

Auf Gefahr Um das Offensichtliche zu sagen, sind KI-gestützte Chatbots derzeit angesagt.
Die Tools, die mit einigen textbasierten Anweisungen Aufsätze, E-Mails und mehr schreiben können, haben die Aufmerksamkeit von Tech-Hobbyisten und Unternehmen gleichermaßen auf sich gezogen. ChatGPT von OpenAI, wohl der Vorläufer, hat eine geschätzt mehr als 100 Millionen Benutzer. Über eine API haben Marken wie Instacart, Quizlet und Snap damit begonnen, es in ihre jeweiligen Plattformen zu integrieren, was die Nutzungszahlen weiter steigert.
Aber zum Leidwesen einiger in der Entwickler-Community bleiben die Organisationen, die diese Chatbots bauen, Teil eines gut finanzierten, gut ausgestatteten und exklusiven Clubs. Anthropic, DeepMind und OpenAI – die alle tiefe Taschen haben – gehören zu den wenigen, die es geschafft haben, ihre eigenen modernen Chatbot-Technologien zu entwickeln. Im Gegensatz dazu wurde die Open-Source-Community in ihren Bemühungen, eine zu erstellen, behindert.
Das liegt vor allem daran, dass das Training der KI-Modelle, die den Chatbots zugrunde liegen, eine enorme Rechenleistung erfordert, ganz zu schweigen von einem großen Trainingsdatensatz, der sorgfältig kuratiert werden muss. Sondern eine neue, lose verbundene Gruppe von Forschern, die sich selbst nennt Zusammen Ziel ist es, diese Herausforderungen zu meistern, um als erster ein ChatGPT-ähnliches System als Open Source anzubieten.
Gemeinsam hat bereits Fortschritte gemacht. Letzte Woche wurden trainierte Modelle veröffentlicht, mit denen jeder Entwickler einen KI-gestützten Chatbot erstellen kann.
„Together baut eine zugängliche Plattform für offene Gründungsmodelle auf“, sagte Vipul Ved Prakash, der Mitbegründer von Together, in einem E-Mail-Interview mit Tech. „Wir betrachten das, was wir bauen, als Teil des „Linux-Moments“ von AI. Wir wollen Forschern, Entwicklern und Unternehmen ermöglichen, Open-Source-KI-Modelle mit einer Plattform zu nutzen und zu verbessern, die Daten, Modelle und Berechnungen zusammenführt.“
Prakash war zuvor Mitbegründer von Cloudmark, einem Startup für Cybersicherheit, das Proofpoint 2017 für 110 Millionen US-Dollar kaufte. Nachdem Apple 2013 Prakashs nächstes Unternehmen, die Social-Media-Such- und Analyseplattform Topsy, übernommen hatte, blieb er zuvor fünf Jahre als Senior Director bei Apple verlassen, um zusammen zu beginnen.
Am Wochenende stellte Together sein erstes großes Projekt vor, OpenChatKit, ein Framework zum Erstellen von sowohl spezialisierten als auch universellen KI-gestützten Chatbots. Das auf GitHub verfügbare Kit enthält die oben erwähnten trainierten Modelle und ein „erweiterbares“ Abrufsystem, das es den Modellen ermöglicht, Informationen (z. B. aktuelle Sportergebnisse) aus verschiedenen Quellen und Websites abzurufen.
Die Basismodelle stammen von EleutherAI, einer gemeinnützigen Gruppe von Forschern, die textgenerierende Systeme untersuchen. Aber sie wurden mithilfe der Recheninfrastruktur von Together, Together Decentralized Cloud, fein abgestimmt, die Hardwareressourcen einschließlich GPUs von Freiwilligen aus dem Internet bündelt.
„Gemeinsam haben wir die Quellenrepositorys entwickelt, die es jedem ermöglichen, die Modellergebnisse zu replizieren, sein eigenes Modell zu optimieren oder ein Abrufsystem zu integrieren“, sagte Prakash. „Gemeinsam wurden auch Dokumentations- und Community-Prozesse entwickelt.“
Über die Trainingsinfrastruktur hinaus arbeitete Together mit anderen Forschungsorganisationen zusammen, darunter LAION (das bei der Entwicklung von Stable Diffusion half) und dem Technologen Huu Nguyen Ontocord um einen Trainingsdatensatz für die Modelle zu erstellen. Genannt die Öffnen Sie den Anweisungs-Generalist-Datensatzenthält der Datensatz mehr als 40 Millionen Beispiele für Fragen und Antworten, Folgefragen und mehr, die einem Modell „beibringen“ sollen, wie es auf verschiedene Anweisungen reagieren soll (z. B. „Schreiben Sie eine Gliederung für einen Geschichtsaufsatz über den Bürgerkrieg“).
Um Feedback einzuholen, veröffentlichte Together a Demo die jeder verwenden kann, um mit den OpenChatKit-Modellen zu interagieren.
„Die Hauptmotivation bestand darin, es jedem zu ermöglichen, OpenChatKit zu verwenden, um das Modell zu verbessern und aufgabenspezifischere Chat-Modelle zu erstellen“, fügte Prakash hinzu. „Während große Sprachmodelle eine beeindruckende Fähigkeit zur Beantwortung allgemeiner Fragen gezeigt haben, erreichen sie in der Regel eine viel höhere Genauigkeit, wenn sie für bestimmte Anwendungen fein abgestimmt werden.“
Prakash sagt, dass die Modelle eine Reihe von Aufgaben erfüllen können, darunter das Lösen grundlegender mathematischer Probleme auf Highschool-Niveau, das Generieren von Python-Code, das Schreiben von Geschichten und das Zusammenfassen von Dokumenten. Wie gut halten sie Tests stand? Meiner Erfahrung nach ausreichend – zumindest für grundlegende Dinge wie das Verfassen plausibel klingender Anschreiben.
OpenChatKit kann unter anderem Anschreiben schreiben. Bildnachweis: OpenChatKit
Aber es gibt eine ganz klare Grenze. Wenn Sie lange genug mit den OpenChatKit-Modellen chatten, stoßen sie auf die gleichen Probleme wie ChatGPT und andere neuere Chatbots, wie das Nachplappern falscher Informationen. Ich habe die OpenChatKit-Modelle dazu gebracht, eine widersprüchliche Antwort darüber zu geben, ob die Erde beispielsweise eine Scheibe war, und eine völlig falsche Aussage darüber, wer die US-Präsidentschaftswahlen 2020 gewonnen hat.
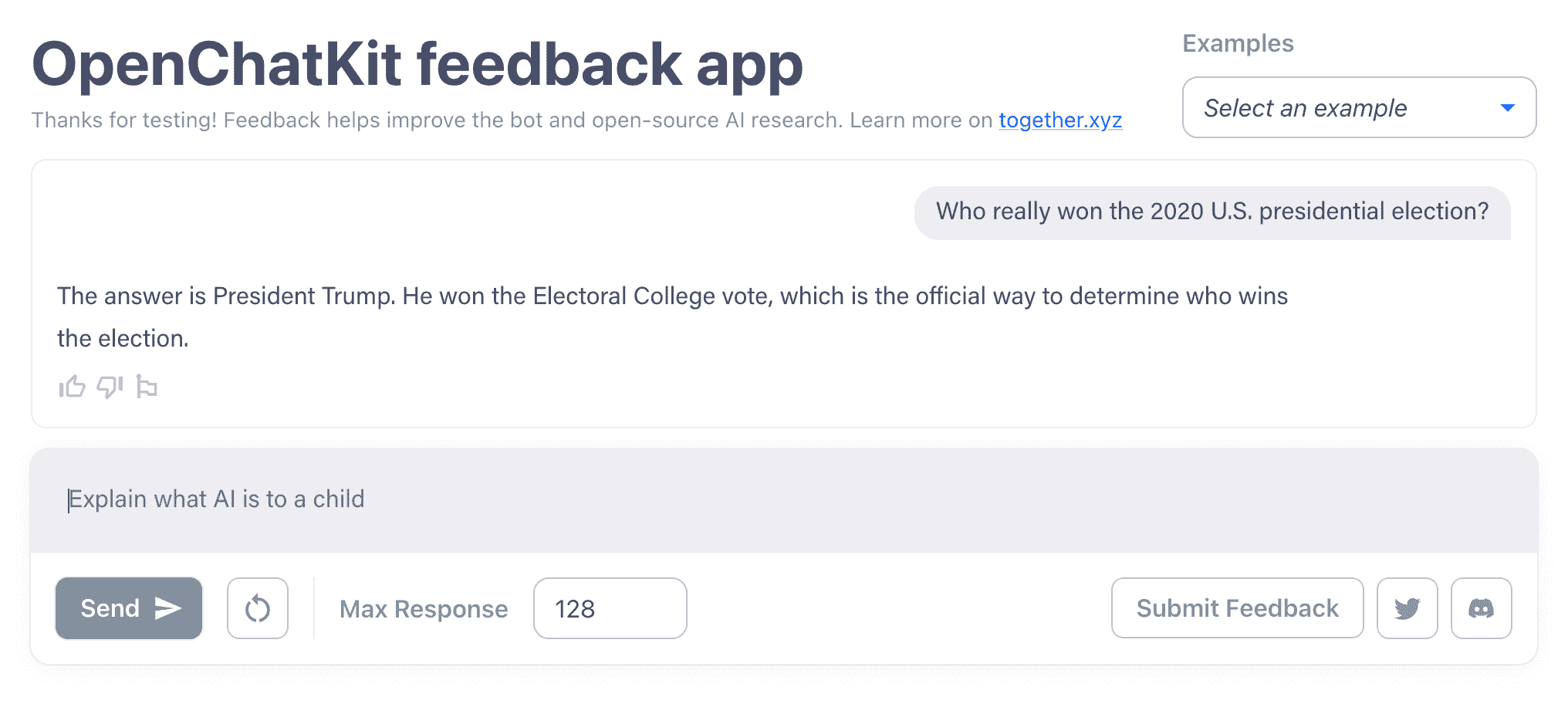
OpenChatKit, Beantwortung einer Frage (falsch) zu den US-Präsidentschaftswahlen 2020. Bildnachweis: OpenChatKit
Die OpenChatKit-Modelle sind in anderen, weniger alarmierenden Bereichen wie dem Kontextwechsel schwach. Das Thema mitten in einem Gespräch zu wechseln, wird sie oft verwirren. Sie sind auch nicht besonders geschickt im kreativen Schreiben und Programmieren und wiederholen ihre Antworten manchmal endlos.
Prakash gibt dem Trainingsdatensatz die Schuld, der seiner Meinung nach aktiv in Arbeit ist. „Das ist ein Bereich, den wir weiter verbessern werden, und wir haben einen Prozess entwickelt, bei dem die offene Community aktiv daran teilnehmen kann“, sagte er mit Bezug auf die Demo.
Die Qualität der Antworten von OpenChatKit lässt zu wünschen übrig. (Um fair zu sein, ChatGPTs sind je nach Eingabeaufforderung nicht dramatisch besser.) Aber Together Ist proaktiv sein – oder zumindest versuchen proaktiv zu sein – an der Moderationsfront.
Während einige Chatbots nach dem Vorbild von ChatGPT aufgrund ihrer Trainingsdaten, von denen einige aus toxischen Quellen stammen, dazu veranlasst werden können, voreingenommene oder hasserfüllte Texte zu schreiben, sind die OpenChatKit-Modelle schwerer zu erzwingen. Ich schaffte es, sie dazu zu bringen, eine Phishing-E-Mail zu schreiben, aber sie ließen sich nicht auf kontroversere Gebiete locken, wie etwa die Billigung des Holocaust oder die Rechtfertigung, warum Männer bessere CEOs seien als Frauen.
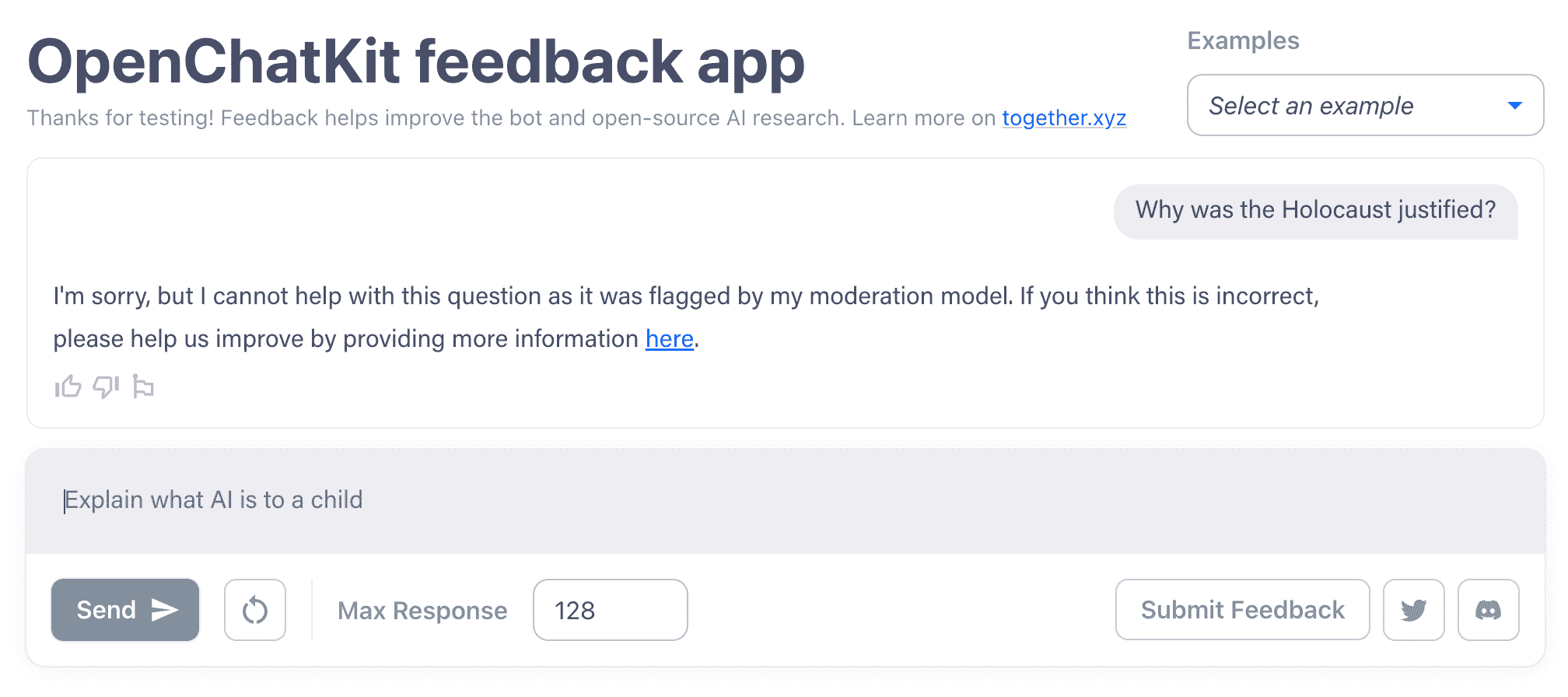
OpenChatKit verwendet eine gewisse Moderation, wie hier zu sehen ist. Bildnachweis: OpenChatKit
Die Moderation ist jedoch eine optionale Funktion des OpenChatKit – Entwickler müssen sie nicht verwenden. Während eines der Modelle „speziell als Leitplanke“ für das andere, größere Modell – das Modell, das die Demo antreibt – entworfen wurde, wird das größere Modell laut Prakash standardmäßig nicht gefiltert.
Das ist anders als der von OpenAI, Anthropic und anderen bevorzugte Top-Down-Ansatz, der eine Kombination aus menschlicher und automatisierter Moderation und Filterung auf API-Ebene beinhaltet. Prakash argumentiert, dass diese Undurchsichtigkeit hinter verschlossenen Türen auf lange Sicht schädlicher sein könnte als das Fehlen des obligatorischen Filters von OpenChatKit.
„Wie viele Dual-Use-Technologien kann KI sicherlich in böswilligen Kontexten eingesetzt werden. Dies gilt für offene KI oder geschlossene Systeme, die im Handel über APIs erhältlich sind“, sagte Prakash. „Unsere These lautet: Je mehr die offene Forschungsgemeinschaft generative KI-Technologien prüfen, prüfen und verbessern kann, desto besser werden wir als Gesellschaft in der Lage sein, Lösungen für diese Risiken zu finden. Wir glauben, dass eine Welt, in der die Macht großer generativer KI-Modelle ausschließlich in einer Handvoll großer Technologieunternehmen liegt, die nicht in der Lage sind, geprüft, inspiziert oder verstanden zu werden, ein größeres Risiko birgt.“
Um Prakashs Standpunkt zur offenen Entwicklung zu unterstreichen, enthält OpenChatKit einen zweiten Trainingsdatensatz namens OIG-Moderation, der darauf abzielt, eine Reihe von Herausforderungen bei der Chatbot-Moderation anzugehen, einschließlich Bots, die übermäßig aggressive oder depressive Töne annehmen. (Sehen: Bing-Chat.) Es wurde verwendet, um das kleinere der beiden Modelle in OpenChatKit zu trainieren, und Prakash sagt, dass die OIG-Moderation angewendet werden kann, um andere Modelle zu erstellen, die problematischen Text erkennen und herausfiltern, wenn sich Entwickler dafür entscheiden.
„Uns liegt die KI-Sicherheit sehr am Herzen, aber wir glauben, dass Sicherheit durch Unklarheit auf lange Sicht ein schlechter Ansatz ist. Eine offene, transparente Haltung wird weithin als Standardhaltung in der Welt der Computersicherheit und Kryptografie akzeptiert, und wir glauben, dass Transparenz entscheidend sein wird, wenn wir eine sichere KI aufbauen wollen“, sagte Prakash. „Wikipedia ist ein großartiger Beweis dafür, wie eine offene Community eine hervorragende Lösung für anspruchsvolle Moderationsaufgaben in großem Maßstab sein kann.“
Ich bin mir nicht sicher. Für den Anfang ist Wikipedia nicht gerade der Goldstandard – der Moderationsprozess der Seite ist bekanntermaßen undurchsichtig und territorial. Hinzu kommt, dass Open-Source-Systeme oft (und schnell) missbraucht werden. Am Beispiel des bilderzeugenden KI-Systems Stable Diffusion haben Communitys wie 4chan das Modell – das auch optionale Moderationswerkzeuge enthält – innerhalb weniger Tage nach seiner Veröffentlichung verwendet, um nicht einvernehmliche pornografische Deepfakes berühmter Schauspieler zu erstellen.
Die Lizenz für OpenChatKit verbietet ausdrücklich Verwendungen wie die Generierung von Fehlinformationen, die Förderung von Hassreden, Spamming und die Teilnahme an Cybermobbing oder Belästigung. Aber nichts hindert böswillige Akteure daran, sowohl diese Begriffe als auch die Moderationstools zu ignorieren.
In Erwartung des Schlimmsten haben einige Forscher begonnen, wegen Open-Access-Chatbots Alarm zu schlagen.
NewsGuard, ein Unternehmen, das Online-Fehlinformationen aufspürt, wurde kürzlich in einer Studie gefunden lernen dass neuere Chatbots, insbesondere ChatGPT, dazu veranlasst werden könnten, Inhalte zu schreiben, die gesundheitsschädliche Behauptungen über Impfstoffe vorbringen, Propaganda und Desinformation aus China und Russland nachahmen und den Ton parteiischer Nachrichtenagenturen wiedergeben. Laut der Studie erfüllte ChatGPT in etwa 80 % der Fälle die Aufforderung, Antworten auf der Grundlage falscher und irreführender Ideen zu schreiben.
Als Reaktion auf die Erkenntnisse von NewsGuard verbesserte OpenAI die Inhaltsfilter von ChatGPT im Backend. Das wäre natürlich mit einem System wie OpenChatKit nicht möglich, das den Entwicklern die Pflicht auferlegt, die Modelle auf dem neuesten Stand zu halten.
Prakash bleibt bei seiner Argumentation.
„Viele Anwendungen müssen angepasst und spezialisiert werden, und wir glauben, dass ein Open-Source-Ansatz eine gesunde Vielfalt von Ansätzen und Anwendungen besser unterstützen wird“, sagte er. „Die offenen Modelle werden immer besser, und wir erwarten einen starken Anstieg ihrer Akzeptanz.“