

Bard, Googles bedrängter KI-gestützter Chatbot, verbessert sich langsam bei Aufgaben, bei denen es um Logik und Argumentation geht. Das geht aus einem Blogbeitrag hervor veröffentlicht heute vom Technologieriesen, was darauf hindeutet, dass Bard dank einer Technik namens „implizite Codeausführung“ nun speziell in den Bereichen Mathematik und Codierung verbessert wurde.
Wie im Blogbeitrag erläutert, handelt es sich bei großen Sprachmodellen (LLMs) wie Bard im Wesentlichen um Vorhersage-Engines. Wenn sie eine Aufforderung erhalten, generieren sie eine Antwort, indem sie vorhersehen, welche Wörter in einem Satz wahrscheinlich als nächstes kommen. Das macht sie zu außergewöhnlich guten E-Mail- und Essay-Autoren, aber auch zu etwas fehleranfälligen Softwareentwicklern.
Aber warten Sie, könnte man sagen – was ist mit Code-generierenden Modellen wie Copilot von GitHub und CodeWhisperer von Amazon? Nun, das sind keine Allzweckgeräte. Im Gegensatz zu Bard und Konkurrenten wie ChatGPT, die mithilfe einer Vielzahl von Textbeispielen aus dem Internet, E-Books und anderen Ressourcen trainiert wurden, wurden Copilot, CodeWhisperer und vergleichbare Code-Generierungsmodelle fast ausschließlich anhand von Code trainiert und verfeinert Proben.
Motiviert, die Codierungs- und Mathematikmängel in allgemeinen LLMs zu beheben, entwickelte Google die implizite Codeausführung, die es Bard ermöglicht, zu schreiben und ausführen einen eigenen Code. Die neueste Version von Bard identifiziert Eingabeaufforderungen, die von logischem Code profitieren könnten, schreibt den Code „unter die Haube“, testet ihn und generiert anhand des Ergebnisses eine angeblich genauere Antwort.
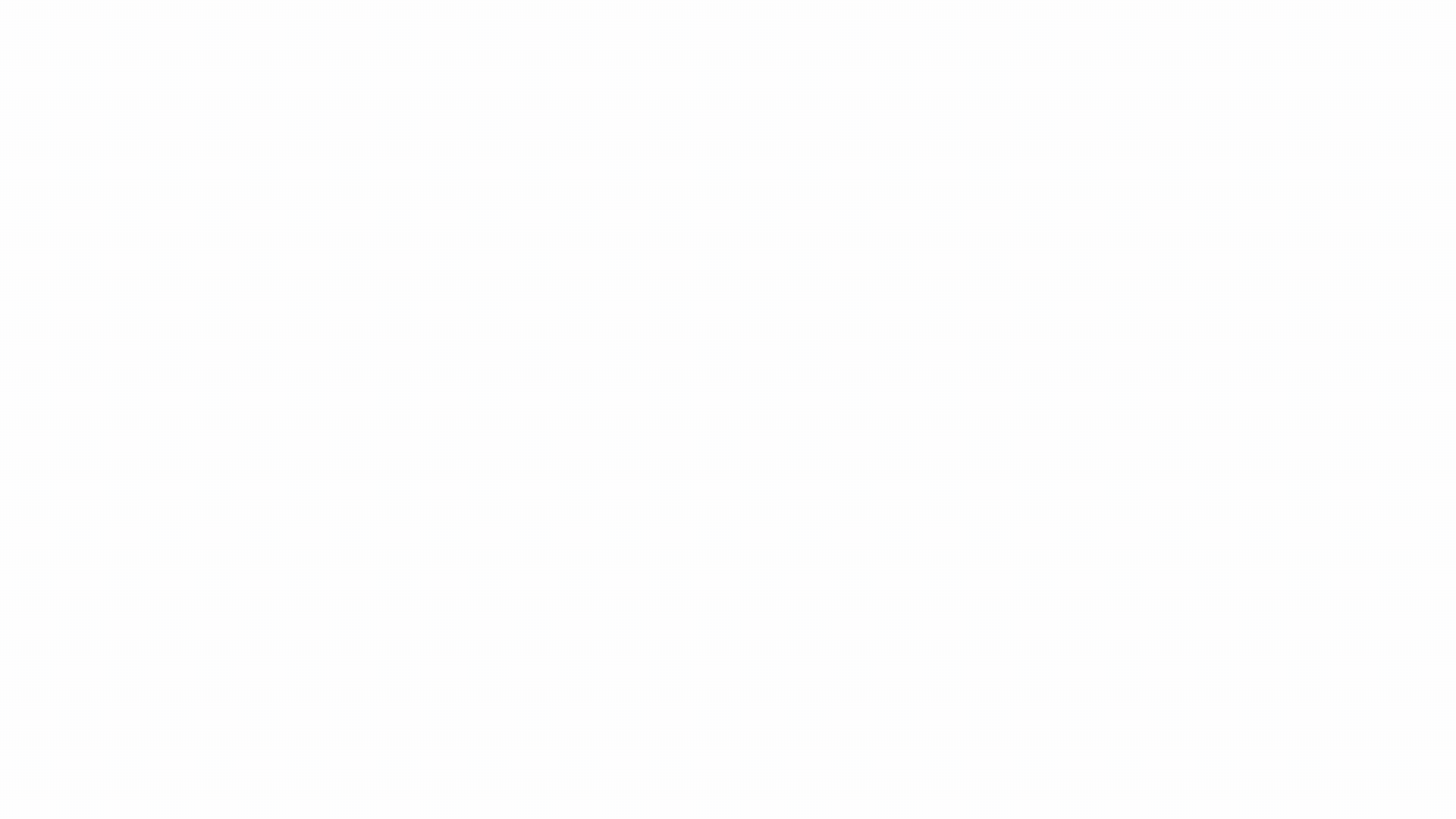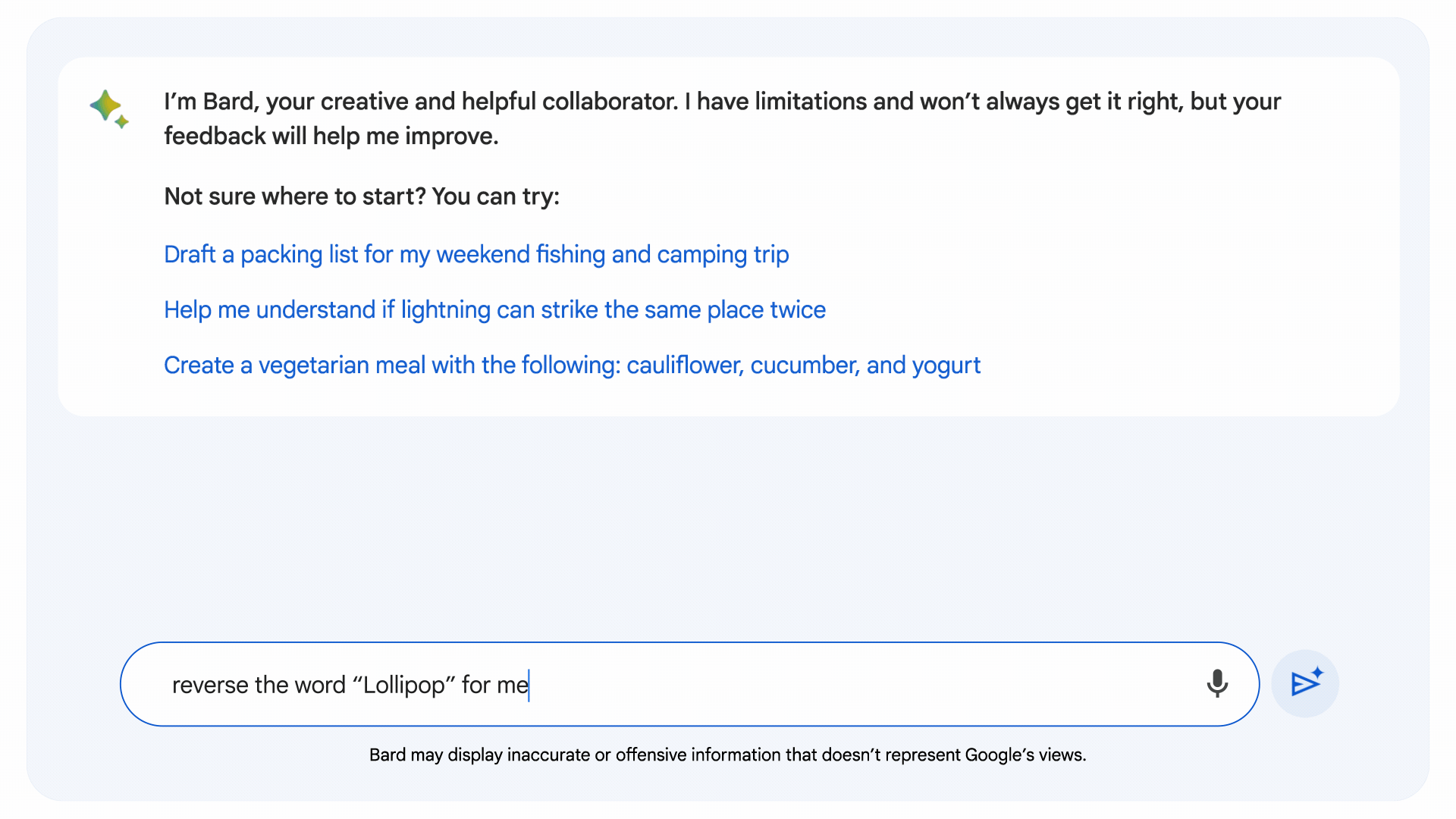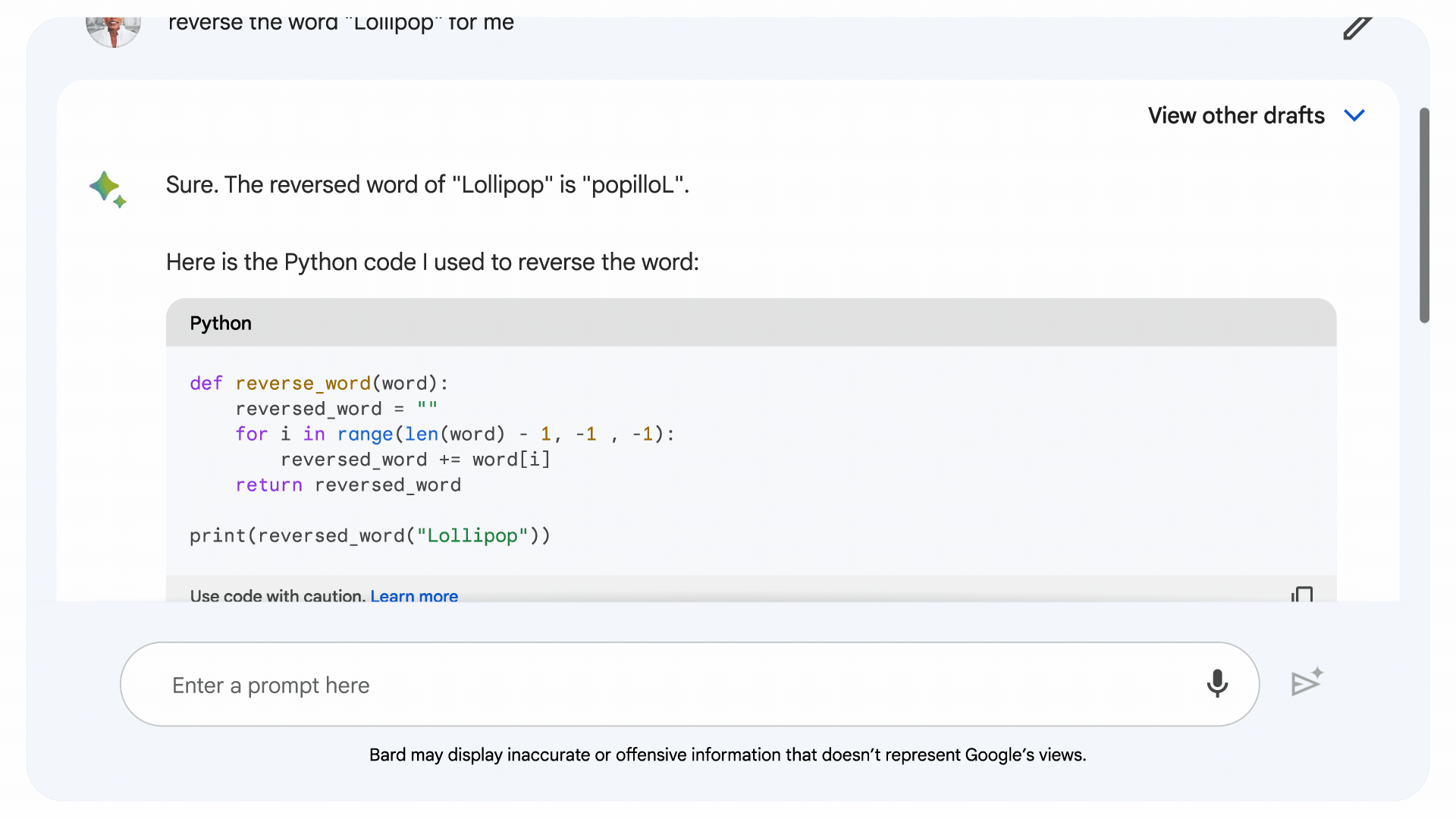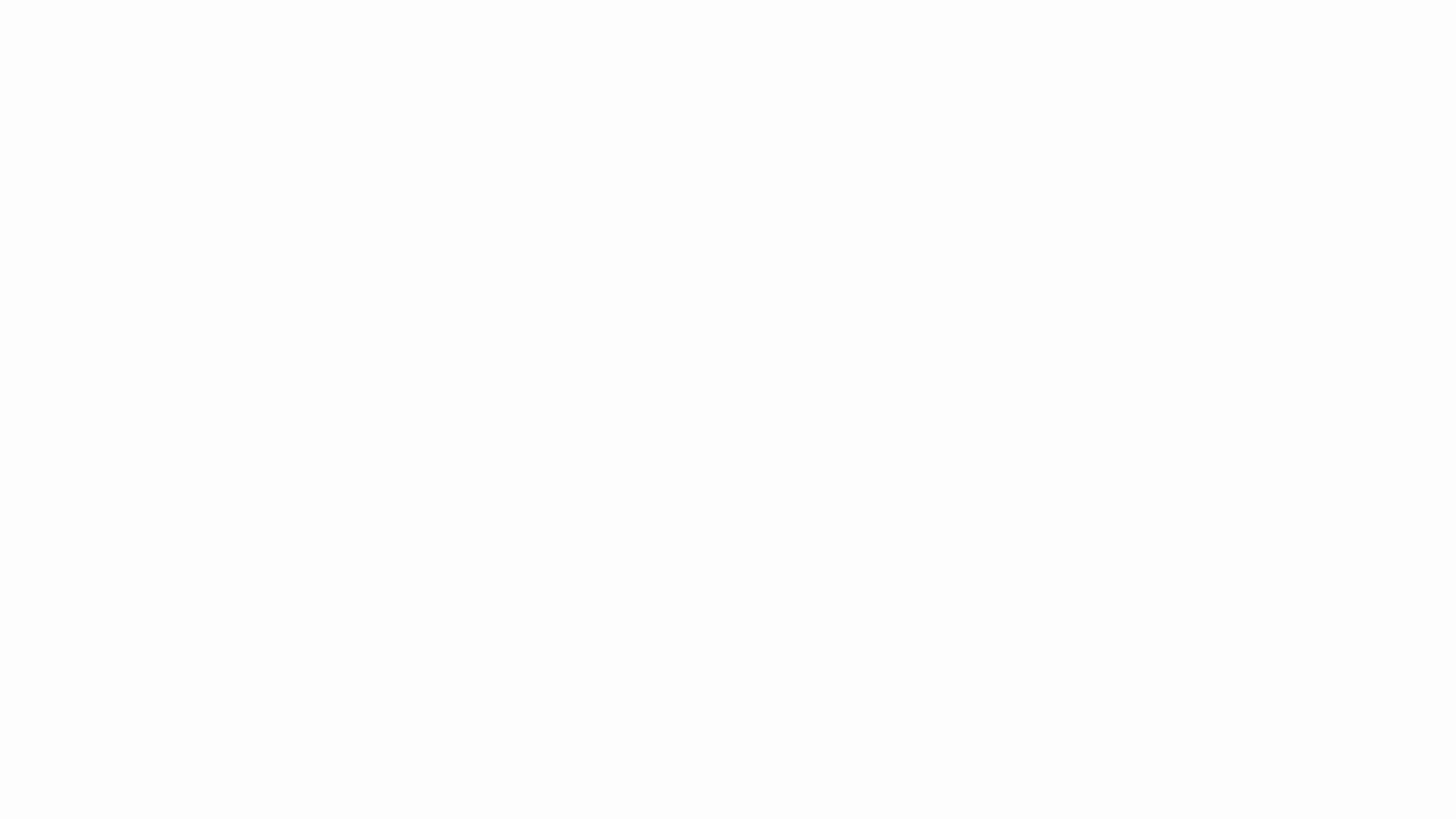
Bildnachweis: Google
Basierend auf internem Benchmarking gibt Google an, dass die Antworten des neuen Bard auf „berechnungsbasierte“ Wort- und Mathematikaufgaben im Vergleich zur vorherigen Bard-Version um 30 % verbessert wurden. Natürlich müssen wir sehen, ob diese Behauptungen externen Tests standhalten.
„Selbst mit diesen Verbesserungen wird Bard nicht immer alles richtig machen – zum Beispiel generiert Bard möglicherweise keinen Code, der die schnelle Antwort unterstützt, der generierte Code ist möglicherweise falsch oder Bard bezieht den ausgeführten Code möglicherweise nicht in seine Antwort ein“, sagt Bard Produktleiter Jack Krawczyk und Vizepräsident für Technik Amarnag Subramanya schrieben in dem Blogbeitrag. „Trotz allem ist diese verbesserte Fähigkeit, mit strukturierten, logikgesteuerten Fähigkeiten zu reagieren, ein wichtiger Schritt, um Bard noch hilfreicher zu machen.“
Als Google startete Barde Anfang des Jahres schnitt es im Vergleich zu Unternehmen wie Bing Chat und ChatGPT nicht besonders gut ab. Tatsächlich verlief der Rollout eher katastrophal, da eine Google-Anzeige eine falsche Antwort von Bard enthielt, wodurch die Aktien des Unternehmens kurzzeitig um 8 % sanken.
Berichten zufolgeMehrere Google-Mitarbeiter, die Bard vor seiner Veröffentlichung getestet hatten, äußerten ernsthafte Bedenken gegenüber dem Suchriesen. Eine Person nannte es einen „pathologischen Lügner“ und eine andere hielt es für „schlimmer als nutzlos“.
Mit impliziter Codegenerierung und anderen Verbesserungen, wie der Unterstützung neuer Sprachen, multimodalen Abfragen und Bildgenerierung, reagiert Google auf Kritik – und versucht, die Situation zu ändern.
Ob es jedoch ausreicht, um mit den führenden generativen KI-Chatbots auf diesem Gebiet mitzuhalten, bleibt abzuwarten. Vor kurzem hat Anthropic ein KI-Chatbot-Modell mit einem stark erweiterten „Kontextfenster“ eingeführt, das es dem Modell ermöglicht, relativ kohärent über Stunden oder sogar Tage statt nur über Minuten zu kommunizieren. Und OpenAI, der Entwickler hinter ChatGPT, hat damit begonnen, Plugins zu unterstützen, die ChatGPT mit externen Kenntnissen und Fähigkeiten aufwerten.