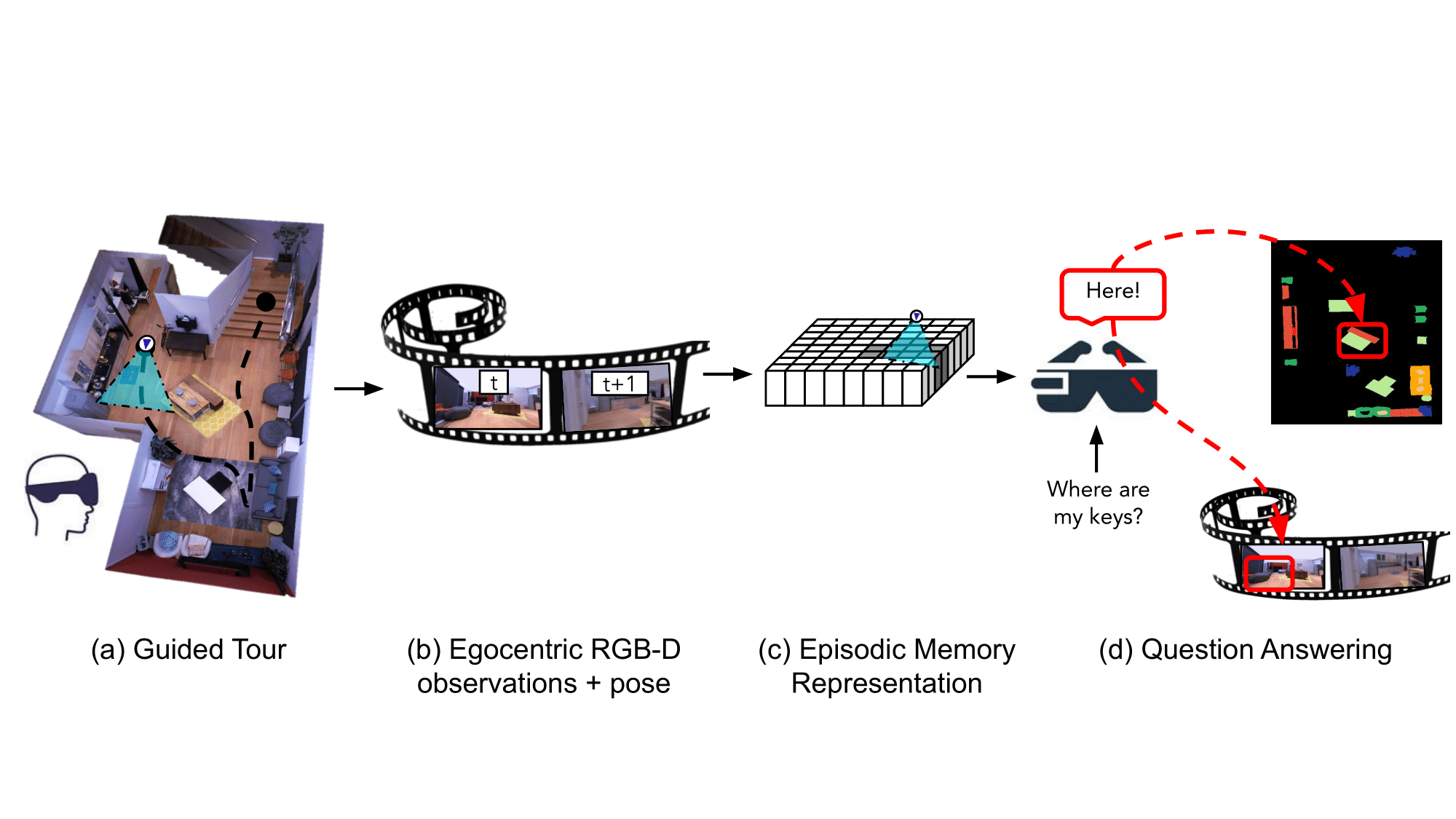
An anderer Stelle im Computer-Vision-Bereich haben Forscher von Meta einen KI-„Assistenten“ entwickelt, der sich an die Eigenschaften eines Raums erinnern kann, einschließlich des Standorts und Kontexts von Objekten, um Fragen zu beantworten. Die Arbeit ist in einem Preprint-Papier ausführlich beschrieben und wahrscheinlich ein Teil von Metas Arbeit Projekt Nazaré Initiative zur Entwicklung von Augmented-Reality-Brillen, die KI nutzen, um ihre Umgebung zu analysieren.
Bildnachweis: Meta
Das System der Forscher, das für die Verwendung auf jedem am Körper getragenen Gerät konzipiert ist, das mit einer Kamera ausgestattet ist, analysiert Filmmaterial, um „semantisch reichhaltige und effiziente Szenenerinnerungen“ zu konstruieren, die „raumzeitliche Informationen über Objekte codieren“. Das System merkt sich, wo sich Objekte befinden und wann sie im Videomaterial erschienen sind, und speichert darüber hinaus Antworten auf Fragen, die ein Benutzer zu den Objekten stellen könnte, in seinen Speicher. Beispielsweise kann das System auf die Frage „Wo haben Sie zuletzt meine Schlüssel gesehen?“ anzeigen, dass die Schlüssel an diesem Morgen auf einem Beistelltisch im Wohnzimmer lagen.
Meta, das Berichten zufolge plant, im Jahr 2024 voll funktionsfähige AR-Brillen auf den Markt zu bringen, telegrafierte seine Pläne für „egozentrische“ KI im vergangenen Oktober mit dem Start von Ego4D, einem langfristigen KI-Forschungsprojekt „egozentrische Wahrnehmung“. Das Unternehmen sagte damals, das Ziel sei es, KI-Systemen beizubringen, unter anderem soziale Hinweise zu verstehen, wie sich die Handlungen eines AR-Geräteträgers auf seine Umgebung auswirken könnten und wie Hände mit Objekten interagieren.
Von Sprache und Augmented Reality bis hin zu physikalischen Phänomenen: Ein KI-Modell hat sich in einer MIT-Studie über Wellen als nützlich erwiesen – wie sie brechen und wann. Obwohl es ein wenig geheimnisvoll erscheint, werden Wellenmodelle in Wahrheit sowohl für den Bau von Strukturen im und in der Nähe des Wassers als auch für die Modellierung der Wechselwirkung des Ozeans mit der Atmosphäre in Klimamodellen benötigt.

Bildnachweis: MIT
Normalerweise werden Wellen durch eine Reihe von Gleichungen grob simuliert, aber die Forscher trainierte ein maschinelles Lernmodell auf Hunderte von Welleninstanzen in einem 40-Fuß-Wassertank, der mit Sensoren gefüllt ist. Indem sie die Wellen beobachtete und Vorhersagen auf der Grundlage empirischer Beweise machte und diese dann mit den theoretischen Modellen verglich, half die KI dabei, aufzuzeigen, wo die Modelle zu kurz kamen.
Aus der Forschung an der EPFL, wo Thibault Asselborns Doktorarbeit zur Handschriftenanalyse entstanden ist, entsteht ein Startup wurde zu einer ausgewachsenen Lern-App. Mithilfe von Algorithmen, die er entwickelt hat, kann die App (mit dem Namen School Rebound) Gewohnheiten und Korrekturmaßnahmen identifizieren, während ein Kind in nur 30 Sekunden mit einem Stift auf einem iPad schreibt. Diese werden dem Kind in Form von Spielen präsentiert, die ihm helfen, klarer zu schreiben, indem gute Gewohnheiten gestärkt werden.
„Unser wissenschaftliches Modell und unsere Genauigkeit sind wichtig und unterscheiden uns von anderen bestehenden Anwendungen“, sagte Asselborn in einer Pressemitteilung. „Wir haben Briefe von Lehrern bekommen, die gesehen haben, wie sich ihre Schüler sprunghaft verbessert haben. Einige Schüler kommen sogar vor dem Unterricht zum Üben.“

Bildnachweis: Duke University
Eine weitere neue Erkenntnis in Grundschulen betrifft die Erkennung von Hörproblemen bei Routineuntersuchungen. Diese Screenings, an die sich einige Leser vielleicht erinnern, verwenden oft ein Gerät namens Tympanometer, das von ausgebildeten Audiologen bedient werden muss. Wenn eine nicht verfügbar ist, beispielsweise in einem abgelegenen Schulbezirk, erhalten Kinder mit Hörproblemen möglicherweise nicht rechtzeitig die Hilfe, die sie benötigen.
Samantha Robler und Susan Emmett von Duke entschieden sich für den Bau ein Tympanometer, das im Wesentlichen selbst arbeitet, indem Daten an eine Smartphone-App gesendet werden, wo sie von einem KI-Modell interpretiert werden. Alles, was besorgniserregend ist, wird gekennzeichnet und das Kind kann weiter untersucht werden. Es ist kein Ersatz für einen Experten, aber es ist viel besser als nichts und kann helfen, Hörprobleme viel früher an Orten ohne die richtigen Ressourcen zu erkennen.